DeepSeek's Engram tackles AI compute waste with conditional memory breakthrough
5 Sources
5 Sources
[1]
Deepseek research touts memory breakthrough, decoupling compute power and RAM pools to bypass GPU & HBM constraints -- Engram conditional memory module commits static knowledge to system RAM
DeepSeek has released a new technical paper, which details a new method for how new AI models might rely on a queryable database of information committed to system memory. Named "Engram", the conditional memory-based technique achieves demonstrably higher performance in long-context queries by committing sequences of data to static memory. This eases the reliance on reasoning for AI models, allowing the GPUs to only handle more complex tasks, increasing performance, and reducing the reliance on high-bandwidth memory (HBM). The paper details how N-grams, statistical sequences of words, are integrated into the model's neural networks, allowing them to be placed into a queryable memory bank. Engram allows models to remember facts, rather than having to reason them out, which is more computationally expensive. Released on the company's GitHub page, Engram hopes to address how the company might be able to curb the reliance on more complex memory types and instead commit a knowledge library to a more common system memory standard, such as CXL. The ongoing reliance on high-bandwidth memory for AI accelerators is something that even Chinese silicon, such as Huawei's Ascend series, cannot escape. Each stack of HBM uses more memory dies, and with demand skyrocketing, easing any AI model's reliance on the GPU's direct high-bandwidth memory would be significant, especially considering the ongoing memory supply squeeze. Engram would enable static memory to be held separately from an LLM's compute power, allowing the GPU's rapid HBM to dedicate itself to reasoning, therefore enabling more performant Engram-based AI models, compared to a standard Mixture of Experts (MoE) model. As detailed in the paper, an Engram-based model scaled to nearly 27 billion parameters can beat out a standard MoE model in long-context training and eliminates computational waste generated by having to reason out facts, by allowing them to be externally stored. A standard MoE model might have to reconstruct these pieces of data every time it's referenced in a query, which is called conditional computation. The model will then call on its expert parameters to assemble and reason the data every time, even when it only focuses the query on certain parts or experts, named sparse computation. The Engram paper adds that placing conditional memory would allow the model to merely ask: "Do I already have this data?", rather than having to access the parts of the model that deal with reasoning. "This process essentially amounts to an expensive runtime reconstruction of a static lookup table, wasting valuable sequential depth on trivial operations that could otherwise be allocated to higher-level reasoning," the paper reads. Engram takes static patterns and lists its knowledge index into a parsable piece of conditional memory with a store of information, relieving the AI model from the burden of having to reason through context repeatedly. While Nvidia's KVCache, announced at CES 2026, offloads context data to NVMe memory with BlueField-4, this acts as more of a short-term solution, allowing the model to remember things that you have recently said or added within context, and is, for all intents and purposes, disposable after you move on to the next query or conversation. KVCache, while persistent within the history of your conversations or queries, does not draw on an existing base of pre-calculated data, and is not persistent in the same way that Engram-based LLMs could be, if the paper is to be believed. To put it simply, KVCache can be likened to storing your handwritten notes, whereas Engram is a record of the whole encyclopedia. This is enabled through tokenizer compression, which compresses equivalent tokens (such as the same word with different forms of capitalization) as the same, canonical concept. This allowed Deepseek to reduce the vocabulary size for the conditional memory module by 23%, and allows for rapid parsing of information in context. As there is an impossibly large number of phrases or combinations of words within a certain context, they employ a methodology named Hashing, which allows the model to apply a number to a series of words. Engram adds to this, with what it calls Multi-Head Hashing, where you can put several hashes onto multiple numbers, for that single phrase to avoid erroneously adding the wrong