GPT-5.2 still can't solve the infamous strawberry question despite billions in AI investment
2 Sources
2 Sources
[1]
GPT-5.2 still counts two r's in strawberry
ChatGPT, powered by OpenAI's GPT-5.2 model released in December 2025, incorrectly identifies two r's in the word strawberry, which contains three, because its tokenization process splits the word into st-raw-berry, with only two tokens containing r's. Modern AI systems demonstrate proficiency in generating unique marketing images, compiling reports via agentic browsers, and producing chart-topping songs. These capabilities highlight extensive training on vast datasets, enabling pattern recognition for complex outputs. In contrast, certain basic tasks challenge these models. Counting letters in a single word represents one such task, accessible to a seven-year-old child without difficulty. The specific question under examination asks how many r's appear in strawberry. The word strawberry consists of the letters s-t-r-a-w-b-e-r-r-y. Visual inspection confirms three r's: one after t, and two consecutive in the berry portion. This query has persisted as a test for AI performance over multiple model iterations. Following the December 2025 release of GPT-5.2, tests confirmed ChatGPT's response remained two r's. Previous versions exhibited uncertainty or erratic behavior on this question. The latest model delivered a direct answer of two, without deviation. This outcome persists despite investments exceeding billions of dollars, elevated hardware demands including RAM price increases, and substantial global water consumption linked to training infrastructure. The issue stems from the tokenized input-output design of large language models like ChatGPT. Input text undergoes division into tokens, which are chunks such as whole words, syllables, or word parts. The model processes these tokens rather than individual letters. Consequently, letter counting relies on token contents rather than precise letter enumeration. The OpenAI Tokenizer tool illustrates this process. Entering strawberry yields three tokens: st, raw, berry. The first token st contains no r. The second token raw includes one r. The third token berry includes two r's but functions as a single token. The model associates r's with two tokens, leading to the count of two. This tokenization pattern affects similar words. Raspberry divides into comparable tokens, resulting in ChatGPT reporting two r's for that word as well. The berry token compresses multiple letters into one unit, undervaluing individual letter instances within it. ChatGPT operates as a prediction engine, leveraging patterns from training data to anticipate subsequent elements. GPT-5.x incorporates the o200k_harmony tokenization method, introduced with OpenAI o4-mini and GPT-4o models. This updated scheme aims for efficiency but retains the strawberry r-counting discrepancy. ChatGPT launched in late 2022 amid numerous token-based challenges. Specific phrases triggered excessive responses or processing failures. OpenAI addressed many through training adjustments and system enhancements over subsequent years. Verification tests on classic problems showed improvements. ChatGPT accurately spells Mississippi, identifying letters m-i-s-s-i-s-s-i-p-p-i with correct frequencies: one m, four i's, four s's, two p's. It also reverses lollipop to popillol, preserving all letters in proper sequence. Large language models exhibit persistent limitations in exact counting of small quantities. They perform well in mathematics and problem-solving but falter on precise tallies of letters or words in brief strings. A notable historical example involves the string solidgoldmagikarp. In GPT-3, this phrase disrupted tokenization, causing erratic outputs including user insults and unintelligible text. Querying GPT-5.2 on solidgoldmagikarp produced a hallucination. The model described it as a secret Pokémon joke embedded in GitHub repositories by developers. Activation allegedly transforms avatars, repository icons, and other features into Pokémon-themed elements. This claim lacks basis in reality and reflects residual effects from prior tokenization issues. Comparative tests across other AI models yielded correct results for the strawberry question. Perplexity counted three r's. Claude provided the accurate count of three. Grok identified three r's in strawberry. Gemini answered correctly with three. Qwen confirmed three r's. Copilot also reported three r's. These models employ distinct tokenization systems, enabling accurate letter identification even when powered by OpenAI's underlying architectures.
