Nvidia unveils powerful Vera Rubin chip as Jensen Huang maps ambitious AI future at CES
16 Sources
16 Sources
[1]
Nvidia Sees Strong Chinese Demand for H200, Has Enough Supply
Nvidia Corp. said it has seen strong demand from customers in China for the H200 chip that the Trump administration has said it will consider letting the chipmaker ship to that country. License applications have been submitted and the government is deciding what it wants to do with them, Chief Financial Officer Colette Kress told analysts Monday during a meeting at the CES trade show in Las Vegas. Nvidia Chief Executive Officer Jensen Huang described the demand as strong. Regardless of the level of license approval, Kress said, Nvidia has enough supply to serve customers in the Asian nation without impacting the company's ability to ship to customers elsewhere in the world. Nvidia would also need China's government to allow companies in the country to purchase and use the American products. Beijing previously discouraged government agencies and companies there from using an earlier, less powerful design, called H20. Nvidia Corp. Chief Executive Officer Jensen Huang said that the company's highly anticipated Rubin data center processors are in production and customers will soon be able to try out the technology. All six of the chips for a new generation of computing equipment -- named after astronomer Vera Rubin -- are back from manufacturing partners and on track for deployment by customers in the second half of the year, Huang said at the CES trade show in Las Vegas Monday. "Demand is really high," he said. The growing complexity and uptake of artificial intelligence software is placing a strain on existing computer resources, creating the need for much more, Huang said. Nvidia, based in Santa Clara, California, is seeking to maintain its edge as the leading maker of artificial intelligence accelerators, the chips used by data center operators to develop and run AI models. Some on Wall Street have expressed concern that competition is mounting for Nvidia -- and that AI spending can't continue at its current pace. Data center operators also are developing their own AI accelerators. But Nvidia has maintained bullish long-term forecasts that point to a total market in the trillions of dollars. Rubin is Nvidia's latest accelerator and is 3.5 times better at training and five times better at running AI software than its predecessor, Blackwell, the company said. A new central processing unit has 88 cores -- the key data-crunching elements -- and provides twice the performance of the component that it's replacing. The company is giving details of its new products earlier in the year than it typically does -- part of a push to keep the industry hooked on its hardware, which has underpinned an explosion in AI use. Nvidia usually dives into product details at its spring GTC event in San Jose, California. Even while talking up new offerings, Nvidia said previous generations of products are still performing well. The company also has seen strong demand from customers in China for the H200 chip that the Trump administration has said it will consider letting the chipmaker ship to that country. License applications have been submitted, and the US government is deciding what it wants to do with them, Chief Financial Officer Colette Kress told analysts. Regardless of the level of license approval, Kress said, Nvidia has enough supply to serve customers in the Asian nation without affecting the company's ability to ship to customers elsewhere in the world. For Huang, CES is yet another stop on his marathon run of appearances at events, where he's announced products, tie-ups and investments all aimed at adding momentum to the deployment of AI systems. His counterpart at Nvidia's closest rival, Advanced Micro Devices Inc.'s Lisa Su, was slated to give a keynote presentation at the show later Monday. The new hardware, which also includes networking and connectivity components, will be part of its DGX SuperPod supercomputer while also being available as individual products for customers to use in a more modular way. The step-up in performance is needed because AI has shifted to more specialized networks of models that not only sift through massive amounts of inputs but need to solve particular problems through multistage processes. The company emphasized that Rubin-based systems will be cheaper to run than Blackwell versions because they'll return the same results using smaller numbers of components. Microsoft Corp. and other large providers of remote computing will be among the first to deploy the new hardware in the second half of the year, Nvidia said. For now, the majority of spending on Nvidia-based computers is coming from the capital expenditure budgets of a handful of customers, including Microsoft, Alphabet Inc.'s Google Cloud and Amazon.com Inc.'s AWS. Nvidia is pushing software and hardware aimed at broadening the adoption of AI across the economy, including robotics, health care and heavy industry. As part of that effort, Nvidia announced a group of tools designed to accelerate development of autonomous vehicles and robots.
[2]
Nvidia CEO Huang to take stage at CES in Las Vegas as competition mounts
LAS VEGAS, Jan 5 (Reuters) - Nvidia (NVDA.O), opens new tab CEO Jensen Huang is set to give a speech on Monday at the Consumer Electronics Show in Las Vegas, potentially revealing new details about product plans for the world's most valuable listed company as it faces increasing competition from both rivals and its own customers. Less than two weeks ago, the company scooped up talent and chip technology from startup Groq, including executives who were instrumental in helping Alphabet's (GOOGL.O), opens new tab Google design its own AI chips. While Google is a major Nvidia customer, its own chips have emerged as one of Nvidia's biggest threats as Google works closely with Meta Platforms and others to chip away at Nvidia's AI stronghold. At the same time, Nvidia is eager to show that its latest products can outperform older chips like the H200, which U.S. President Donald Trump has allowed to flow to China. Reuters has reported that the chip, which was the predecessor to Nvidia's current flagship "Blackwell" chip, is in high demand in China, which has alarmed China hawks across the U.S. political spectrum. Huang's speech is scheduled to begin at 4 p.m. EST (2100 GMT). Other key speakers at the annual trade show this year include AMD (AMD.O), opens new tab CEO Lisa Su, the CEO of Finnish health tech company Oura, Tom Hale, and PC maker Lenovo's (0992.HK), opens new tab CEO, Yuanqing Yang. Reporting by Stephen Nellis in Las Vegas; Editing by Matthew Lewis Our Standards: The Thomson Reuters Trust Principles., opens new tab
[3]
Nvidia announces new, more powerful Vera Rubin chip made for AI
