D-Matrix Challenges HBM with 3DIMC: A New Memory Technology for AI Inference
2 Sources
2 Sources
[1]
New 3D-stacked memory tech seeks to dethrone HBM in AI inference -- d-Matrix claims 3DIMC will be 10x faster and 10x more efficient
Memory startup d-Matrix is claiming its 3D stacked memory will be up to 10x faster and run at up to 10x greater speeds than HBM. d-Matrix's 3D digital in-memory compute (3DIMC) technology is the company's solution for a memory type purpose-built for AI inference. High-bandwidth memory, or HBM, has become an essential part of AI and high-performance computing. HBM memory stacks memory modules on top of each other to more efficiently connect memory dies and access higher memory performance. However, while its popularity and use continue to expand, HBM may not be the best solution for all computational tasks; where it is key for AI training, it can be outmatched in AI inference. To this end, d-Matrix has just brought its d-Matrix Pavehawk 3DIMC silicon online in the lab. Digital in-memory compute hardware currently looks like LPDDR5 memory dies with DIMC chiplets stacked on top, attached via an interposer. This setup allows the DIMC hardware to perform computations within the memory itself. The DIMC logic dies are tuned for matrix-vector multiplication, a common calculation used by transformer-based AI models in operation. "We believe the future of AI inference depends on rethinking not just compute, but memory itself," said Sid Sheth, founder and CEO of d-Matrix, in a recent LinkedIn post. "AI inference is bottlenecked by memory, not just FLOPs. Models are growing fast, and traditional HBM memory systems are getting very costly, power hungry, and bandwidth limited. 3DIMC changes the game. By stacking memory in three dimensions and bringing it into tighter integration with compute, we dramatically reduce latency, improve bandwidth, and unlock new efficiency gains." With Pavehawk currently running in d-Matrix's labs, the firm is already looking ahead to its next generation, Raptor. In a company blog post as well as Sheth's LinkedIn announcement, the firm claims that this next-gen, also built on a chiplet model, will be the one to outpace HBM by 10x in inference tasks while using 90% less power. The d-Matrix DIMC project follows a pattern we've seen in recent startups and from tech theorists: positing that specific computational tasks, such as AI training vs. inference, should have hardware specifically designed to efficiently handle just that task. d-Matrix holds that AI inference, which now makes up 50% of some hyperscalers' AI workloads, is a different-enough task than training that it deserves a memory type built for it. A replacement for HBM is also attractive from a financial standpoint. HBM is only produced by a handful of global companies, including SK hynix, Samsung, and Micron, and its prices are anything but cheap. SK hynix recently estimated that the HBM market will grow by 30% every year until 2030, with price tags rising to follow demand. An alternative to this giant may be attractive to thrifty AI buyers -- though a memory made exclusively for certain workflows and calculations may also seem a bit too myopic for bubble-fearing potential clients.
[2]
Corsair and Pavehawk could finally break the memory wall as D-Matrix bets everything on stacked DRAM and custom silicon
Sandisk and SK Hynix recently signed an agreement to develop "High Bandwidth Flash," a NAND-based alternative to HBM designed to bring larger, non-volatile capacity into AI accelerators. D-Matrix is now positioning itself as a challenger to high-bandwidth memory in the race to accelerate artificial intelligence workloads. While much of the industry has concentrated on training models using HBM, this company has chosen to focus on AI inference. Its current design, the D-Matrix Corsair, uses a chiplet-based architecture with 256GB of LPDDR5 and 2GB of SRAM. Rather than chasing more expensive memory technologies, the idea is to