d-Matrix Unveils JetStream: A Game-Changing AI Network Accelerator for Ultra-Low-Latency Inference
2 Sources
2 Sources
[1]
d-Matrix aspires to rack scale AI with JetStream I/O cards
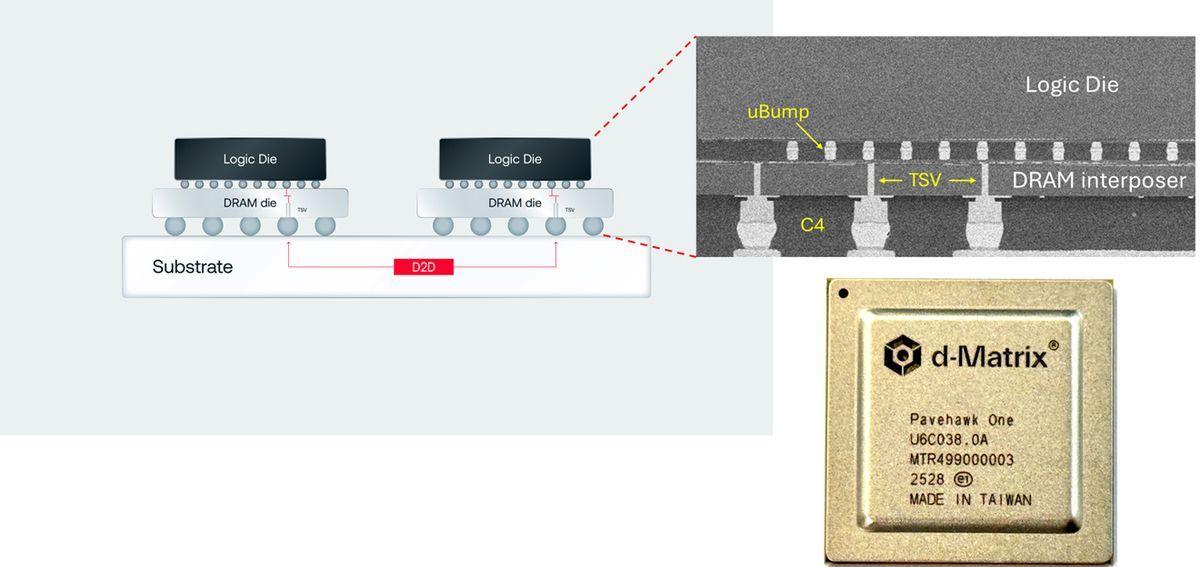
Who needs HBM when you can juggle SRAM speed and LPDDR bulk across racks AI chip startup d-Matrix is pushing into rack scale with the introduction of its JetStream I/O cards, which are designed to allow larger models to be distributed across multiple servers or even racks while minimizing performance bottlenecks. At face value, JetStream presents itself as a fairly standard PCIe 5.0 NIC. It supports two ports at 200 Gb/s or a single port at 400 Gb/s and operates over standard Ethernet. According to CEO Sid Sheth, the startup looked at using off-the-shelf NICs from the likes of Nvidia, but company researchers weren't satisfied with the latency they could achieve using them. Instead, they opted to design their own NIC using a field programmable gate array (FPGA) that consumes about 150W. More importantly, d-Matrix claims that it was able to cut network latency to just two microseconds. Two of these NICs are designed to be paired with up to eight of the chip vendor's 600-watt Corsair AI accelerators in a topology resembling the following. The custom ASICs are no slouch either, with each card capable of churning out 2.4 petaFLOPS when using the MXINT8 data type or 9.6 petaFLOPS when using the lower precision MXINT4 type. d-Matrix's memory hierarchy pairs a rather large amount of blisteringly fast SRAM with much, much slower, but higher capacity LPDDR5 memory, the same kind you'd find in a high-end notebook. Each Corsair card contains 2GB of SRAM good for 150 TB/s along with 256GB of LPDDR5 capable of 400 GB/s. To put those figures in perspective, a single Nvidia B200 offers 180GB of HBM3e and 8TB/s of bandwidth. As a reminder, AI inference is usually a bandwidth-constrained workload, which means the faster your memory is, the quicker it'll churn out tokens. "Depending on the tradeoffs the customer wants to make between speed and cost, they can pick the type of memory they want to run the models on," Sheth said. Two terabytes of LPDDR5 per node gives you enough capacity to run multi-trillion parameter models at 4-bit precision, but with 3.2 TB/s of aggregate memory bandwidth, it won't be quick. For maximum performance, d-Matrix suggests running models entirely in SRAM instead. But with 16GB of ultra-fast on-chip memory per node, those wanting to run larger, more capable models are going to need a lot of systems. With eight nodes per rack, d-Matrix estimates it can run models up to about 200 billion parameters at MXINT4 precision, with larger models possible when scaling across multiple racks. And this is exactly what d-Matrix JetStream I/O cards are designed to enable. d-Matrix is utilizing a combination of tensor, expert, data, and pipeline parallelism to maximize the performance of these rack-scale compute clusters. With just 800 Gb/s of aggregate bandwidth coming off the two JetStream NICs in these systems, d-Matrix appears to be following a similar strategy to what we've seen in GPU systems to date, utilizing tensor parallelism to distribute the model weights and computational workload across the node's eight accelerators and some combination of pipeline or expert parallelism to scale that compute across multiple nodes or racks. The result is a bit of an inference assembly line, where the model is broken into chunks that are processed in sequence, one node at a time. If that sounds familiar, this is how competing chip startups like Groq (not to be confused with xAI's authoritarian-obsessed LLM Grok) or Cerebras have managed to build extremely high-performance inference services without relying on high-bandwidth memory. If you thought using 64 AI accelerators to run a 200 billion parameter model was a lot, Groq used 576 of its language processing units (LPUs) to run Llama 2 70B, albeit at a higher precision. Despite the added complexity of distributing models across that many accelerators, keeping them in SRAM clearly has its benefits. d-Matrix says its Corsair chips can achieve generation latencies as low as 2 ms per token in models like Llama 3.1 70B. Add in some speculative decoding, like Cerebras has done with its own SRAM packed chips, and we would not be surprised to see that performance jump by 2x or 3x. With JetStream, d-Matrix is better positioned to compete in this arena. However, the lack of interconnect bandwidth afforded by the NICs means the company's rack scale push is currently limited to scale-out the scale up architectures Nvidia and AMD are now transitioning to with their NVL72 and Helios rack systems, the latter of which we'll note won't actually ship until next year at the earliest. However, it won't be long before d-Matrix joins them with its next-gen Raptor family of accelerators, which, in addition to 3D stacked SRAM for higher capacity, will use an integrated electrical I/O chiplet to achieve rack-scale networking akin to Nvidia's NVLink. While still a ways off, the d-Matrix roadmap has it eventually transitioning to an optical I/O chiplet, which will allow the architecture to scale across multiple racks or even rows of systems. According to d-Matrix, JetStream is currently sampling to customers with production expected to ramp before the end of the year. ®