Next generation of chips in 'full production' and will arrive later this year, Jensen Huang says at CES in Las Vegas Nvidia CEO Jensen Huang said on Monday that the company's next generation of chips is in "full production" saying they can deliver five times the artificial-intelligence computing of the company's previous chips when serving up chatbots and other AI apps. In a speech at the Consumer Electronics Show in Las Vegas, the leader of the world's most valuable company revealed new details about its chips, which will arrive later this year and which Nvidia executives are in the company's labs being tested by AI firms, as Nvidia faces increasing competition from rivals as well as its own customers. The Vera Rubin platform, made up of six separate Nvidia chips, is expected to debut later this year, with the flagship server containing 72 of the company's graphics units and 36 of its new central processors. Huang showed how they can be strung together into "pods" with more than 1,000 Rubin chips and said they could improve the efficiency of generating what are known as "tokens" - the fundamental unit of AI systems - by 10 times. To get the new performance results, however, Huang said the Rubin chips use a proprietary kind of data that the company hopes the wider industry will adopt. "This is how we were able to deliver such a gigantic step up in performance, even though we only have 1.6 times the number of transistors," Huang said. While Nvidia still dominates the market for training AI models, it faces far more competition - from traditional rivals such as Advanced Micro Devices as well as customers like Alphabet's Google - in delivering the fruits of those models to hundreds of millions of users of chatbots and other technologies. Much of Huang's speech focused on how well the new chips would work for that task, including adding a new layer of storage technology called "context memory storage" aimed at helping chatbots provide snappier responses to long questions and conversations. Nvidia also touted a new generation of networking switches with a new kind of connection called co-packaged optics. The technology, which is key to linking together thousands of machines into one, competes with offerings from Broadcom and Cisco Systems. In other announcements, Huang highlighted new software that can help self-driving cars make decisions about which path to take - and leave a paper trail for engineers to use afterward. Nvidia showed research about software, called Alpamayo, late last year, with Huang saying on Monday it would be released more widely, along with the data used to train it so that automakers can make evaluations. "Not only do we open-source the models, we also open-source the data that we use to train those models, because only in that way can you truly trust how the models came to be," Huang said from a stage in Las Vegas. Last month, Nvidia scooped up talent and chip technology from startup Groq, including executives who were instrumental in helping Alphabet's Google design its own AI chips. While Google is a major Nvidia customer, its own chips have emerged as one of Nvidia's biggest threats as Google works closely with Meta Platforms and others to chip away at the company's lead. During a question-and-answer session with financial analysts after his speech, Huang said the Groq deal "won't affect our core business" but could result in new products that expand its lineup. At the same time, Nvidia is eager to show that its latest products can outperform older chips like the H200, which Donald Trump has allowed to flow to China. The chip, which was the predecessor to Nvidia's current "Blackwell" chip, is in high demand in China, which has alarmed China hawks across the US political spectrum.
[4]
Five thoughts from Nvidia's keynote at CES - SiliconANGLE
One of the highlights of the CES event last week was the Nvidia Corp. keynote delivered by Chief Executive Jensen Huang. Though there are many focal points to an event such as CES, the one pervasive theme is artificial intelligence, and no company has become more synonymous with AI than Nvidia. That's why thousands of people queued up for hours in advance to hear the latest and greatest vision and product news from the company's leader. While there was lots of great product news, there were some important takeaways worth calling out above and beyond the product news. During his keynote, Huang painted a picture of a world where the primary interface for many of the work tasks we do will shift to agentic agents. He cited several examples where this is happening today, including ServiceNow Inc., Palantir Technologies Inc. and Snowflake Inc. Historical interfaces, such as filling out spreadsheets, command lines and event graphical user interfaces are manually intensive and generally require the human to be the integration point between products. Agentic agents, such as Nvidia Nemotron, are not only simpler but can reason, use tools, plan and search removing much of the heavy lifting involved in work today. My research has found that workers spend up to 40% of their time managing work instead of doing the actual work and agentic agents can take that time to zero. There is so much fear and around AI taking jobs, but much of the value is in allowing us to grow productivity by an order of magnitude because we no longer have to do the things that are low value. One of the more interesting parts of Huang's talk track when he discussed his "a-ha" moment around multimodel AI. He talked about how Perplexity uses multiple large language models to get the most accurate results. "I thought it was completely genius," Huang said. "Of course, in AI, we would call upon all the world's greatest AI models to answer different questions at various points in the reasoning chain. This is why AI needs to be multimodel in nature." He added that this allows the agentic agent to use the best model for the specific task. Huang went on to explain that in addition to multimodel, agentic AI will be multimodal to understand speech, images, text, videos, 3D graphics and other forms of communications. The "multi" continues with deployment models as AI needs to be multicloud to enable models to reside in the optimal location. It's important to understand, in this case, multicloud is inclusive of hybrid cloud. This becomes increasingly important with physical AI as robots, edge servers and other connected devices required access to the data and the models in real time and that requires localized services. There have been several comparisons made to the Internet with AI and I think the biggest similarity is that AI, like the internet, will eventually embedded into everything we do and that requires AI to be multimodal, multimodel and multicloud. Big companies make acquisitions all the time but there has been perhaps no more important acquisition to Nvidia than Mellanox. The company paid just under $7 billion to gain networking capabilities and that business now generates more than $7 billion every quarter. While the primary infrastructure announcement at CES for Nvidia was the Vera Rubin platform, the network is what enables the various components to work together. Vera is the CPU and Rubin the GPU with Vera Rubin NVL72 being the AI supercomputer where the 72 Rubin GPUs and 36 Vera CPUs are connected using NVLink, one of Nvidia's networking products. In fact, of the six Vera Rubin platform announcements as part of the CES payload, four were networking, these include: Nvidia announced something called "Context Memory Storage," which the company is positioning as the right storage architecture for the AI era. With the rise of AI, Nvidia has rethought processing, the network and is now doing the same to storage. At CES, I sat down with Senior Vice President Gilad Shainer, who came to the company via the Mellanox acquisition. During our conversation we discussed how important it was the compute, network and storage be in lockstep with one another to provide the best possible performance. Shainer made an interesting point that the traditional tiers of storage are not necessarily optimized for inference, and that's what Context Memory Storage is bringing. It fundamentally redefines the storage industry by transitioning it from a general-purpose utility to a purpose-built, "AI-native" infrastructure layer designed specifically for the era of agentic reasoning. By introducing a new tier of storage, this platform bridges the critical gap between the capacity-limited GPU server storage and the traditional, general-purpose shared storage, effectively turning key-value cache into a first-class, shareable platform resource. Instead of forcing GPUs to recompute expensive context for every turn in a conversation or