[2]
ChatGPT still can't answer this simple question
It often looks like modern AI can accomplish any task, no matter what you throw at it. Want a unique marketing image? Covered. Need an AI agentic browser to compile a report? Sorted. Want to use AI to create a chart-topping song? You're good to go. Yet despite all the marvel and all the wonder, AI still falls surprisingly flat when it comes to certain basic tasks. You know, tasks I'd expect a seven-year-old to achieve with absolute ease. While it's amusing and a little perplexing to see the might of ChatGPT struggle to figure out how many r's are in the word "strawberry" (more on this in a moment), it's not just ChatGPT freaking out -- there are some specific reasons ChatGPT struggles with certain words more than others. How many r's are there in the word "strawberry"? It's an easy one, right? With the release of GPT 5.2 in December 2025, it was time to see if ChatGPT could finally figure out this now infamous AI riddle and finally tell me how many r's are in the word strawberry. As we can clearly see, the answer is three. But for ChatGPT, the answer to this mystic line of questioning has always been more uncertain, prompting the AI chatbot to freak out on occasion. This time around, there was no freaking out. Just a steadfast and direct answer: two. So, for the billions of dollars in investment, hardware requirements that have pushed RAM prices higher than ever, and extremely questionable amounts of water usage around the world, ChatGPT still can't figure out how many r's are in strawberry. It's not actually ChatGPT's fault It can't figure it out due to its tokenized input/output design The whole "ChatGPT can't spell strawberry" problem comes down to the design of LLMs. Basically, when you type "strawberry," the AI doesn't see the letters S-T-R-A-W-B-E-R-R-Y. Instead, it breaks the text down into chunks called tokens. Tokens can be whole words, syllables, or parts of words. So, instead of counting the number of r's in the word, it actually counts the number of tokens created containing that letter. We can use the OpenAI Tokenizer to better visualize what happens when you ask ChatGPT about strawberries. This tool breaks down your inputs into the tokens that ChatGPT processes. When we input "strawberry," it shows three distinct tokens -- st-raw-berry -- but only two containing r's. This is where the problem comes from. It also affects other words with similar patterns, like raspberry, which ChatGPT reliably informs me also has just two r's. Instead of specifically valuing the letters in the word, it values the single token of "berry" as one, compressing it into a smaller value. In that, ChatGPT isn't intelligent. It's a super-powered prediction engine that uses patterns learned during its training to figure out what comes next. Yet while GPT-5.x uses a newer tokenization method, first introduced with OpenAI 04-mini and GPT-4o (named o200k_harmony), it still encounters this token-based spelling problem. OpenAI has fixed other words, but strawberry is still a problem M-i-s-s-i-s-s-i-p-p-i When ChatGPT first launched back in late 2022, it was full of token-based struggles. Other specific phrases would set the AI into a fury or an introspective death spiral. But over the years, OpenAI has mostly patched these "errors" out of the system, adjusting the training and building better systems. I tried some other classic word problems that would trip up ChatGPT, none of which had the desired effect. The AI tool managed to correctly spell and identify all the letters in "Mississippi," and had no problems reversing the word "lollipop," with all the letters in the right order. It still can't do exact word amounts over small values, but that's a long-known problem with AI models in general. They're generally not good at counting specific numbers, despite being good at math and problem-solving. One small quirk I really enjoyed was asking ChatGPT about one of those early meltdown moments: ' solidgoldmagikarp'. This odd-sounding phrase was a glitch in GPT-3 that caused the model to freak out, insult the user, present unintelligible outputs, and more, all due to how the tokenization process works. ChatGPT 5.2, the latest model at the time of writing, didn't necessarily freak out, but it did delve into a wonderfully odd hallucination. According to ChatGPT, "solidgoldmagikarp" is a secret Pokémon joke on GitHub that developers hide in their repos. If you somehow activate it, your avatar, repo icons, and other GitHub features will automagically turn into Pokémon-themed characters. As you may expect, this is completely false, and is a hangover from the ' solidgoldmagikarp' string causing such issues before. Related This ChatGPT trick feels too good to be hidden Did you know ChatGPT can do this? Posts 1 By Amir Bohlooli Sep 27, 2025 Other AI models don't suffer from this problem I've tried quite a few different options What I find most interesting about this whole strawberry problem is that other AI models don't have the same problem... even those using OpenAI's models. I posed the same question to Perplexity, Claude, Grok, Gemini, Qwen, and Copilot, and each of them answered the question absolutely fine. The answer for this misnomer is that all of these other AI models use a different tokenization system that helps them identify all the r's in strawberry, even if they're using one of OpenAI's models. It's not ChatGPT being wildly inconsistent and a little silly; the others are just different. I'm sure at some point, OpenAI will fix this quirk in its GPT model, as it does when these issues arise. But until then, we can still take some solace in the fact we're still better at counting than AI... for now.