[2]
D-Matrix introduces AI network accelerator card for ultra-low-latency inference - SiliconANGLE
D-Matrix introduces AI network accelerator card for ultra-low-latency inference Artificial intelligence computing infrastructure startup d-Matrix Corp. today unveiled a custom network card named JetStream designed from the ground up to support high-speed, ultra-low-latency AI inference for data centers. As the adoption of generative AI increases, particularly with larger and more complex models that can reason and produce multimodal content, data centers are increasingly distributing these models across multiple machines. This distribution necessitates not only powerful computing capabilities for each machine but also high-speed networking between them. "JetStream networking comes at a time when AI is going multimodal, and users are demanding hyper-fast levels of interactivity," said dMatrix co-founder and Chief Executive Sid Sheth. "Through JetStream, together with our already announced Corsair compute accelerator platform, d-Matrix is providing a path forward that makes AI both scalable and blazing fast." Corsair is the company's line of powerful AI inference compute cards designed for standard data center rack servers. It is designed to solve challenges in economics and running AI at a large scale by providing extremely fast integrated memory that can scale better than graphical processing units, which are among the current standard for deploying AI. AI inference is the process of using a trained model to make decisions and predictions based on new data, basically what happens when an AI model is running. Major cloud infrastructure providers, such as Microsoft Corp. and Google Cloud, have continually faced challenges in delivering ultra-fast AI at high capacity because of performance limitations. Sheth said that now that the company is innovating cards that help resolve memory and compute bottlenecks, it's tackling the next biggest issue: networking. JetStream is a full-height PCIe Gen5 card that plugs directly into a standard port in a datacenter server and delivers a maximum of 400 gigabits per second. It is designed to be compatible with off-the-shelf Ethernet switches and deploy easily within a data center without the need to replace hardware or build extra infrastructure to support it. "We did not want to build something exotic in terms of interfacing with the ecosystem and we wanted it to be aligned with the standards," explained Sree Ganesan, d-Matrix's vice president of product. "This is what our customers are asking for: Can I just plug-and-play with what's in my datacenter? This is us saying: Yes, you can continue to use your standard Ethernet switches." The company said that, combined with its Corsair accelerators and the company's Aviator software, the new card can achieve up to 10 times the speed and triple the cost performance at triple the energy efficiency compared with GPU-based offerings. D-matrix said samples are available now, and full production of the cards is expected by the end of the year.
Share
Share
Copy Link
d-Matrix introduces JetStream, a custom network card designed for high-speed, ultra-low-latency AI inference in data centers, aiming to revolutionize rack-scale AI computing.
d-Matrix Introduces JetStream: A New Era in AI Network Acceleration
d-Matrix, an AI chip startup, has unveiled its latest innovation in the field of artificial intelligence computing: the JetStream I/O card. This custom network card is designed to revolutionize rack-scale AI by enabling larger models to be distributed across multiple servers or racks while minimizing performance bottlenecks
1
2
.
Source: The Register
Technical Specifications and Performance
JetStream presents itself as a PCIe 5.0 NIC (Network Interface Card) with impressive capabilities:
- Supports two ports at 200 Gb/s or a single port at 400 Gb/s
- Operates over standard Ethernet
- Consumes about 150W
- Achieves network latency of just two microseconds
1
The JetStream card is designed to work in tandem with d-Matrix's Corsair AI accelerators. Each Corsair card boasts:
- 2.4 petaFLOPS performance using MXINT8 data type
- 9.6 petaFLOPS when using the lower precision MXINT4 type
- 2GB of SRAM with 150 TB/s bandwidth
- 256GB of LPDDR5 memory with 400 GB/s bandwidth
1
Innovative Memory Hierarchy
d-Matrix's approach to memory management is unique, pairing fast SRAM with higher capacity LPDDR5 memory. This strategy allows for flexibility in balancing speed and cost, depending on customer requirements
1
.Scaling AI Models
The JetStream and Corsair combination enables:
- Running multi-trillion parameter models at 4-bit precision
- Models up to about 200 billion parameters at MXINT4 precision in a single rack
- Larger models when scaling across multiple racks
1
Parallelism and Performance
d-Matrix utilizes a combination of tensor, expert, data, and pipeline parallelism to maximize performance in rack-scale compute clusters. This approach creates an "inference assembly line," where the model is processed in sequence across multiple nodes
1
.Related Stories