multistep reasoning task, the platform leverages the BlueField-4 DPU to offload metadata management and orchestrate the high-speed sharing of context across entire compute pods. This architectural shift eliminates the "context wall" that previously stalled GPU performance, delivering up to five times higher token throughput and five times better power efficiency compared to traditional storage methods. Many casual observers of the auto industry believe innovation has slowed down. This perception comes from the fact that about a half -decade ago, the industry started talking about level five self-drive and we still seem to be far from that. However, along the way the rise of digital twins, cloud to car development, camera vision and AI has allowed cars to be much safer and smarter than ever before. During his keynote, Huang highlighted that the new Mercedes-Benz CLA, built on the newly announced Alpamayo open model, achieved a five-star European New Car Assessment Program (EuroNCAP) safety rating. Alpamayo (pictured) will be a boon to the auto industry as it introduces the world's first thinking and reasoning-based AV model. Unlike traditional self-driving stacks that rely on pattern recognition and often struggle with unpredictable "long-tail" scenarios, Alpamayo employs a Vision-Language-Action architecture to perform step-by-step reasoning, allowing a vehicle to solve complex problems -- such as navigating a traffic light outage or an unusual construction zone -- by explaining its logic through "reasoning traces." By open-sourcing the Alpamayo 1 model along with the AlpaSim simulation framework and 1,700 hours of real-world driving data, Nvidia provides automakers like Mercedes-Benz, Jaguar Land Rover, and Lucid with a powerful "teacher model" that can be distilled into smaller, production-ready stacks. This ecosystem significantly lowers the barrier to achieving Level 4 autonomy by replacing "black-box" decision-making with transparent, human-like judgment, ultimately accelerating safety certification and building the public trust necessary for mass-market autonomous deployment. Nvidia's CES keynote was certainly packed with AI-based innovation. My only nitpick with the presentation was that I'd like to see the company lead with the impact and then roll into the tech. As an example, Huang went through great detail on how it contributed more models than anyone, then introduced Alpamayo and finally talked about the Mercedes safety score. He should have led with the Mercedes data point, since that's the societal impact, and then later brought the tech in. Across CES, one could see the impact that AI is having on changing the way we work and live, and no vendor has done more to bring that to life than Nvidia. Its keynote has become the marquee event within a show filled with high-profile keynotes, and I don't expect the momentum it has to slow down anytime soon.
[5]
Can Nvidia repeat its record-breaking year?
Chipmaker Nvidia had a record-setting year in 2025, becoming the world's most valuable company as the frenzy around artificial intelligence propelled its rise to the top. Now the Santa Clara giant is positioning itself for another year on top. "The race is on for AI," Jensen Huang, Nvidia's chief executive and co-founder, said at the CES trade show in Las Vegas this week. "Everybody's trying to get to the next level. Everybody's trying to get to the next frontier." The 62-year-old tech mogul, wearing a black crocodile leather jacket, outlined his ambitious vision for the future, one filled with self-driving cars, robots and other intelligent machines that go beyond the digital screen and interact with people in the physical world. As a keystone in the AI boom, Nvidia has also been caught up in concerns that trillions of dollars are being poured into AI companies that are overhyped and overvalued, forming a bubble that will burst. Nvidia has helped fuel the fire, investing in companies such as ChatGPT maker OpenAI, Intel and CoreWeave. Nvidia has also backed Elon Musk's xAI. It has been an unprecedented ascent for a high-end chipmaker that wasn't well known outside of some tech circles just five years ago. The AI bubble is unlikely to burst any time soon, analysts say, and even if it does, Nvidia won't be the hardest hit, as it will continue to dominate the market for high-end AI chips and develop new ways to bring AI into more products. "Nvidia is going to do just fine," said Gil Luria, head of technology research at D.A. Davidson. "And it is really an indication that we are using AI tools a lot." How has Nvidia benefited from the AI boom? Nvidia was co-founded by Huang in 1993 after he studied engineering in Stanford. It rose to prominence by focusing on specialized computer chips used not only for gaming but also for cryptocurrency mining, AI model training and robotics. It now employs more than 36,000 people across 38 countries, including at its sprawling facility in Silicon Valley. Nvidia primarily designs its chips in California and largely manufactures and assembles them in Asia. Last year, the company said it was working with its manufacturing partners to build Nvidia Blackwell chips in Arizona and AI supercomputers in Texas. In November, Nvidia reported a record $57 billion in revenue for the third quarter, up 62% from a year ago. The company also said last year it secured $500 billion in orders for its AI chips through 2026. Late last year, it became the first company to climb above a market value of $5 trillion, catapulting Huang's net worth to more than $160 billion. Nvidia has also struck some major partnerships, including with OpenAI, announcing in September that it planned to invest up to $100 billion in the San Francisco startup. OpenAI intends to build and deploy at least 10 gigawatts of AI data centers with Nvidia's systems. Data centers house computing equipment used to process the massive troves of information needed to train and maintain AI systems. What is Nvidia doing to stay in the spotlight? Nvidia is trying to ensure its chips are embedded with every new wave of AI-powered innovation. Its chips are hard to acquire, so the world's biggest brands are lining up to work closely with the company. Huang detailed Nvidia's work with Mercedes-Benz, which uses the tech company's autonomous vehicle software. "We imagine that someday a billion cars on a road will all be autonomous," he said, adding that people may be hailing robotaxis or even own a self-driving car. The first autonomous car powered by Nvidia's technology will hit the road in the United States in the first quarter before being released in Europe and Asia, he said. He showcased Nvidia's portfolio of AI tools to help self-driving cars reason as they navigate traffic. In a video shot in San Francisco, a self-driving Mercedes-Benz powered by Nvidia yielded to pedestrians and vehicles on the road. At one point, cute robots joined on stage as Huang discussed how Nvidia's technology also helps advance the development of robots of all sizes and shapes that deliver food, lift heavy objects or perform surgery. A new powerful AI chip, named after the American astronomer Vera Rubin, is in "full production," he said. Huang also talked about how Nvidia's products are being used to build personal assistants. He discussed Nvidia's expanded partnership with technology company Siemens to bring AI into industrial workflows, including design and production. Nvidia ramped up its partnerships with the entertainment industry as well. The company teamed up with Universal Music Group to "pioneer responsible AI for music discovery, creation and engagement." What does this mean for Nvidia's future? Nvidia's latest moves will help the company grow as it tries to spur more demand. "The start of trillions of AI spending all began with