AMD Unveils Instinct MI350 Series: A Powerhouse in AI Acceleration
2 Sources
2 Sources
[1]
AMD details Instinct MI350: 3D chiplet, 185B transistors, 288GB HBM3E, TSMC N3P node
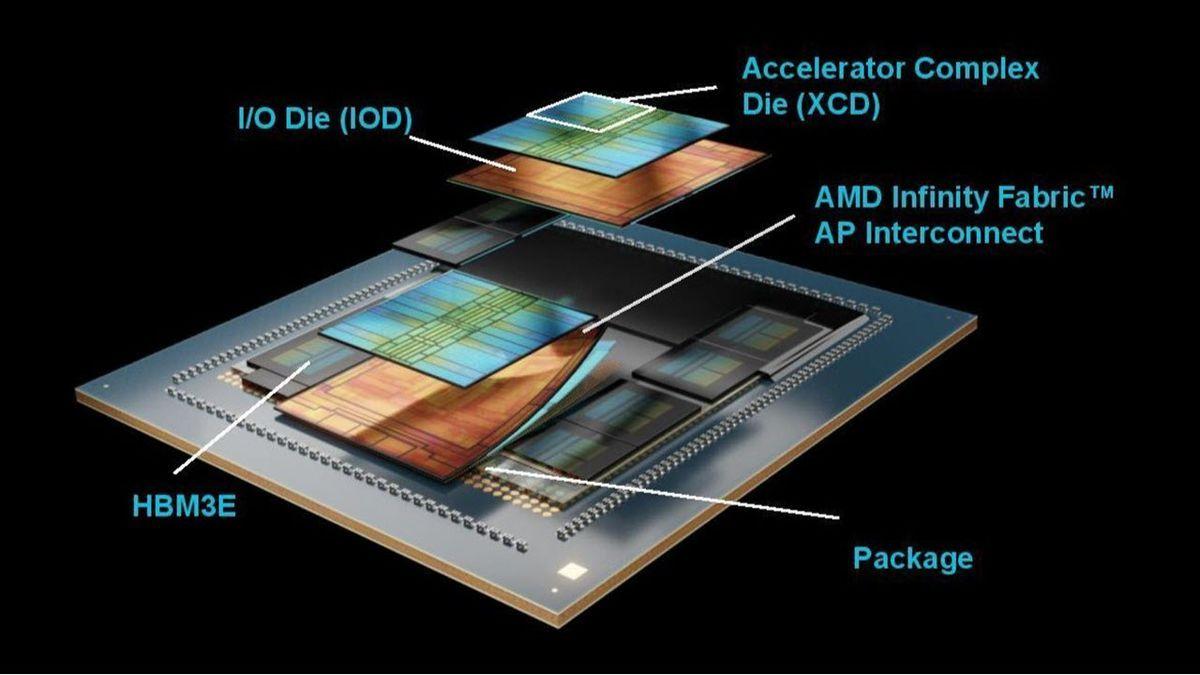
TL;DR: AMD's Instinct MI350 series AI accelerators, built on TSMC's advanced N3P process, deliver enhanced AI performance with 185 billion transistors, up to 288GB HBM3E memory, and superior power efficiency. The flagship MI355X outperforms NVIDIA's B200 in memory, bandwidth, and precision compute capabilities. AMD launched its new Instinct MI350 series AI accelerators two months ago, but the company has now detailed the MI350 chip at Hot Chips 2025, all fabbed on TSMC's bleeding-edge N3P process node. AMD's new Instinct MI350 series AI accelerators feature the CDNA 4 architecture, bringing improved performance and efficiency for AI workloads, as well as support for larger capacities of VRAM and capacity at higher speeds, faster AI training and inference on large models with boosted link speed, and improved power efficiency and performance. The new flagship Instinct MI355X AI accelerator is liquid-cooled with up to 1400W of power, with its GPU running at 2400MHz, with up to 288GB of HBM3E memory. AMD has been engineering some mighty fine chips in the last few years, with the new MI350 no different as it uses the best of what TSMC has to offer in its N3P process node and its advanced packaging technologies. MI350 features a huge 185 billion transistors, using a 3D Multi-Chiplet layout with two chiplet types + HBM3E memory. AMD uses a dual 3nm + 6nm process node for MI350 on CoWoS-S advanced packaging from TSMC. The XCDs (Accelerator Complex Dies) are based on TSMC's N3P (3nm + performance) process technology, with 8 of them in total on a single MI350X/MI355X package, and 4 each on the IOD. The IOD (AMD I/O Base Die) is fabbed on TSMC N6 (N6 process), and is very cost-effective thanks to it being a mature, tested process node which is great for yields and price. AMD uses two of them in the XCD, with the IOD packing the Infinity Fabric AP interconnect. The MI350 IOD houses the HBM3E memory, with 8 physical stacks on a 128-bit channel interface, with up to 288GB of HBM3E in total (36GB per 12-Hi stack at 8Gbps) and a total of 8TB/sec total bandwidth. These two dies are linked up through Infinity Fabric supporting full bandwidth and flat address space to all of the chiplets using Infinity Fabric Advanced Package (AP) with 5.5TB/sec of bi-directional bandwidth. AMD is using 256MB of Infinity Cache here, with the 2 IODs providing enhanced power efficiency when compared to the MI300, with wider data pipelines enabling higher bandwidth, but at lower frequencies. Another cool thing that AMD is doing with its new Instinct MI350 series AI accelerators is that it supports flexible GPU positioning per socket, with the memory partitioned into two separate clusters. AMD can use this flexibility to the GPUs or XCDs, separating the quad XCD cluster or separating them into dual, or single blocks, with the MI350 series chips supporting up to 8 instances of 70B models in CPX+NPS2 AI workloads. This culminates in the Instinct MI355X AI accelerator beating the GB200 and B200 AI GPUs from NVIDIA, here's how it compares: AMD Instinct MI355X vs NVIDIA B200: * Memory: 1.6x Higher * Bandwidth: 1.0x Higher * FP64: 2.1x Higher * FP16: 1.1x Higher * FP8: 1.1x Higher * FP6: 2.2x Higher * FP4: 1.1x Higher AMD Instinct MI355X vs NVIDIA B200:
[2]
AMD's Instinct MI350 GPU Is A AI-Hardware Powerhouse: 3nm 3D Chiplet Based on CDNA 4, 185 Billion Transistors, 1400W TBP, Over 4000B LLM Support With Massive 288GB Memory
AMD's Instinct MI350 AI accelerator, featuring the CDNA 4 architecture, has been fully detailed, with its speeds and feeds, at Hot Chips 2025. AMD Opens Up The Lid of Instinct MI350 Architectural Details, Products, & Solutions At Hot Chips 2025, Ready For Massive LLMs It's been only two months since AMD launched its Instinct MI350 series, the flagship Accelerator and CDNA 4-based GPU for AI workloads. Today at Hot Chips, they went further into the details of this AI powerhouse. So, starting off with what kicked off the development of the MI350 series, well, AI obviously, but to be more precise, it was the LLM growth trajectory as model sizes were getting larger each year. Two key factors to address these were to innovate on the data type format front, and another was to simply go bigger on the memory scale on chips. AMD implemented both and a lot more. As a result, the CDNA-4-based AMD Instinct MI350 series accelerators improve performance and efficiency in doing AI workloads. They extended the HBM bandwidth and capacity, supporting faster AI training and inference on larger models with increased link speeds, and also enhanced power efficiency and performance. The faster performance is achieved by reducing un-core power, enabling a wider infinity fabric for higher bandwidth at more power-efficient frequencies, and supporting lower precision data formats such as full-access FP8, and industry-standard micro-scaled MXFP6 and MXFP4 data types. AMD offers its MI350 series in two flavors, the MI350X, which is the air-cooled variant with a 1000W TBP and a max clock speed of 2.2 GHz, while the higher-end MI355X is aimed at liquid-cooled datacenters with a max TBP of 1400W and a max clock speed of 2.4 GHz. The chip is an architectural masterpiece from AMD, utilizing its years of engineering expertise in the chiplet domain, while utilizing the prowess of its partners for advanced packaging. The chip itself has a total of 185 billion transistors and adopts a 3D Multi-Chiplet layout with two chiplet types, along with HBM3e memory. A dual 3nm + 6nm process technology was leveraged for the MI350 series on the proven COWOS-S packaging technology. Breaking down the chip, we first have the XCDs or Accelerator Complex Dies, which are based on TSMC's N3P "3nm" process technology. There