context. For example, Universal might be a single entry, distinct from Universal Studios, with Multi-Head Hashing employed to ensure no mistakes or database errors. This is then passed on to Engram's context-aware gating, which then confirms that the term matches the context of the sentence it's being used in, before being deployed into an output. To examine how Engram-based LLMs might work in large-scale deployments, Deepseek detailed how it might achieve the best allocation between embeddings of Engram and MoE parameters within an AI model. The outcome was a U-curve, which proved that memory and compute (or reasoning) can be considered mathematically distinct forms of intelligence within AI models. This resulted in a sweetspot for MoE and Engram embeddings. "Remarkably, the Engram model achieves comparable performance to the pure MoE baseline (𝜌 = 100%) even when the MoE allocation is reduced to just 𝜌 ≈ 40% (i.e., a total of 46 experts for the 5.7B model and 43 experts for the 9.9B model). Furthermore, the pure MoE baseline proves suboptimal: reallocating roughly 20%-25% of the sparse parameter budget to Engram yields the best performance." Deepseek itself remarks on how both Engram-dominated and MoE-dominated models falter, whereas a ratio that yields 20-25% of the overall parameter budget of the model to Engram achieves the best results. Deepseek ran another experiment in parallel, which it names the "Infinite Memory Regime." This effectively keeps the computational budget fixed, so the model doesn't get more expensive to run, and attaches a near infinite number of conditional memory parameters to be deployed using Engram. What they found was that since Engram is distinct from the overall compute budget (since it's effectively a long-term storage bank, which taps into the overall model), Deepseek discovered that performance scales linearly with memory size. Meaning that if a model continued to add to its conditional memory banks, its performance would only continue to improve, without having to increase the overall compute budget. This could have significant implications for the wider AI industry if performance and results are not singularly bound by compute, but to long-term "Engram" memory banks. If the performance benefits are indeed as good as the paper outlines, the memory squeeze would no longer be singularly based on the deployment of HBM, but all forms of memory that could be deployed within data centers, either through CXL or other methods of interconnection. Deepseek deployed an Engram-27B parameter model and a standard 27B MoE model in parallel to determine the performance benefits of computational memory within AI models, and the results were exemplary. Within knowledge-intensive tasks, Engram was 3.4 to 4 points better than its MoE equivalent, and it was even better at reasoning, with a 3.7 to 5 point uplift when compared to its MoE "reasoning-only" sibling. Similar results were also achieved in coding and mathematics-based tests. However, the big win for Engram was in long-context tasks, increasing accuracy within the NIAH (Needle in a Haystack) benchmark to 97%, which is a leap from the MoE model's score of 84.2%. This is a large difference in reliability between the models, and could point toward AI's long-context and coherence issues eventually becoming a thing of the past, if Engram were to be deployed in a commercial AI model, especially if the demands for long-context AI queries increase. Engram has significant implications for the AI industry, especially as the paper details how this specific methodology is no longer bound by HBM, but instead longer-term storage. System DRAM can now be utilized to significantly improve the quality of Engram-based LLM outputs, meaning that the much more expensive HBM will only be used for computationally heavy queries. Of course, if Engram were to take off, it may worsen the ongoing DRAM supply crisis, as AI hyperscalers adopting the methodology would then flock to system DRAM, instead of solely focusing on putting all of their memory ICs in production into HBM for GPUs. "We envision conditional memory functions as an indispensable modeling primitive for next-generation sparse models," Deepseek said, hinting at a possible V4 deploying Engram in a new AI model. With the company rumored to announce a new AI model within the next few weeks, don't be surprised if it implements Engram within it. While the results are impressive on paper, Engram's impact has yet to be determined in real-world deployment. But, if everything the paper says holds in a real-world context, the company could be onto a new 'Deepseek moment.'