the Godfather of AI Jensen and Nvidia as they are the only game in town with their chips, the new gold and oil," wrote Wedbush Securities analysts in a note. Robotics and autonomous technology represent "an incremental market opportunity" for Nvidia, and the company could eventually reach a $6 trillion market cap, the note said. As tech companies try to unleash more self-driving cars on the road, they could also face hurdles in convincing people and regulators to become more comfortable with autonomous vehicles, Luria said. "It appears almost inevitable," he said. "The timeline is the bigger question. Is it imminent? Is it within the next couple of years, or is it still 10 to 20 years away?" What hurdles could Nvidia face? Despite being a major player in the AI race, uncertainty lingers about Nvidia's market in China, which could be worth $50 billion annually. Tariffs and trade restrictions also impact the chipmaking giant. The company lobbied aggressively for the U.S. government to ease export restrictions on AI chips so it could sell its H200 chips to Chinese companies. President Trump and tech executives have expressed concerns that China could lead in the AI race and pose a threat to U.S. national security. But Huang has developed a close relationship with Trump and the H200 chip isn't Nvidia's most advanced product. In an unusual deal, Trump said Nvidia would be allowed to sell its H200 chips if the U.S. gets a 25% percent cut of the sales. Huang said at CES that customer demand for these chips in China is "very high," but there have been questions about whether sales will go through. The Information, citing anonymous sources, reported that the Chinese government asked some Chinese tech companies to halt H200 chip orders and could mandate domestic AI chip purchases. This story originally appeared in Los Angeles Times.
[6]
Nvidia CEO Jensen Huang Says AI Is Skyrocketing Demand For GPUs
Nvidia CEO Jensen Huang said demand for computing resources is "skyrocketing" due to the rapid advancement of artificial intelligence models, calling it an "intense race" to the next frontier of the tech. In a Monday Nvidia live event in Las Vegas, Huang discussed a host of developments for the company ahead of 2026, as he pointed to the strong competition in the artificial intelligence sector. Commenting on the growth of AI since it first hit the market, Huang said that everyone has been fighting to be the first to hit the next level of the tech. "The amount of computation necessary for AI is skyrocketing. The demand for Nvidia GPUs is skyrocketing. It's skyrocketing because models are increasing by a factor of 10, an order of magnitude every single year," he said, adding: "Everybody's trying to get to the next level and somebody is getting to the next level. And so therefore, all of it is a computing problem. The faster you compute, the sooner you can get to the next level of the next frontier." The surging growth and adoption of AI have already seen a host of Bitcoin (BTC) mining companies either fully or partially pivot to the sector over the past couple of years. Related: Here's what AI models predict for Bitcoin and altcoin price ranges in 2026 This has partly been due to the Bitcoin mining difficulty increasing over time, meanwhile AI also presents an opportunity for miners to maximize their resources and potentially earn greater revenues outside of BTC. More demand for AI computing power could make a pivot to AI computing even more enticing for Bitcoin miners. During his speech, the Nvidia CEO also discussed the firm's next-generation Rubin Vera chips, stating they are currently in "full production" and are on schedule. Huang said the combination of Rubin and Vera, which were designed to work together, will be able to deliver five times greater artificial-intelligence computing performance compared to previous models.
[7]
Nvidia resets the economics of AI factories, again - SiliconANGLE
At CES 2026, Nvidia Corp. Chief Executive Jensen Huang once again reset the economics of artificial intelligence factories. In particular, despite recent industry narratives that Nvidia's moat is eroding, our assessment is the company has further solidified its position as the hardware and software standard for the next generation of computing. In the same way Intel Corp. and Microsoft Corp. dominated the Moore's Law era, we believe Nvidia will be the mainspring of tech innovation for the foreseeable future. Importantly, the previous era saw a doubling of performance every two years. Today Nvidia is driving annual performance improvements of five times, throughput of 10 times, and driving token demand of 15 times via Jevons Paradox. The bottom line is that ecosystem players and customers must align with this new paradigm or risk a fate similar to that of Sisyphus, the beleaguered figure who perpetually pushed a rock up the mountain. In this Breaking Analysis, we build on our prior work from Episode 300 with an update to our thinking. We begin with an historical view, examining the fate of companies that challenged Intel during the personal computer era and the characteristics that allowed a small number of them to survive and ultimately succeed. From there, we turn to the announcements Huang (pictured) made at CES and explain why they materially change the economics of AI factories. In our view, these developments are critical to understanding the evolving demand dynamics around performance, throughput and utilization in large-scale AI infrastructure. We close by examining the implications across the ecosystem. What does this mean for competitors such as Intel, Broadcom Inc., Advanced Micro Devices Inc. and other silicon specialists? How should hyperscalers, leading AI research labs, original equipment manufacturers and enterprise customers think about AI strategy, capital allocation and spending priorities in light of these shifts? Let's begin with a historical view, looking back at the companies that challenged Intel during the 1980s and 1990s. IBM was the dominant force early on, but it was far from the only player that attempted to compete at the silicon level. A long list of RISC vendors and alternative architectures emerged during that period - including Sun Microsystems Inc. - many of which are now footnotes in computing history. The slide above highlights this reality. The companies shown in green are the ones that managed to make it through the knothole. The rest did not. The central reason comes down to the fact that Intel delivered relentless consistency with predictable, sustained improvement in performance and price-performance, roughly doubling every two years. Intel never took its foot off the pedal. It executed Moore's Law as an operational discipline as well as a technology roadmap. As a result, competitors simply could not keep pace. Even strong architectural ideas from industry leaders were overwhelmed by Intel's scale, manufacturing advantage, volume economics and cadence. One point worth noting. Apple, while not always viewed as a direct silicon competitor during that era, ultimately won by controlling its system architecture and, later, by vertically integrating its silicon strategy. The broader takeaway is fundamental in our assumptions for the rest of this analysis. Specifically, in platform markets driven by learning curves, volume and compounding economics, dominance is not just about having a great product. Success requires sustained momentum over long periods of time, while competitors exhaust themselves trying to catch up. Let's now double down on the companies that actually survived the Intel-dominated PC era. The list below is instructive in our view. AMD, Acorn (the original Arm), Apple Inc., Taiwan Semiconductor Manufacturing Co. Intel and Nvidia. Each followed a different