co-package acceleration engines and DRAM, creating a tighter link between compute and memory. This technology, called D-Matrix Pavehawk, will launch with 3DIMC, which is expected to rival HBM4 for AI inference with 10x bandwidth and energy efficiency per stack. Built on a TSMC N5 logic die and combined with 3D-stacked DRAM, the platform aims to bring compute and memory much closer than in conventional layouts. By eliminating some of the data transfer bottlenecks, D-Matrix suggests it could reduce both latency and power use. Looking at its technology path, D-Matrix appears committed to layering multiple DRAM dies above the logic silicon to push bandwidth and capacity further. The company argues that this stacked approach may deliver an order of magnitude in performance gains while using less energy for data movement. For an industry grappling with the limits of scaling memory interfaces, the proposal is ambitious but remains unproven. It is worth noting that memory innovations around inference accelerators are not new. Other firms have been experimenting with tightly coupled memory and compute solutions, including designs with built-in controllers or links through interconnect standards like CXL. D-Matrix, however, is attempting to go further by integrating custom silicon to rework the balance between cost, power, and performance. The backdrop to these developments is the persistent cost and supply challenge surrounding HBM. Large players such as Nvidia can secure top-tier HBM parts, but smaller companies or data centers often have to settle for lower-speed modules. This disparity creates an uneven playing field where access to the fastest memory directly shapes competitiveness. If D-Matrix can indeed deliver on lower-cost and higher-capacity alternatives, it would address one of the central pain points in scaling inference at the data center level. Despite the claims of "10x better performance" and "10x better energy efficiency," D-Matrix is still at the beginning of what it describes as a multi-year journey. Many companies have attempted to tackle the so-called memory wall, yet few have reshaped the market in practice. The rise of AI tools and the reliance on every LLM show the importance of scalable inference hardware. However, whether Pavehawk and Corsair will mature into widely adopted alternatives or remain experimental remains to be seen.
Share
Share
Copy Link
D-Matrix, a memory startup, claims its 3D digital in-memory compute (3DIMC) technology will be 10x faster and more efficient than HBM for AI inference tasks. The company's Pavehawk and Corsair platforms aim to revolutionize memory architecture for AI applications.
D-Matrix Introduces 3DIMC: A Potential Game-Changer for AI Inference
D-Matrix, a memory startup, has unveiled its 3D digital in-memory compute (3DIMC) technology, positioning it as a formidable challenger to high-bandwidth memory (HBM) in the realm of AI inference. The company claims that its innovative approach could be up to 10 times faster and 10 times more energy-efficient than current HBM solutions
1
2
.The Need for Specialized Memory in AI
As AI workloads continue to grow, the industry has recognized the need for memory solutions tailored to specific computational tasks. While HBM has become essential for AI training and high-performance computing, it may not be the optimal choice for all scenarios, particularly in AI inference
1
.D-Matrix argues that AI inference, which now constitutes up to 50% of some hyperscalers' AI workloads, requires a memory type built specifically for its unique demands
1
. This aligns with a broader trend in the tech industry of developing hardware solutions optimized for particular computational tasks.3DIMC Technology: Bridging the Gap Between Compute and Memory
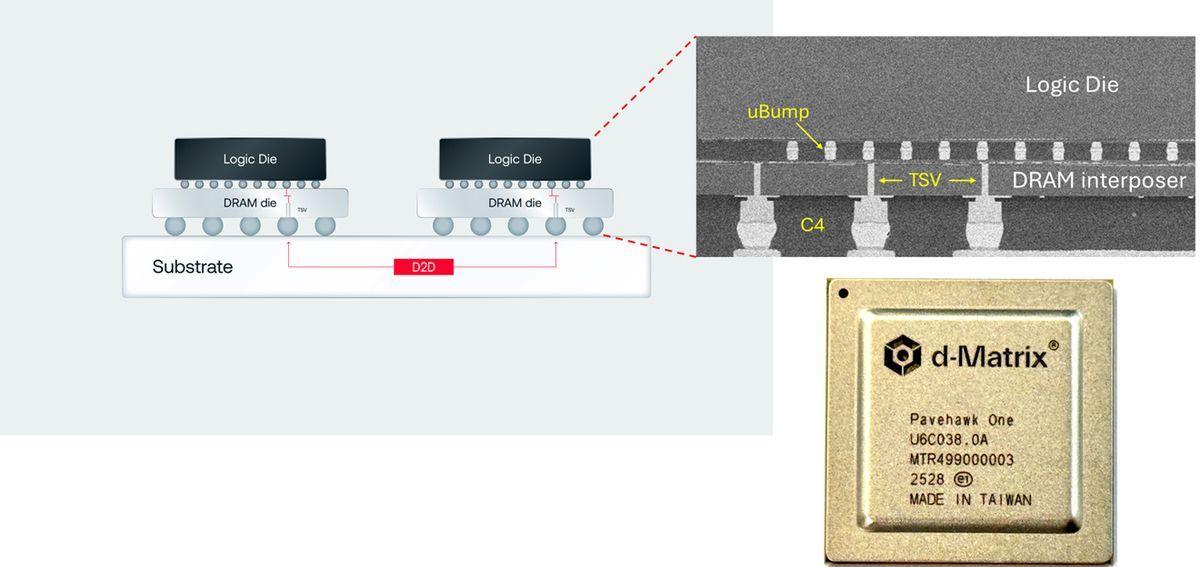
The core of D-Matrix's innovation lies in its approach to memory architecture. The company's Pavehawk 3DIMC silicon, recently brought online in the lab, utilizes a unique design:

Source: TechRadar
- LPDDR5 memory dies are stacked with DIMC chiplets on top
- An interposer connects the components
- DIMC hardware performs computations within the memory itself
- Logic dies are optimized for matrix-vector multiplication, a common calculation in transformer-based AI models
1
This design aims to dramatically reduce latency, improve bandwidth, and achieve new levels of efficiency by bringing compute and memory into tighter integration
1
2
.Corsair and Pavehawk: D-Matrix's Product Lineup
D-Matrix is developing two key products to showcase its 3DIMC technology:
- Corsair: A chiplet-based architecture featuring 256GB of LPDDR5 and 2GB of SRAM
2
. - Pavehawk: The next-generation platform, expected to rival HBM4 for AI inference with claims of 10x bandwidth and energy efficiency per stack
2
.
Built on a TSMC N5 logic die and combined with 3D-stacked DRAM, Pavehawk aims to push the boundaries of memory performance and efficiency
2
.
Source: Tom's Hardware
Related Stories

Potential Impact on the AI Hardware Landscape
If successful, D-Matrix's technology could address several key challenges in the AI hardware industry:
-
Cost Reduction: HBM is produced by only a handful of companies and comes with a hefty price tag. An alternative could be attractive to cost-conscious AI buyers
1
. -
Supply Chain Issues: Large players like Nvidia can secure top-tier HBM parts, but smaller companies often struggle. D-Matrix's solution could level the playing field
2
. -
Scalability: By potentially offering lower-cost and higher-capacity alternatives, D-Matrix could address a central pain point in scaling inference at the data center level
2
.
Challenges and Future Outlook
While D-Matrix's claims are ambitious, the technology remains unproven in real-world applications. The company describes its journey as a multi-year process, and many previous attempts to tackle the "memory wall" have fallen short of reshaping the market
2
.As the AI industry continues to grapple with the limits of scaling memory interfaces, D-Matrix's 3DIMC technology represents a bold attempt to rethink the relationship between compute and memory. Whether Pavehawk and Corsair will mature into widely adopted alternatives or remain experimental concepts remains to be seen, but their potential impact on AI inference hardware is undeniable
1
2
.References
Summarized by
Navi
[1]
Related Stories
Micron develops stacked GDDR memory as cost-effective HBM alternative for AI inference
30 Mar 2026•Technology

d-Matrix Unveils JetStream: A Game-Changing AI Network Accelerator for Ultra-Low-Latency Inference
09 Sept 2025•Technology

SK hynix Leads the Charge in Next-Gen AI Memory with World's First 12-Layer HBM4 Samples
19 Mar 2025•Technology

Recent Highlights
1
AI Models Lie and Deceive to Protect Other AI Models From Deletion, Study Reveals
Science and Research

2
AI chatbots validate you too much, making you less kind to others, Stanford study reveals
Science and Research

3
Judge blocks Pentagon from blacklisting Anthropic over AI safety guardrails dispute
Policy and Regulation

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.