are 8 of these on a single MI350X/MI355X package and 4 each on an IOD. The IOD or AMD I/O Base Die is based on TSMC's 6nm FinFET "N6" process technology and is a very cost-effective die thanks to its mature process node, which is optimal in terms of yields and costs. There are two of these per package. The IOD houses the Infinity Fabric AP interconnect. There are a total of 8 HBM3E sites on the package, with each IOD connected to 4 sites. And lastly, there's the main interposer or package on which the entire silicon sits. Diving deeper into the IO die, there are two of these, each with three Infinity Fabric Links and a PCIe Gen5 link to an AMD EPYC Host (128 GB/s). There are four HBM3E memory controllers, each connected to a 12-Hi stack comprised of 36 GB capacities operating at 8 Gbps for up to 8.0 TB/s of bandwidth. There's 288 GB of HBM3e capacity onboard the package. Both IO dies are connected using an Infinity Fabric (Advanced Package) interconnect, which offers 5.5 TB/s of bisection bandwidth. There's also 256 MB of AMD Infinity Cache onboard the IO Dies. The Infinity Fabric Links are based on 4th Gen inter-socket links and offer 1075 GB/s bi-directional aggregate bandwidth to the XCDs. The MI350 series chips pack a total of 32 AMD CDNA 4 compute units per XCD or 256 compute units in total with 128 stream processors per CU for a total of 16,384 cores. These are lower cores than the MI325 and MI300 series, which came packed with 304 compute units and a max core count of 19,456. These compute units are adjusted into eight zones, each with its own XCD, with each XCD packing 32 compute units. There are also 1024 Matrix Cores, and the core can hit a maximum clock speed of 2.4 GHz on the MI355X-class solutions. The internal memory subsystem onboard the XCD includes 129 KiB of VGPR / SIMD, 512 KiB of Vector Registers/CU, 160 KiB of LDS/CU (537 GB/s), 32 KiB of L1 cache per CU, and 4 MiB of shared L2 cache per XCD. That gives us: * 131 MB Vector Registers (Full Chip) * 40 MB LDS (Full Chip) * 8 MB L1 (Full Chip) * 32 MB L2 (Full Chip) * 256 MB Infinity Cache (Full Chip) Moving down, AMD is sharing the data format and compute performance speedups of its MI355X versus MI300X: * Vector FP16: 157.3 TFLOPs (1.0x) * Matrix FP16/BF16: 2.5 PFLOPs (1.9x) * Matrix FP8: 5.0 PFLOPs (1.9x) * Matrix INT8/INT4: 5.0 PFLOPs (1.9x) * Matrix MXFP6/MXFP4: 10 PFLOPs (New) * Vector FP64: 78.6 TFLOPs (1.0x) * Matrix FP64: 78.6 TFLOPs (0.5x) * Vector FP32: 157.3 TFLOPs (1.0x) * Matrix FP32: 157.3 TFLOPs (1.0x) Compared to NVIDIA's GB200 SXM systems, the MI355X OAM solution offers a 2.1x higher compute output in AI and HPC performance. You can see the SoC block diagram of the Instinct MI350 series GPU below: The AMD Instinct MI350 series AI accelerators also support flexible GPU partitioning per socket, where the memory can be partitioned into two separate clusters. This flexibility also applies to the GPUs or XCDs, where you can separate the quad XCD cluster or separate them into dual or singular blocks, allowing the chip to support 8 instances of 70B models in CPX+NPS2. The Infinity Fabric connectivity also enables 8 accelerators to communicate with a bi-directional link of 154 GB/s, a 20% speedup versus the prior generation. AMD also talks a bit about the assembly of each chip, from 3D packaging of the silicon to the package assembly, to OAM assembly, and the final heatsink attach phase. These OAMs then go into massive UBBs (2.0), which are universal base boards that house up to 8 accelerators. These go into an industry-standard host node, which ends up in a datacenter-ready EIA rack. Just talking about the AI compute uplift, AMD claims that the Instinct MI350 series offers 20 PFLOPs of FP4/FP6 compute, which is a 4x gen-on-gen performance uplift. With HBM3e, you get faster data transfer speeds with a super-high capacity of 288 GB on both variants. There's also 256 MB of new Infinity Cache on the chips. The 4U options can also fit into existing UBB8, which currently houses MI300X AC 750W and MI325X AC 1000W accelerators. There are two finalized systems. The MI350X platform offers up to 36.9 FP16/BF16 and 73.9 FP8 PFLOPs and scales up to 10U air-cooled solutions. The MI355X platform offers up to 40.2 FP16/BF16 and 80.5 FP8 PFLOPs and scales up to 5U DLC (Direct Liquid Cooled) solutions. Both platforms offer 2.25 TB of HBM3e memory and 1075 GB/s of Infinity Fabric Bandwidth. These solutions are equipped with AMD's latest and greatest 5th Gen EPYC CPUs with Zen 5 cores and Pensando UEC-ready NICs. The following are the numbers compared against the competition: MI355x vs B200: * Memory: 1.6x Higher * Bandwidth: 1.0x Higher * FP64: 2.1x Higher * FP16: 1.1x Higher * FP8: 1.1x Higher * FP6: 2.2x Higher * FP4: 1.1x Higher MI355x vs GB200: * Memory: 1.6x Higher * Bandwidth: 1.0x Higher * FP64: 2.0x Higher * FP16: 1.0x Higher * FP8: 1.0x Higher * FP6: 2.0x Higher * FP4: 1.0x Higher But how does Instinct MI355X compare to the last-gen MI300 series? Well, AMD just showed a massive 35x leap in Inference performance using Llama 3.1 405B (Throughput), and that's a huge increase. AMD has already confirmed that the MI350 series will be available through various partners starting in Q3 2025. The next-generation MI400 series is already in the works and is planned for launch in 2026.
Share
Share
Copy Link
AMD's Instinct MI350 series, featuring advanced 3D chiplet design and TSMC's N3P process, sets new benchmarks in AI acceleration with impressive specs and performance gains over competitors.
AMD's Technological Marvel: The Instinct MI350 Series
AMD has unveiled its latest AI accelerator series, the Instinct MI350, at Hot Chips 2025, showcasing a significant leap in AI hardware capabilities. This new series, based on the CDNA 4 architecture, is designed to meet the growing demands of large language models (LLMs) and complex AI workloads
1
2
.Advanced Architecture and Manufacturing