path, but they share a common underlying characteristic which is volume. AMD's survival traces directly back to IBM's original PC strategy. IBM mandated a second-source supplier, forcing Intel to share its instruction sets. AMD became that second source, and no other company gained comparable access. That structural advantage persisted for decades and allowed AMD to remain viable long after other x86 challengers disappeared. ARM, TSMC and Apple fundamentally changed the prevailing belief - stated by AMD CEO Jerry Sanders -- that "real men own fabs." These companies proved that separating design from manufacturing could be a winning strategy. Apple brought massive system-level volume. TSMC rode that volume to drive down costs, ultimately achieving manufacturing economics that we estimate to be roughly 30% lower than Intel's. Nvidia followed a similar fabless path, pairing architectural leadership with accelerating demand. Intel itself was the original volume powerhouse, benefiting from the virtuous cycle created by the Wintel combination. That volume allowed Intel to outlast RISC competitors and dominate the PC era. But in the current cycle, Intel has lost ground to Arm-based designs, Nvidia and TSMC - each of which now rides on steeper learning curves. The takeaway is that volume is volume is fundamental to dominance. Not just volume in a single narrow segment, but volume across adjacent and synergistic markets that feed the same learning curves. AMD's volume was initially forced by IBM's PC division mandating a second source to Intel. Apple's volume is consumer-driven. TSMC's volume is manufacturing-led. Nvidia's volume is now accelerating faster than any of them in this era. In our view, Nvidia is positioned to be the dominant volume leader of the AI era by a wide margin. And as history shows, once volume leadership is established at scale, it becomes extraordinarily difficult for competitors to catch up without other factors affecting the outcome (e.g. self-inflicted wounds or things out of the leader's control such as geopolitical shifts). Nvidia's CES announcements were visionary and focused largely on the emerging robotics market. In this analysis, however, we focused in on the core of Nvidia's systems business. In our view, what Nvidia announced in this regard exceeded even our optimistic expectations. As we've stressed often, Nvidia is remarkable, not only because of a single chip, but because of the scope of what it delivers. Specifically, Huang led this part of his keynote with a six-chip, full-system redesign built around what Huang consistently refers to as extreme co-design. The chart above shows the next generation innovations from Nvidia, including Vera Rubin, named in homage to the astronomer whose work on galactic rotation curves led to the discovery of dark matter. Vera is the CPU. Rubin is the GPU. But focusing only on those two components misses the broader story. Nvidia simultaneously advanced every major silicon element in the system including NVLink based on InfiniBand, ConnectX nics and Spectrum-X for Ethernet, BlueField DPUs and Spectrum-X Ethernet with co-packaged optics. A few years ago, the prevailing narrative suggested that Ethernet would undercut Nvidia's proprietary networking position, the underpinning which was Infiniband (via the Covid-era Mellanox acquisition). Nvidia was undeterred and responded by building Spectrum-X. Today, Jensen Huang argues that Nvidia is the largest networking company in the world by revenue, and the claim appears credible. What's striking is not the line extension itself, but the speed and completeness with which Nvidia executed it. The deeper point lies in how Nvidia defines co-design. While the company works closely with customers such as OpenAI Group PBC, Google LLC with Gemini and xAI Corp., the co-design begins internally - across Nvidia's own portfolio. This generation represents a ground-up redesign of the entire machine. Every major chip has been enhanced in coordination, not in isolation. The performance metrics are astounding. The GPU delivers roughly a fivefold performance improvement. The CPUs see substantial gains as well. But equally important are the advances in networking - both within the rack and across racks. Each subsystem was redesigned together to maximize end-to-end throughput rather than optimize any single component in isolation. The result is multiplicative, not additive. While individual elements show performance gains on the order of five times, the system-level throughput improvement is closer to an order of magnitude. That is the payoff of extreme co-design - aligning compute, networking, memory and software to minimize single bottlenecks that limit the overall system. In our view, this marks a decisive shift in how AI infrastructure is built. For quite some time we've acknowledged that Nvidia is no longer shipping chips. It is delivering tightly integrated systems engineered to maximize throughput, utilization, and economic efficiency at the scale required for AI factories. That distinction is profound as competitors attempt to match not just component performance, but the learning-curve advantages that emerge when volume, architecture and system-level design reinforce each other. While Jensen has pointed out that Nvidia is a full systems player, the point is often lost on investors and market watchers. This announcement further underscores the importance of this design philosophy and further differentiates Nvidia from any competitor. A critical point that becomes more clear from Nvidia's announcements is the chip is not the correct unit of measurement. The system is. More precisely, the rack - and ultimately the token output per rack - is what defines performance, economics, and value. Each rack integrates 72 GPUs along with CPUs and high-speed interconnects that bind the system together. Compute density is critical, but so is the ability to move data with minimal jitter and maximum consistency - within the rack, across racks, and across entire frames. Nvidia has dramatically increased memory capacity into the terabytes, enabling GPUs to operate in tight coordination without stalling. The result is coherent execution at massive scale. These systems are designed to scale up, scale out, and scale across. When deployed at full factory scale, they operate not in dozens or hundreds of GPUs, but in hundreds of thousands - eventually up to a million GPUs working together. As scale increases, so does throughput. And as throughput increases, the economic value of the tokens generated accelerates. This is where the numbers compound to create the flywheel effect. Roughly five times performance improvement at the component level combines with roughly ten times throughput at the system level. Together, they drive what we believe is an estimated 15-times increase in demand, as lower cost per token unlocks entirely new classes of workloads. This is Moore's Law on triple steroids - and it explains why annual value creation rises so sharply. The Jevons Paradox applies here. As the efficiency of token generation improves, total consumption rises. As we've stressed, the value shifts away from static measures of chip performance, toward dynamic measures of system utilization and output economics. The faster tokens can be generated, the more economically viable it becomes to deploy AI at scale, and the more demand expands. Networking is central to this equation. Nvidia's long-term investment in Mellanox - once dismissed by many as a bet on a dying technology - now looks prescient. InfiniBand continues to grow rapidly, even as Ethernet demand also accelerates. Far from being a bottleneck, networking has become a core enabler of system-level performance. The takeaway is that AI infrastructure economics are now defined