[2]
New AI method lets models think harder while avoiding costly bandwidth
Engram supports asynchronous prefetching across multiple GPUs with minimal performance overhead DeepSeek, in collaboration with Peking University, introduced a new training method called Engram, designed to decouple memory storage from computational processes. Traditional large language models require high-bandwidth memory for knowledge retrieval and basic computation, creating a bottleneck in both performance and cost. This HBM bottleneck is widely recognized as a key reason DRAM prices rose by 5X in just 10 weeks, as hardware demand spiked to support large AI models. The researchers said existing models waste sequential depth on trivial operations, which could otherwise support higher-level reasoning. Engram allows models to efficiently "look up" essential information without overloading GPU memory, freeing capacity for more complex reasoning tasks. The system was tested on a 27-billion-parameter model and showed measurable improvements across standard industry benchmarks. By performing knowledge retrieval through hashed N-grams, Engram provides static memory access independent of the current context. The retrieved information is then adjusted using a context-aware gating mechanism to align with the model's hidden state. This design allows models to handle long context inputs more efficiently and supports system-level prefetching with minimal performance overhead. The Engram method complements other hardware-efficient approaches, including solutions such as Phison's AI inference accelerators. Engram minimizes the amount of high-speed memory required by using lookups for static information, making memory usage more efficient. Phison offers a cost-effective way to expand total memory using SSDs, supporting large AI models such as Engram or Mixture-of-Experts systems. Combined, these approaches allow AI systems to optimize fast-memory usage while affordably increasing overall memory capacity. It also works alongside emerging CXL (Compute Express Link) standards, which aim to overcome GPU memory bottlenecks in large-scale AI workloads. The method separates static pattern storage from dynamic computation, enhancing the Transformer backbone without increasing FLOPs or parameter counts. DeepSeek formalized a U-shaped expansion rule to optimize the allocation of parameters between the MoE conditional computation module and the Engram memory module. Tests show that reallocating around 20-25% of the sparse parameter budget to Engram yields better performance than pure MoE models, maintaining stable gains across different scales. Memory slot expansion provides predictable improvements without additional computational cost. This confirms the scalability of conditional memory as an independent axis for sparse models. Engram's deterministic retrieval mechanism allows memory capacity to scale linearly across multiple GPUs while supporting asynchronous prefetching during inference. It offloads static knowledge reconstruction from lower layers, freeing attention mechanisms to focus on global context. Hierarchical caching of frequently used embeddings enhances efficiency, and the module works with existing GPU and system memory architectures, potentially avoiding costly HBM upgrades. This technique may relieve pressure on expensive memory hardware, particularly in regions such as China, where HBM access lags behind competitors such as Samsung, SK Hynix, and Micron. Early validation of Engram suggests models can expand parameter scale and reasoning capacity while managing memory demands more efficiently. This approach may help ease memory constraints across AI infrastructure, potentially reducing sharp DDR5 DRAM price swings. Via SCMP
[3]
DeepSeek's conditional memory fixes silent LLM waste: GPU cycles lost to static lookups
When an enterprise LLM retrieves a product name, technical specification, or standard contract clause, it's using expensive GPU computation designed for complex reasoning -- just to access static information. This happens millions of times per day. Each lookup wastes cycles and inflates infrastructure costs. DeepSeek's newly released research on "conditional memory" addresses this architectural limitation directly. The work introduces Engram, a module that separates static pattern retrieval from dynamic reasoning. It delivers results that challenge assumptions about what memory is actually for in neural networks. The paper was co-authored by DeepSeek founder Liang Wenfeng. Through systematic experiments DeepSeek found the optimal balance between computation and memory with 75% of sparse model capacity allocated to dynamic reasoning and 25% to static lookups. This memory system improved reasoning more than knowledge retrieval. Complex reasoning benchmarks jumped from 70% to 74% accuracy, while knowledge-focused tests improved from 57% to 61%. These improvements came from tests including Big-Bench Hard, ARC-Challenge, and MMLU. The research arrives as enterprises face mounting pressure to deploy more capable AI systems while navigating GPU memory constraints and infrastructure costs. DeepSeek's approach offers a potential path forward by fundamentally rethinking how models should be structured. How conditional memory solves a different issue than agentic memory and RAG Agentic memory systems, sometimes referred to as contextual memory -- like Hindsight, MemOS, or Memp -- focus on episodic memory. They store records of past conversations, user preferences, and interaction history. These systems help agents maintain context across sessions