Source: Wccftech
The Instinct MI350 series leverages cutting-edge technology, featuring a 3D Multi-Chiplet layout with 185 billion transistors. AMD has employed a dual-process approach, utilizing TSMC's N3P (3nm) process for the Accelerator Complex Dies (XCDs) and the N6 (6nm) process for the I/O Base Die (IOD). This combination, along with TSMC's CoWoS-S advanced packaging, allows for optimal performance and cost-effectiveness
1
2
.Memory and Bandwidth Innovations
A standout feature of the MI350 series is its impressive memory capabilities. The flagship MI355X model boasts up to 288GB of HBM3E memory, with eight 12-Hi stacks each providing 36GB at 8Gbps. This configuration delivers a total bandwidth of 8TB/sec, significantly outpacing competitors
1
.The series also incorporates 256MB of AMD Infinity Cache and utilizes Infinity Fabric Advanced Package (AP) interconnect, providing 5.5TB/sec of bi-directional bandwidth between chiplets
1
.Performance and Efficiency Enhancements
AMD has made substantial improvements in both performance and efficiency:
- The MI355X can reach clock speeds of up to 2.4GHz with a 1400W TBP (Thermal Design Power) in its liquid-cooled variant
1
2
. - The series supports new data formats, including full-access FP8 and industry-standard micro-scaled MXFP6 and MXFP4, enabling faster AI training and inference
2
. - Compared to its predecessor, the MI300X, the MI355X shows significant performance gains across various data formats, including a 1.8x increase in Matrix FP16/BF16 and a 1.9x increase in Matrix FP8
2
.
Competitive Edge

