Nvidia's Hyperlink Agent Brings Private AI-Powered Search to Local PCs
2 Sources
2 Sources
[1]
Nvidia's AI tool finds everything you saved without leaking a byte of data
LLM inference on Hyperlink doubles in speed with Nvidia's latest optimization Nexa.ai's new "Hyperlink" agent introduces an approach to AI search which runs entirely on local hardware. Designed for Nvidia RTX AI PCs, the app functions as an on-device assistant that turns personal data into structured insight. Nvidia outlined how instead of sending queries to remote servers, it processes everything locally, offering both speed and privacy. Hyperlink has been benchmarked on an RTX 5090 system, where it reportedly delivers up to 3x faster indexing and 2x the large language model inference speed compared to earlier builds. These metrics suggest it can scan and organize thousands of files across a computer more efficiently than most existing AI tools. Hyperlink does not simply match search terms, as it interprets user intent by applying the reasoning capabilities of LLMs to local files, allowing it to locate relevant material even when file names are obscure or unrelated to the actual content. This shift from static keyword search to contextual comprehension aligns with the growing integration of generative AI into everyday productivity tools. The system can also connect related ideas from multiple documents, offering structured answers with clear references. Unlike most cloud-based assistants, Hyperlink keeps all user data on the device, so the files it scans, ranging from PDFs and slides to images, remain private, ensuring that no personal or confidential information leaves the computer. This model appeals to professionals handling sensitive data who still want the performance advantages of generative AI. Users gain access to fast contextual responses without the risk of data exposure that accompanies remote storage or processing. Nvidia's optimization for RTX hardware extends beyond search performance, as the company claims retrieval-augmented generation (RAG) now indexes dense data folders up to three times faster. A typical 1GB collection that once took nearly 15 minutes to process can now be indexed in about 5 minutes. The improvement in inference speed also means responses appear more quickly, making everyday tasks such as meeting preparation, study sessions, or report analysis smoother. Hyperlink merges convenience with control by combining local reasoning and GPU acceleration, making it a useful AI tool for people who want to keep their data private.
[2]
Meet Hyperlink: A local NotebookLM-style tool for you
Nvidia says local processing ensures sensitive materials never leave the machine making it suitable for professionals with confidential workloads. Nexa.ai has introduced a new AI search agent called "Hyperlink," designed to run entirely on local hardware. The application is built for Nvidia RTX AI PCs and functions as an on-device assistant capable of turning personal data into structured insights. By connecting information from notes, slides, PDFs, and images, the tool aims to organize and interpret user files effortlessly. Nvidia outlined that the key differentiator for Hyperlink is its ability to process queries locally rather than sending them to remote servers. This ensures that all scanned files and user data remain private on the device, preventing personal or confidential information from leaving the computer. This approach is intended to appeal to professionals who manage sensitive data but still require the performance benefits of generative AI. Performance benchmarks reported by TechRadar indicate significant speed improvements. When tested on an RTX 5090 system, Hyperlink delivered up to three times faster indexing and double the large language model (LLM) inference speed compared to previous builds. Nvidia claims that its optimization of retrieval-augmented generation (RAG) allows the tool to process dense data folders much more quickly; for example, a 1GB collection of data that previously took nearly 15 minutes to index can now be processed in approximately 5 minutes. Beyond raw speed, Hyperlink moves away from static keyword matching. It utilizes the reasoning capabilities of LLMs to interpret user intent, allowing it to locate relevant materials even if file names are obscure or unrelated to their content. The system can also connect related ideas across multiple documents to provide structured answers with clear references.
Share
Share
Copy Link
Nexa.ai's Hyperlink agent offers on-device AI search for Nvidia RTX PCs, delivering 3x faster indexing and 2x inference speed while keeping all data private and local.
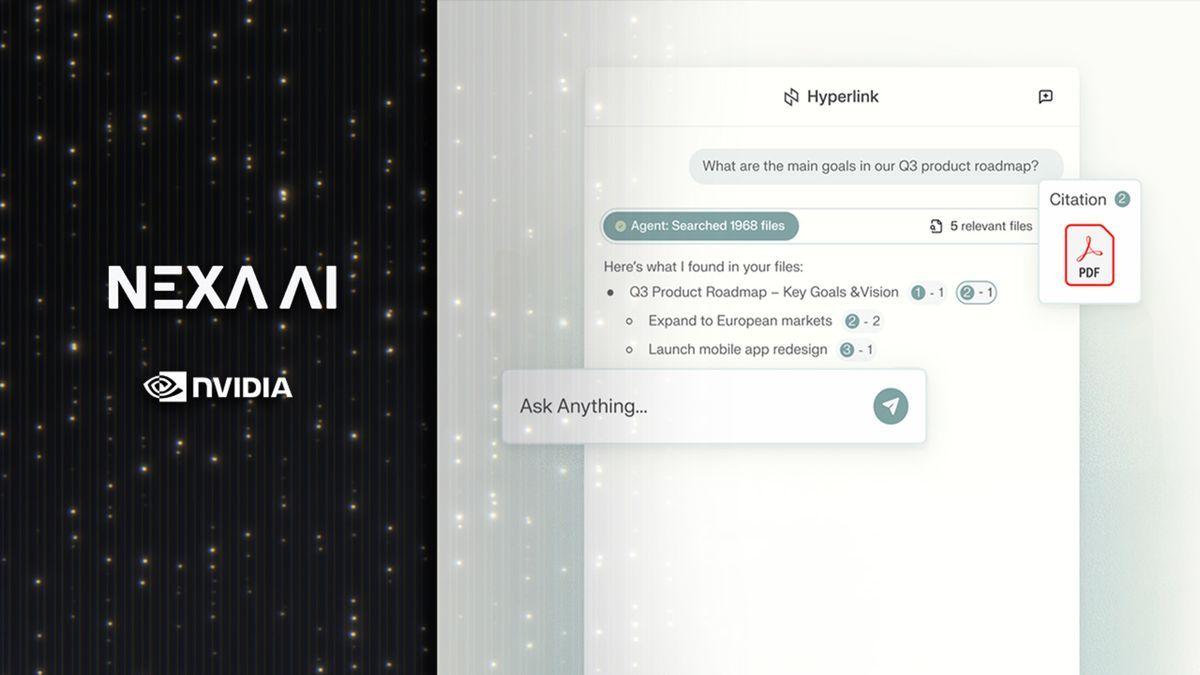
Revolutionary Local AI Search Technology
Nexa.ai has unveiled Hyperlink, a groundbreaking AI search agent that operates entirely on local hardware, specifically designed for Nvidia RTX AI PCs
1
. This on-device assistant transforms personal data into structured insights by processing information from notes, slides, PDFs, and images without requiring internet connectivity or cloud services2
.The application represents a significant shift in AI-powered productivity tools, addressing growing concerns about data privacy while maintaining the performance benefits of generative artificial intelligence. Unlike traditional cloud-based assistants that send queries to remote servers, Hyperlink processes everything locally, ensuring that sensitive materials never leave the user's machine
2
.Impressive Performance Benchmarks
Performance testing on an RTX 5090 system has demonstrated remarkable improvements in processing capabilities. Hyperlink delivers up to three times faster indexing speeds and doubles the large language model inference performance compared to earlier builds
1
. These enhancements enable the system to scan and organize thousands of files across a computer more efficiently than most existing AI tools.Nvidia's optimization of retrieval-augmented generation (RAG) technology has yielded particularly impressive results. A typical 1GB collection of data that previously required nearly 15 minutes to process can now be indexed in approximately 5 minutes
1
. This dramatic improvement in processing speed makes everyday tasks such as meeting preparation, study sessions, and report analysis significantly more efficient.Advanced Contextual Understanding
Hyperlink transcends traditional keyword-based search methodologies by incorporating the reasoning capabilities of large language models. Rather than simply matching search terms, the application interprets user intent and applies contextual comprehension to locate relevant material even when file names are obscure or unrelated to their actual content
1
.The system's ability to connect related ideas from multiple documents sets it apart from conventional search tools. It provides structured answers with clear references, enabling users to discover connections between disparate pieces of information that might otherwise remain hidden
2
. This contextual approach aligns with the growing integration of generative AI into everyday productivity applications.Related Stories