Competitive Advantage
According to d-Matrix, the JetStream-Corsair combination offers significant advantages over GPU-based solutions:
- Up to 10 times the speed
- Triple the cost performance
- Triple the energy efficiency
2
Market Position and Future Developments

Source: SiliconANGLE
While d-Matrix's current offering positions it well in the AI acceleration market, the company is already looking ahead:
- The next-gen Raptor family of accelerators will feature 3D stacked SRAM and an integrated electrical I/O chiplet
- Future plans include transitioning to an optical I/O chiplet for even greater scalability
1
Availability and Industry Impact
JetStream is currently sampling to customers, with production expected to ramp up before the end of the year
1
2
. As AI models continue to grow in size and complexity, solutions like JetStream could play a crucial role in enabling more efficient and powerful AI infrastructure.The introduction of JetStream comes at a critical time when the AI industry is moving towards multimodal capabilities and demanding faster interactivity. d-Matrix's innovation addresses key challenges in AI scalability and performance, potentially reshaping the landscape of AI computing infrastructure
2
.References
Summarized by
Navi
[1]
Related Stories
D-Matrix Challenges HBM with 3DIMC: A New Memory Technology for AI Inference
04 Sept 2025•Technology
NVIDIA Unveils NVLink Fusion: Enabling Custom AI Infrastructure with Industry Partners
19 May 2025•Technology

NVIDIA AI Servers Achieve 10x Performance Boost for Mixture of Experts Models from DeepSeek and Moonshot
04 Dec 2025•Technology

Recent Highlights
1
OpenAI Releases GPT-5.4, New AI Model Built for Agents and Professional Work
Technology

2
Anthropic sues Pentagon over supply chain risk label after refusing autonomous weapons use
Policy and Regulation

3
OpenAI secures $110 billion funding round as questions swirl around AI bubble and profitability
Business and Economy

Recent Highlights
Today's Top Stories



Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.