and learn from experience. But they're external to the model's forward pass and don't optimize how the model internally processes static linguistic patterns. For Chris Latimer, founder and CEO of Vectorize, which developed Hindsight, the conditional memory approach used in Engram solves a different problem than agentic AI memory. "It's not solving the problem of connecting agents to external memory like conversation histories and knowledge stores," Latimer told VentureBeat. "It's more geared towards squeezing performance out of smaller models and getting more mileage out of scarce GPU resources." Conditional memory tackles a fundamental issue: Transformers lack a native knowledge lookup primitive. When processing text, they must simulate retrieval of static patterns through expensive neural computation across multiple layers. These patterns include named entities, technical terminology, and common phrases. The DeepSeek paper illustrates this with a concrete example. Recognizing "Diana, Princess of Wales" requires consuming multiple layers of attention and feed-forward networks to progressively compose features. The model essentially uses deep, dynamic logic circuits to perform what should be a simple hash table lookup. It's like using a calculator to remember your phone number rather than just looking it up. "The problem is that Transformer lacks a 'native knowledge lookup' ability," the researchers write. "Many tasks that should be solved in O(1) time like retrieval have to be 'simulated for retrieval' through a large amount of computation, which is very inefficient." How conditional memory works Engram introduces "conditional memory" to work alongside MoE's conditional computation. The mechanism is straightforward. The module takes sequences of two to three tokens and uses hash functions to look them up in a massive embedding table. Retrieval happens in constant time, regardless of table size. But retrieved patterns need filtering. A hash lookup for "Apple" might collide with unrelated content, or the word might mean the fruit rather than the company. Engram solves this with a gating mechanism. The model's current understanding of context (accumulated through earlier attention layers) acts as a filter. If retrieved memory contradicts the current context, the gate suppresses it. If it fits, the gate lets it through. The module isn't applied at every layer. Strategic placement balances performance gains against system latency. This dual-system design raises a critical question: How much capacity should each get? DeepSeek's key finding: the optimal split is 75-80% for computation and 20-25% for memory. Testing found pure MoE (100% computation) proved suboptimal. Too much computation wastes depth reconstructing static patterns; too much memory loses reasoning capacity. Infrastructure efficiency: the GPU memory bypass Perhaps Engram's most pragmatic contribution is its infrastructure-aware design. Unlike MoE's dynamic routing, which depends on runtime hidden states, Engram's retrieval indices depend solely on input token sequences. This deterministic nature enables a prefetch-and-overlap strategy. "The challenge is that GPU memory is limited and expensive, so using bigger models gets costly and harder to deploy," Latimer said. "The clever idea behind Engram is to keep the main model on the GPU, but offload a big chunk of the model's stored information into a separate memory on regular RAM, which the model can use on a just-in-time basis." During inference, the system can asynchronously retrieve embeddings from host CPU memory via PCIe. This happens while GPU computes preceding transformer blocks. Strategic layer placement leverages computation of early layers as a buffer to mask communication latency. The researchers demonstrated this with a 100B-parameter embedding table entirely offloaded to host DRAM. They achieved throughput penalties below 3%. This decoupling of storage from compute addresses a critical enterprise constraint as GPU high-bandwidth memory remains expensive and scarce. What this means for enterprise AI deployment For enterprises evaluating AI infrastructure strategies, DeepSeek's findings suggest several actionable insights: 1. Hybrid architectures outperform pure approaches. The 75/25 allocation law indicates that optimal models should split sparse capacity between computation and memory. 2. Infrastructure costs may shift from GPU to memory. If Engram-style architectures prove viable in production, infrastructure investment patterns could change. The ability to store 100B+ parameters in CPU memory with minimal overhead suggests that memory-rich, compute-moderate configurations may offer better performance-per-dollar than pure GPU scaling. 3. Reasoning improvements exceed knowledge gains. The surprising finding that reasoning benefits more than knowledge retrieval suggests that memory's value extends beyond obvious use cases. For enterprises leading AI adoption, Engram demonstrates that the next frontier may not be simply bigger models. It's smarter architectural choices that respect the fundamental distinction between static knowledge and dynamic reasoning. The research suggests that optimal AI systems will increasingly resemble hybrid architectures. Organizations waiting to adopt AI later in the cycle should monitor whether major model providers incorporate conditional memory principles into their architectures. If the 75/25 allocation law holds across scales and domains, the next generation of foundation models may deliver substantially better reasoning performance at lower infrastructure costs.