Source: TweakTown
AMD claims that the Instinct MI355X outperforms NVIDIA's B200 in several key areas:
- 1.6x higher memory capacity
- 1.1x higher bandwidth
- 2.1x higher FP64 performance
- 1.1x higher FP16, FP8, and FP4 performance
- 2.2x higher FP6 performance
1
Related Stories

Flexible Configuration and Scalability
The MI350 series supports flexible GPU partitioning, allowing for various configurations of the XCDs. This flexibility enables the chip to support up to 8 instances of 70B models in CPX+NPS2 AI workloads, demonstrating its capability to handle large-scale AI tasks
1
2
.Impact on AI and HPC Landscape
With its advanced features and performance capabilities, the AMD Instinct MI350 series is poised to make a significant impact in the AI and high-performance computing (HPC) sectors. Its ability to handle larger models with improved efficiency addresses the growing demands of AI researchers and enterprises working with increasingly complex AI systems
2
.As the AI hardware race intensifies, AMD's latest offering demonstrates the company's commitment to innovation and its ability to compete at the highest levels of the AI accelerator market. The Instinct MI350 series represents a crucial step forward in enabling more powerful and efficient AI computations, potentially accelerating advancements across various AI applications and research fields.
References
Summarized by
Navi
Related Stories
AMD Unveils Next-Gen AI Accelerators: MI325X and MI355X to Challenge Nvidia's Dominance
11 Oct 2024•Technology

AMD Unveils Powerful MI350X and MI355X AI GPUs, Challenging Nvidia's Dominance
11 Jun 2025•Technology
AMD Accelerates Launch of Powerful Instinct MI350 AI GPU to Challenge Nvidia's Dominance
06 Feb 2025•Technology

Recent Highlights
1
AI chatbots validate you too much, making you less kind to others, Stanford study reveals
Science and Research

2
Anthropic's Claude Code Source Leak Reveals Hidden AI Agent Plans and Extensive System Access
Technology

3
Judge blocks Pentagon from branding Anthropic a security risk over AI safety guardrails dispute
Policy and Regulation

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.