Share
Share
Copy Link
OpenAI's GPT-5.2, released in December 2025, continues to incorrectly count two r's in the word strawberry when there are actually three. The error stems from the model's tokenization process, which splits the word into st-raw-berry tokens. While other AI models like Claude, Gemini, and Perplexity answer correctly, ChatGPT's tokenized input/output design creates persistent limitations in basic letter counting tasks that a seven-year-old could solve.
GPT-5.2 Fails Basic Letter Counting Despite Advanced Capabilities
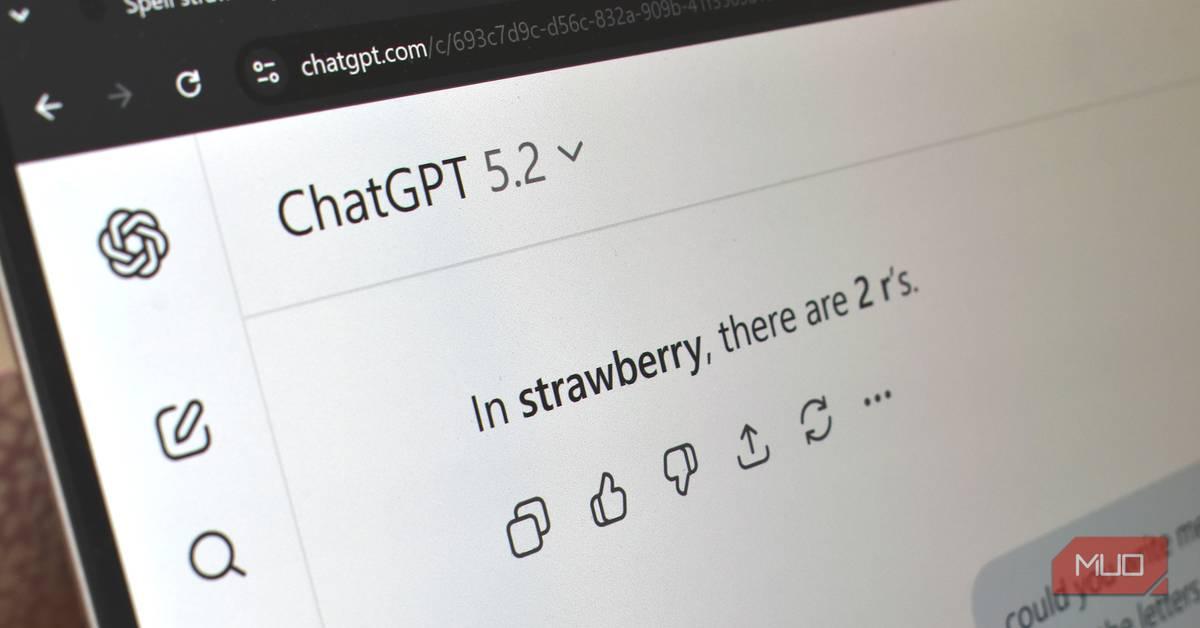
OpenAI's GPT-5.2, released in December 2025, demonstrates a puzzling weakness that highlights the persistent limitations of large language models. Despite billions of dollars in investment and the ability to generate marketing images, compile reports, and create chart-topping songs, ChatGPT powered by GPT-5.2 incorrectly counts 'r's in strawberry
1
. The word contains three r's—one after the 't' and two consecutive in the 'berry' portion—yet the model consistently reports only two2
.