at the rack and factory level, not at the chip level. Nvidia's advantage lies in designing systems where compute, memory, networking and software operate as a single, tightly coordinated machine. That is where throughput is maximized, token economics are transformed, and the next phase of AI factory value is being created. Huang presented three critical metrics on a single slide to show training throughput, AI factory token throughput and token cost. Together, they tell a story about where AI infrastructure economics are headed. For clarity, we break this into two parts as shown below: training on the left, factory and inference throughput on the right. The training chart shows time-to-train measured in months for a next-generation, ultra-large model. The takeaway is eye opening. The Rubin platform reaches the same training throughput as Blackwell using roughly one quarter of the GPUs. As we pointed out earlier, this is not simply about faster chips. It reflects dramatic gains in efficiency at scale - reduced synchronization overhead, fewer memory stalls, lower fabric contention, and shorter training cycles overall. The implications are notable. Capital required per model run drops materially. Customers can run more experiments per year and iterate faster. Training velocity becomes a competitive advantage in itself, not just a cost consideration. In our view, this is one of the most under-appreciated dynamics in the current AI race. The factory throughput chart above on the right, tells an equally important story. As workloads shift from batch inference toward interactive, agent-driven use cases, throughput characteristics change dramatically. Tokens per query increase. Latency sensitivity rises. Under these conditions, Blackwell's throughput collapses as shown. Meanwhile, Rubin sustains performance far more effectively and delivers approximately 10 times more tokens per month at the factory level. This is the future workload profile of AI factories - real-time, interactive, agentic and highly variable -- not static batch inference. Rubin is designed for this moment. The value is not just in peak performance, but in sustained throughput under real-world conditions. Taken together, these charts explain why Nvidia's advantage continues to widen. Training and inference are converging in economic importance. Faster training reduces capital intensity and accelerates innovation. Higher factory throughput lowers token costs while expanding demand. This combination resets expectations for performance, efficiency and scalability. In our view, many observers continue to underestimate both the pace at which Nvidia is moving and the magnitude of the gap it is creating. Comparisons to alternative accelerators - whether Google TPUs, AWS Trainium or others - miss the system-level reality being demonstrated by Nvidia. The new standard is not raw compute. It is training velocity, sustained factory throughput and token economics at scale. And on those dimensions, Nvidia is setting the bar. The final piece of the equation that we'll dig into is cost. And this is where the implications become overwhelming. In our view, it's what matters most. The combination of higher throughput and system-level efficiency drives cost per token down by roughly an order of magnitude. Huang framed it in his keynote saying these systems may consume more power, but they do vastly more work. When throughput rises by 10 times and cost per token falls to one-10th, the economic profile of AI factories fundamentally resets. What's striking is the pace. This is not the 18- to 24-month cadence historically associated with Moore's Law. These gains are occurring on a 12-month cycle. Moore's Law transformed the computing industry for decades, lifting productivity across silicon, software, storage, infrastructure and applications. What we are seeing now is an even more aggressive curve - orders-of-magnitude improvement compressed into a single year. There are real pressures behind this progress. Demand for advanced chips, memory and interconnects is intense, pushing up component costs. Nvidia has secured premium access across that supply chain. But from the perspective of an AI factory operator, the math dominates everything else. If cost per token falls while throughput rises dramatically, the earning power of the factory increases materially. This is especially critical in a power-constrained world as we described last August when we explored the "New Jensen's Law." Hyperscalers and neoclouds alike are limited by available power, not just capital. Under those constraints, Jensen's tongue-in-cheek "law" applies - buy more, make more; or buy more, save more. The ability to extract significantly more work from the same infrastructure -- or achieve the same output with far less -- translates directly into financial operating leverage. The example Jensen cited makes the point concrete. In a $50 billion, gigawatt-scale data center, improving utilization by 10% produces an enormous $5 billion benefit that flows straight to the income statement. That is why networking, in this context, becomes economically "free." The incremental cost is dwarfed by the utilization gains it enables. This is ultimately why Nvidia's position is so strong. The advantage is not just technical - it's economic. Nvidia is operating on a steep learning curve, reinforced by volume, system-level co-design and accelerating efficiency gains. When cost per token collapses at this rate, demand expands, utilization rises and the economics compound. That dynamic is what defines leadership in this era. We'll close by translating the CES announcements into competitive implications across multiple classes of players, including vendors that are simultaneously customers. The common theme is that the unit of competition has shifted from chips to systems, racks and ultimately token economics. That shift changes the survivability economics for incumbents, the opportunity for specialists, and the urgency of customer strategies. In our view, it's effectively game over for Intel's historical monopoly and leadership position. The more interesting question is whether Intel can remain a meaningful CPU provider in an AI factory world - and the Nvidia/Intel interoperability move is notable in that context. The historical context is relevant. Nvidia has wanted deeper access to x86 since the late 1990s but was never allowed. The new arrangement changes the structure and it enables a configuration where Intel CPUs and Nvidia GPUs can operate within the same frame. It's not a fully unified architecture, but it is sufficient for most of the work, and it creates a practical path for Intel CPUs to remain present in these systems. It also gives Intel a meaningful level of access to CUDA-based environments - short of "full access," but still consequential. The net effect should improve Intel connectivity in these deployments, keep Intel in the CPU game for this cycle, and increase the volume of Nvidia systems available to the market. In other words, it can act as a viable bridge from the old to the new, which is good for customers. We do want to flag a key risk to any optimistic Nvidia scenario - a Taiwan geopolitical disruption. If China takes over Taiwan, there are multiple potential outcomes - from continuity with a new lever for China, to a more disruptive scenario if that lever is pulled. Either would ripple through sentiment around Nvidia and could increase perceived strategic value for Intel. But the hard reality is Intel still has to close the manufacturing and execution gap with TSMC, and that is not something any company can leapfrog overnight. AMD has executed well against Intel in x86. But the competitive target has shifted. x86 is mature and its curve has flattened, which made the timing