[4]
Decoding DeepSeek's Solution to China's Compute Shortage | AIM
DeepSeek's new research enables retrieval using computational memory, not neural computation, freeing up GPUs. Ahead of the highly anticipated launch of its v4 model, DeepSeek has published research that could fundamentally reshape how large language models handle knowledge, and potentially sidestep the hardware constraints hampering Chinese AI development. In a paper co-authored by DeepSeek CEO Liang Wenfeng, the research introduces "Engram", a method that allows language models to retrieve knowledge through direct lookup rather than wasteful computation. DeepSeek's work matters because Chinese AI labs are looking for algorithmic efficiency, as they are running out of room to scale using brute-force compute due to US export controls on GPUs. The paper explains that much of the GPU budget is spent reconstructing information that could be retrieved directly from memory or caches. As the authors put it, "Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation." While Mixture-of-Experts (MoE) models
[5]
DeepSeek's Engram Conditional Memory Shows How to Reduce AI Compute Waste
Are transformers really the pinnacle of AI innovation, or are they just an overengineered way to solve simple problems? Prompt Engineering explores how the innovative DeepSeek Engram challenges the dominance of transformer-based architectures by proposing a bold alternative: treating transformers as little more than expensive hashmaps. This provocative claim stems from Engram's ability to separate straightforward recall tasks from complex reasoning, introducing a smarter, more efficient way to handle language model computation. By rethinking how tasks are processed, Engram not only reduces computational waste but also redefines what scalability and speed can look like in large language models. In this overview, we'll break down the core innovations behind Engram, including its use of hash-based lookups for simple memory tasks and its context-aware gating mechanism for deeper reasoning. You'll discover how this architecture minimizes GPU load, improves latency, and challenges the inefficiencies of traditional transformers. But it's not all smooth sailing, Engram's reliance on static lookup tables and potential hash collisions raises important questions about its adaptability and precision. Could this be the future of AI, or just a stepping stone to something greater? Let's explore the implications and limitations of this new approach. Transformers, the foundational architecture behind many LLMs, apply the same computational effort to all tasks, regardless of complexity. Whether retrieving a straightforward fact like "Paris is the capital of France" or solving a challenging reasoning problem, transformers treat these tasks equally. This uniform approach leads to inefficiencies: simple recall tasks unnecessarily engage multiple transformer layers, inflating computational costs and limiting scalability. As LLMs grow larger and more complex, these inefficiencies become increasingly problematic, hindering their ability to operate effectively in real-world scenarios. Engram introduces a novel architecture that addresses these inefficiencies by incorporating a conditional memory mechanism. This mechanism separates static memory tasks, such as fact retrieval, from dynamic reasoning tasks that require deeper computation. The key components of this system include: By allocating computational resources based on task complexity, Engram achieves a balance between speed and accuracy, making it a more efficient alternative to traditional transformer-based models. Enhance your knowledge on DeepSeek AI by exploring a selection of articles and guides on the subject. Engram's architecture uses token combinations, or n-grams, extracted from input text to optimize task processing. These n-grams are hashed to retrieve embeddings from a pre-trained lookup table stored in system RAM. The process unfolds as follows: This design offloads static memory tasks to hash-based lookups, freeing up transformer layers for tasks requiring deeper reasoning. By reducing the computational burden on transformers, Engram not only improves efficiency but also minimizes latency during inference, allowing faster and more responsive performance. Engram delivers significant performance improvements across a variety of benchmarks, demonstrating its effectiveness in optimizing LLM computation. Key areas of improvement include: By reallocating resources to focus on complex reasoning, Engram enables deeper and more accurate processing without increasing the number of transformer layers. This results in faster task completion and improved scalability, making it a practical solution for large-scale applications. Engram's reliance on hash-based lookups introduces several hardware optimizations that make it more accessible and cost-effective to deploy. These include: These hardware efficiencies lower the barriers to deploying large-scale LLMs, allowing organizations to use advanced AI capabilities without incurring prohibitive costs. This makes Engram particularly appealing for industries that require scalable and efficient AI solutions. While Engram offers numerous advantages, it is not without its challenges. Some of the key limitations include: These limitations highlight areas where additional research and development could enhance Engram's capabilities, making sure its applicability across a broader range of use cases. Engram's design draws inspiration from human cognition, mirroring the separation between fast, automatic recall (System 1) and deliberate, effortful reasoning (System 2). This approach represents a significant evolution in LLM architecture, akin to the introduction of attention mechanisms in earlier models. By aligning computational methods with task requirements, Engram reduces costs and improves scalability, making advanced AI more accessible to a wider audience. Its influence could extend beyond LLMs, shaping future innovations in AI by emphasizing efficiency, task-specific processing, and resource optimization.
Share
Share
Copy Link
DeepSeek unveiled Engram, a conditional memory technique that separates static information retrieval from complex reasoning tasks. The method allows AI models to bypass GPU memory constraints by committing knowledge to system RAM, reducing reliance on expensive high-bandwidth memory while improving performance on long-context queries.
DeepSeek introduces conditional memory to address AI efficiency challenges
DeepSeek has released a technical paper detailing Engram, a conditional memory-based approach that fundamentally changes how AI models handle knowledge retrieval and reasoning. Co-authored by DeepSeek CEO Liang Wenfeng, the research tackles a critical inefficiency in Transformer models: the wasteful use of GPU cycles for simple lookups that could be handled through direct memory access