Privacy-First Architecture
The most compelling aspect of Hyperlink is its commitment to data privacy. All user information, including scanned files ranging from PDFs and presentations to images, remains entirely on the local device
1
. This architecture eliminates the risks associated with remote storage or cloud processing, making it particularly attractive to professionals handling confidential workloads.Users can access fast contextual responses without the data exposure risks that typically accompany cloud-based AI services. This model represents a significant advancement for organizations and individuals who require the performance advantages of generative AI while maintaining strict data security protocols
2
.References
Summarized by
Navi
[2]
Related Stories
NVIDIA RTX delivers 3x faster AI video generation and 35% boost for language models on PC
06 Jan 2026•Technology

NVIDIA Unveils Local AI Foundation Models for RTX AI PCs at CES 2025
07 Jan 2025•Technology

Nvidia launches Nemotron 3 Super with 5x throughput boost to power enterprise AI agents
11 Mar 2026•Technology

Recent Highlights
1
Tennessee Teens Sue Elon Musk's xAI Over Grok AI-Generated Child Abuse Images
Policy and Regulation

2
Pentagon designates Palantir Maven AI as core US military system in major defense shift
Technology

3
Supermicro Co-Founder Indicted in $2.5 Billion Nvidia AI Chip Smuggling Scheme to China
Policy and Regulation

Recent Highlights
Today's Top Stories



Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.