right for AMD's ascdendency and for hyperscalers to pursue alternatives such as AWS' Graviton. AMD is now taking on a very different animal - a leader moving on a steep learning curve with compounding system-level advantages. In our view, the core issue is speed. AMD will struggle to move fast enough to close a gap defined by 12-month cycles and system-level throughput economics. One practical implication is that AMD should pursue a deal structure similar to Intel's - something that secures volume on one side - while focusing aggressively on the edge. Data center CPU revenue is meaningful for Intel and AMD, but expanding volume there will be difficult, and there is real risk of decline. The edge remains wide open, and that's where focus should go in our opinion. At the same time, it's important to recognize that Nvidia is also targeting the edge - autonomous vehicle libraries were highlighted and robotics were put on stage at CES and it's a major focus of the company. The edge is open, but it won't be uncontested. There is ample room for specialists that avoid direct, frontal competition with Nvidia. The AI factory buildout is forecast to be enormous - large enough that niche and adjacency strategies can still create meaningful businesses, particularly around factories and the edge. Two examples we cite: But the strategic point is that latency is a real lever in inference economics, and specialists that win on latency can matter - especially at the edge. Broadcom is best understood as a critical supplier to hyperscalers, OEM ecosystems, mobile players and virtually all forms of connectivity. Broadcom has a custom silicon engine that manages back-end execution with foundries and manufacturing partners. Its business is diversified and structurally important, and we do not view it as going away by any means. Broadcom has deep engineering talent and a diversified business with exceptional leadership. The more controversial question is whether hyperscalers should continue investing in alternative accelerators such as TPUs, Trainium and other ASIC strategies - as a long-term path to compete with Nvidia. Google has deep history and real technical credibility with TPUs. But the argument here is that this is now a different business environment. Google must protect search quality and accelerate Gemini. If internal platform choices limit developer access to CUDA and the best available hardware/software improvements, the risk is that Gemini's development velocity slows. If model iteration takes multiples longer, that becomes strategically dangerous. Our view is that TPUs have reached a ceiling in this context - not because they can't improve, but because they cannot match Nvidia's volume-driven learning curve and system-level economics, particularly with networking as scale. A related point, made by Gavin Baker using a simplified economics example is if Google's TPU program represents a $30 billion business, and it sends a large portion of value to Broadcom (about $15 billion), one might argue for vertical integration. The counterargument here is that even if it's financially possible, it may be strategically irrational if it slows Gemini's iteration speed. The core thesis is that Google should prioritize model velocity over accelerator self-sufficiency. The same logic extends to Trainium. AWS' Graviton playbook worked because it targeted a mature, flattening x86 curve. That is not the environment in accelerators today. The pace is too fast, the curves are too steep, and the system complexity is too high. Will AWS, Google and even Microsoft continue to fund alternatives to Nvidia? Probably as use cases will emerge for more cost effective platforms. But the real strategic advantage for hyperscalers in our view lies elsewhere, especially as they face increasing competition from neoclouds. We position four frontier labs as the primary contenders: OpenAI, Anthropic PBC, Google and xAI Corp.'sGrok, with Meta Platforms Inc.treated as a second tier (with the caveat that it's unwise to count Zuckerberg out). Despite persistent negative narratives around OpenAI -- especially around financing structure and commitments -- our view is that pessimism may be misplaced. The reasoning is as follows: In short, we see the winners as OpenAI the most likely overall winner in the center, with Anthropic as the second player, and Grok highly likely to do well at the edge. Elon could also compete strongly at the edge while he backed away from the idea of building his own data center chips. An additional allocation nuance is labs aligned with Nvidia (OpenAI and X.ai) may have a better path to "latest and greatest" allocations than those pursuing tighter coupling with alternative accelerator strategies. For OEMs like Dell, HPE, Lenovo, and Supermicro, the opportunity is primarily executional. In other words, get the latest platforms, package them, deliver them, and keep them running reliably without thermal or integration failures. Demand is enormous, supply is constrained, and this is not a zero-sum game. For now they can all do well. The key point is that as long as the market remains supply-constrained, anything credible that can be produced will be consumed. That reality can justify multiple silicon suppliers from the ecosystem - even if the long-run competitive curve still favors Nvidia. On the customer side, we challenge a widely repeated narrative to "get your data house in order before you spend on AI." The view here is that this sequencing can be backwards. Our modeling suggests that over a multi-year period (for example, five years), getting onto the AI learning curve earlier can generate substantially more value than delaying until data is "clean." Even if data isn't pristine, organizations can choose a dataset, apply AI to improve it, and compound learning rather than waiting. Two additional implications are highlighted below: Our strategy recommendation is to optimize for speed and learning. Put token capacity close to data (latency matters), use tokens to improve access and data quality, then iterate through AI projects quickly - one project, learn, then the next, building a flywheel. The emphasis should be on starting from value and using intelligence to improve the systems, rather than spending years trying to perfect data first. In our view, the defining lesson of this analysis is that AI is no longer a contest of individual chips, models, or even vendors - it is a contest of learning curves, systems and economics. History shows that in platform transitions, leadership accrues to those who achieve volume, sustain execution and convert efficiency gains into expanding demand. That dynamic shaped the PC era, and it is repeating at far greater speed in the AI factory era. What differentiates this cycle is the compression of time. Improvements that once unfolded over decades are now occurring in 12-month intervals, resetting cost structures and forcing strategic decisions faster than most organizations are accustomed to making them. The implications go across silicon providers, hyperscalers, AI labs, OEMs and enterprises alike. For customers, the message is value will accrue to those who get onto the AI learning curve early, focus on throughput and token economics, and build momentum through rapid iteration rather than waiting for perfect conditions. For vendors, survival will depend less on clever alternatives and more on whether they can stay on the steepest curves without slowing themselves down. This transition will not be linear, and it will not be evenly distributed. But the direction is clear in our view. AI factories are becoming the economic engine of the next computing era, and the winners will be those who treat AI not as a feature or experiment, but as the core operating model of their business.