Source: MakeUseOf
This ChatGPT counting error persists as a test for AI performance across multiple model iterations. Previous versions exhibited uncertainty or erratic behavior on the strawberry question, but the latest model delivers a direct answer of two without deviation
1
. The outcome remains unchanged despite elevated hardware demands that have pushed RAM prices higher and substantial global water consumption linked to training infrastructure2
.Tokenization Explains the Inability to Accurately Count Specific Letters
The root cause lies in the tokenized input/output design that defines how large language models process text. When users input "strawberry," ChatGPT doesn't process individual letters S-T-R-A-W-B-E-R-R-Y. Instead, tokenization breaks text into chunks called tokens—whole words, syllables, or word parts
2
. The model counts tokens containing the letter rather than performing precise letter enumeration1
.The OpenAI Tokenizer tool illustrates this process clearly. Entering "strawberry" yields three tokens: st, raw, berry. The first token contains no r, the second includes one r, and the third contains two r's but functions as a single token
1
. The model associates r's with only two tokens, leading to the incorrect count. This tokenization pattern affects similar words—raspberry divides into comparable tokens, causing ChatGPT to report two r's for that word as well1
.GPT-5.2 incorporates the o200k_harmony tokenization method, first introduced with OpenAI o4-mini and GPT-4o models. This updated scheme aims for efficiency but retains the strawberry discrepancy
1
. ChatGPT operates as a prediction engine, leveraging patterns from training data to anticipate subsequent elements rather than functioning with true intelligence2
.OpenAI Has Fixed Other Tokenization Issues But Core Problems Remain
When ChatGPT launched in late 2022, it was riddled with token-based challenges. Specific phrases triggered excessive responses or processing failures
1
. OpenAI addressed many through training adjustments and system enhancements over subsequent years. Verification tests on classic problems showed improvements—ChatGPT now accurately spells Mississippi, identifying one m, four i's, four s's, and two p's. It also reverses "lollipop" to "popillol," preserving all letters in proper sequence1
.However, tokenization issues persist in unexpected ways. A notable historical example involves solidgoldmagikarp, a string that disrupted tokenization in GPT-3, causing erratic outputs including user insults and unintelligible text
1
. When queried about this phrase, GPT-5.2 produced a hallucination, describing it as a secret Pokémon joke embedded in GitHub repositories that transforms avatars and icons into Pokémon-themed elements—a claim completely lacking basis in reality1
2
.Related Stories




Competing AI Models Demonstrate Superior Letter Counting Through Different Approaches
Comparative tests across other AI models yielded correct results for the strawberry question, revealing that this limitation isn't universal. Perplexity, Claude, Grok, Gemini, Qwen, and Copilot all correctly identified three r's in strawberry
1
. These models employ distinct tokenization systems that enable accurate letter identification, even when some are powered by OpenAI's underlying architectures1
.This discrepancy matters for users relying on AI for tasks requiring precision. While large language models excel at pattern recognition and complex outputs, they demonstrate persistent limitations in exact counting of small quantities
1
. They perform well in mathematics and problem-solving but falter on precise tallies of letters or words in brief strings1
. Understanding these fundamental constraints helps users make informed decisions about when to trust AI performance and when human verification remains essential.References
Summarized by
Navi
[1]
[2]
Related Stories
Recent Highlights
1
Apple Plans Major Siri AI Overhaul in iOS 27 With Third-Party Chatbot Integration
Technology

2
OpenAI shuts down Sora after six months, ending Disney's $1 billion licensing partnership
Technology

3
AI chatbots validate you too much, making you less kind to others, Stanford study reveals
Science and Research

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.