1
3
. When enterprise AI systems retrieve basic information like product names or technical specifications, they currently use expensive GPU computation designed for complex reasoning tasks, wasting cycles millions of times per day and inflating infrastructure costs3
.The research arrives as organizations face mounting pressure to deploy more capable AI systems while navigating GPU memory constraints and rising hardware costs. This HBM bottleneck is widely recognized as a key reason DRAM prices rose by 5X in just 10 weeks, as hardware demand spiked to support large AI models
2
. For Chinese AI labs operating under US export controls on GPUs, Engram offers a potential path forward by optimizing algorithmic efficiency rather than relying on brute-force compute scaling4
.How Engram separates static lookups from dynamic reasoning
Engram works by decoupling compute power from memory storage, allowing models to efficiently look up essential information without overloading GPU memory
2
. The system uses N-grams—statistical sequences of words—integrated into the model's neural networks and placed into a queryable memory bank1
. This enables models to remember facts rather than having to reason them out through computationally expensive neural computation each time.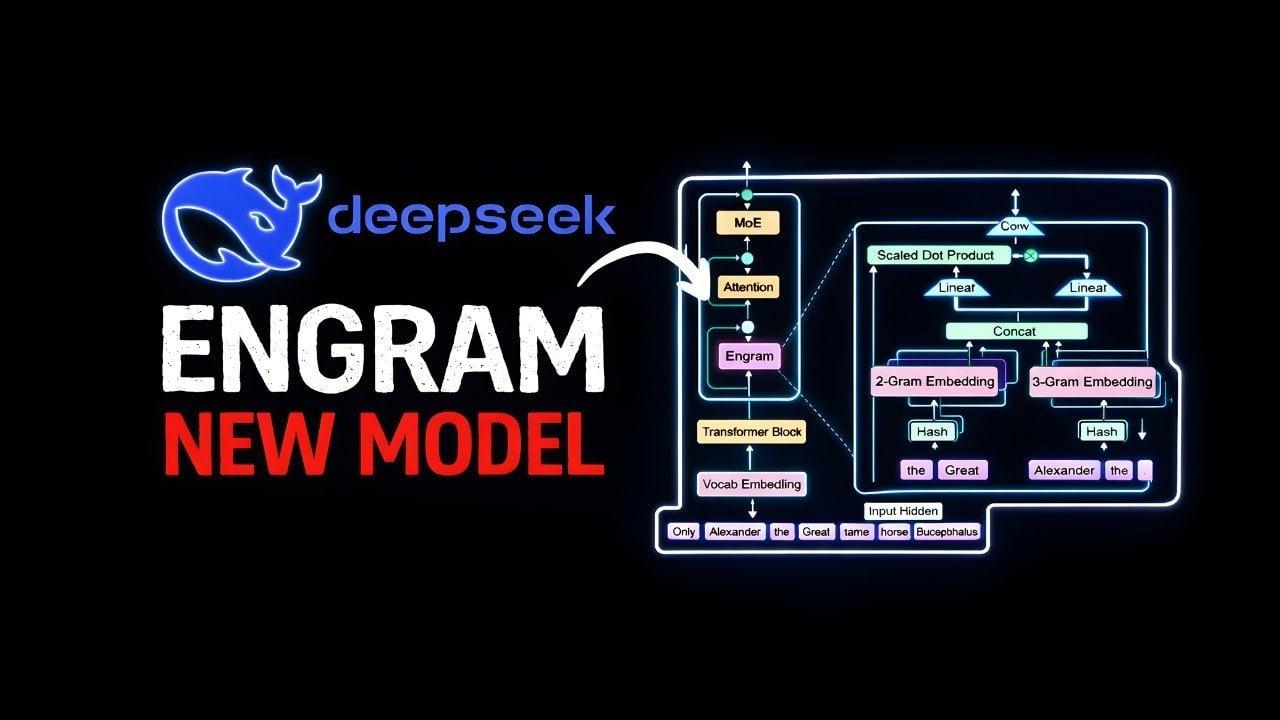
Source: Geeky Gadgets
The mechanism relies on hash-based lookups for static information retrieval. Token combinations extracted from input text are hashed to retrieve embeddings from a pre-trained lookup table stored in system RAM
5
. A standard Mixture of Experts (MoE) model might have to reconstruct these pieces of data every time they're referenced in a query through conditional computation, calling on expert parameters to assemble and reason the data even when focusing on certain parts1
. Engram allows the model to simply ask "Do I already have this data?" rather than accessing the parts of the model that deal with reasoning.To prevent errors, Engram employs a context-aware gating mechanism that filters retrieved patterns. A hash lookup for "Apple" might collide with unrelated content, or the word might mean the fruit rather than the company
3
. The model's current understanding of context acts as a filter—if retrieved memory contradicts the current context, the gate suppresses it; if it fits, the gate lets it through. This design allows models to handle long-context handling more efficiently and supports system-level prefetching with minimal performance overhead [2](https://www.techradar.com/pro/deepseek-may-have-found-a-way-to-solve-the-ram-crisis-by-eliminating-the-need-for-expensive-hbm-for-ai-inference-and-training-yes, the very reason why dram prices went up by 5x in 10 weeks).Optimal parameter allocation reduces computational waste
Through systematic experiments, DeepSeek discovered the optimal balance between computation and memory: 75-80% of sparse model capacity allocated to dynamic reasoning tasks and 20-25% to static lookups
3
. Tests showed that reallocating around 20-25% of the parameter budget to Engram yields better performance than pure MoE models, maintaining stable gains across different scales [2](https://www.techradar.com/pro/deepseek-may-have-found-a-way-to-solve-the-ram-crisis-by-eliminating-the-need-for-expensive-hbm-for-ai-inference-and-training-yes, the very reason why dram prices went up by 5x in 10 weeks).
Source: VentureBeat
An Engram-based model scaled to nearly 27 billion parameters demonstrated measurable improvements across standard industry benchmarks
1
. Complex reasoning benchmarks jumped from 70% to 74% accuracy, while knowledge-focused tests improved from 57% to 61%, with improvements measured across Big-Bench Hard, ARC-Challenge, and MMLU3
. Memory slot expansion provides predictable improvements without additional computational cost, confirming the scalability of conditional memory as an independent axis for sparse models [2](https://www.techradar.com/pro/deepseek-may-have-found-a-way-to-solve-the-ram-crisis-by-eliminating-the-need-for-expensive-hbm-for-ai-inference-and-training-yes, the very reason why dram prices went up by 5x in 10 weeks).Related Stories




Infrastructure implications and hardware efficiency gains
Engram's deterministic retrieval mechanism allows memory capacity to scale linearly across multiple GPUs while supporting asynchronous prefetching during inference [2](https://www.techradar.com/pro/deepseek-may-have-found-a-way-to-solve-the-ram-crisis-by-eliminating-the-need-for-expensive-hbm-for-ai-inference-and-training-yes, the very reason why dram prices went up by 5x in 10 weeks). The approach works with existing GPU and system memory architectures, potentially avoiding costly high-bandwidth memory (HBM) upgrades. It also aligns with emerging CXL (Compute Express Link) standards, which aim to overcome GPU memory constraints in large-scale AI workloads [2](https://www.techradar.com/pro/deepseek-may-have-found-a-way-to-solve-the-ram-crisis-by-eliminating-the-need-for-expensive-hbm-for-ai-inference-and-training-yes, the very reason why dram prices went up by 5x in 10 weeks).
The technique may relieve pressure on expensive memory hardware, particularly in regions where HBM access lags behind competitors like Samsung, SK Hynix, and Micron [2](https://www.techradar.com/pro/deepseek-may-have-found-a-way-to-solve-the-ram-crisis-by-eliminating-the-need-for-expensive-hbm-for-ai-inference-and-training-yes, the very reason why dram prices went up by 5x in 10 weeks). Engram differs from solutions like Nvidia's KVCache, which offloads context data to NVMe memory with BlueField-4
1
. While KVCache acts as short-term memory for recent conversations, Engram provides persistent access to pre-calculated data—essentially storing the whole encyclopedia rather than just handwritten notes.Chris Latimer, founder and CEO of Vectorize, notes that conditional memory solves a different problem than agentic AI memory systems: "It's more geared towards squeezing performance out of smaller models and getting more mileage out of scarce GPU resources"
3
. Early validation suggests models can expand parameter scale and reasoning capacity while managing memory demands more efficiently, potentially reducing sharp DDR5 DRAM price swings [2](https://www.techradar.com/pro/deepseek-may-have-found-a-way-to-solve-the-ram-crisis-by-eliminating-the-need-for-expensive-hbm-for-ai-inference-and-training-yes, the very reason why dram prices went up by 5x in 10 weeks). Organizations should monitor how Engram performs in production deployments and whether its approach to reduce computational waste becomes standard practice for optimizing AI infrastructure costs.References
Summarized by
Navi
[3]
Related Stories
Recent Highlights
1
Google Maps unveils Ask Maps with Gemini AI and 3D Immersive Navigation in biggest update
Technology

2
AI chatbots help plan violent attacks as safety guardrails fail, new investigation reveals
Technology

3
Three Tennessee teens sue xAI over Grok AI creating child sexual abuse material from real photos
Policy and Regulation

Recent Highlights
Today's Top Stories



Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.