[8]
Nvidia CEO Huang says next generation of chips is in full production - The Economic Times
Nvidia CEO Jensen Huang said on Monday that the company's next generation of chips is in "full production," saying they can deliver five times the artificial-intelligence computing of the company's previous chips when serving up chatbots and other AI apps. In a speech at the Consumer Electronics Show in Las Vegas, the leader of the world's most valuable company revealed new details about its chips, which will arrive later this year and which Nvidia executives told Reuters are already in the company's labs being tested by AI firms, as Nvidia faces increasing competition from rivals as well as its own customers. The Vera Rubin platform, made up of six separate Nvidia chips, is expected to debut later this year, with the flagship server containing 72 of the company's graphics units and 36 of its new central processors. Huang showed how they can be strung together into "pods" with more than 1,000 Rubin chips and said they could improve the efficiency of generating what are known as "tokens" - the fundamental unit of AI systems - by 10 times. To get the new performance results, however, Huang said the Rubin chips use a proprietary kind of data that the company hopes the wider industry will adopt. "This is how we were able to deliver such a gigantic step up in performance, even though we only have 1.6 times the number of transistors," Huang said. While Nvidia still dominates the market for training AI models, it faces far more competition - from traditional rivals such as Advanced Micro Devices as well as customers like Alphabet's Google - in delivering the fruits of those models to hundreds of millions of users of chatbots and other technologies. Much of Huang's speech focused on how well the new chips would work for that task, including adding a new layer of storage technology called "context memory storage" aimed at helping chatbots provide snappier responses to long questions and conversations. Nvidia also touted a new generation of networking switches with a new kind of connection called co-packaged optics. The technology, which is key to linking together thousands of machines into one, competes with offerings from Broadcom and Cisco Systems. Nvidia said that CoreWeave will be among the first to have the new Vera Rubin systems and that it expects Microsoft , Oracle, Amazon and Alphabet to adopt them as well. In other announcements, Huang highlighted new software that can help self-driving cars make decisions about which path to take - and leave a paper trail for engineers to use afterward. Nvidia showed research about software, called Alpamayo, late last year, with Huang saying on Monday it would be released more widely, along with the data used to train it so that automakers can make evaluations. "Not only do we open-source the models, we also open-source the data that we use to train those models, because only in that way can you truly trust how the models came to be," Huang said from a stage in Las Vegas. Last month, Nvidia scooped up talent and chip technology from startup Groq, including executives who were instrumental in helping Alphabet's Google design its own AI chips. While Google is a major Nvidia customer, its own chips have emerged as one of Nvidia's biggest threats as Google works closely with Meta Platforms and others to chip away at Nvidia's AI stronghold. During a question-and-answer session with financial analysts after his speech, Huang said the Groq deal "won't affect our core business" but could result in new products that expand its lineup. At the same time, Nvidia is eager to show that its latest products can outperform older chips like the H200, which US President Donald Trump has allowed to flow to China. Reuters has reported that the chip, which was the predecessor to Nvidia's current "Blackwell" chip, is in high demand in China, which has alarmed China hawks across the US political spectrum. Huang told financial analysts after his keynote that demand is strong for the H200 chips in China, and Chief Financial Officer Colette Kress said Nvidia has applied for licenses to ship the chips to China but was waiting for approvals from the US and other governments to ship them.
[9]
NVIDIA Unveils New Open AI Models at CES 2026 & New AI Platform with 5x Speed
What if the future of AI wasn't locked behind closed doors but instead placed in the hands of developers and innovators worldwide? Below, Sam Witteveen takes you through how NVIDIA's latest breakthroughs, unveiled at CES 2026, are reshaping the landscape of artificial intelligence with 13 open AI models and the innovative Vera Rubin platform. These advancements promise to make innovative AI more accessible, scalable, and efficient than ever before, sparking excitement across industries like autonomous vehicles, robotics, and healthcare. But with such bold claims, one might wonder: is this the dawn of a truly open AI era, or just another step in NVIDIA's dominance of the AI ecosystem? In this CES 2026 announcement overview, you'll uncover how NVIDIA's innovations, like the fivefold performance boost of the Vera Rubin platform, are setting new benchmarks in AI supercomputing. From the fantastic Alpa Mayo model for self-driving cars to the Claraara models transforming healthcare, each development offers a glimpse into AI's potential to solve real-world challenges. Whether you're curious about the future of multimodal AI or how these models are already being integrated by major players like AWS and Mercedes-Benz, this breakdown will leave you questioning what's next for AI, and how soon it will arrive. NVIDIA Unveils AI Innovations Vera Rubin Platform: Redefining AI Supercomputing The Vera Rubin platform represents NVIDIA's latest advancement in AI supercomputing, designed to address the growing demands of hyperscalers and data centers. This platform delivers a fivefold performance boost compared to its predecessor, the Blackwell chips, and is specifically optimized for training mixture-of-experts models. By significantly reducing inference costs, the Vera Rubin platform offers a cost-effective solution for large-scale AI operations. Major cloud providers, including AWS, Google, Microsoft, and Oracle, have already adopted this innovative technology. Its integration into their infrastructures underscores its potential to reshape AI ecosystems, allowing faster and more efficient processing for a variety of applications. The Vera Rubin platform sets a new benchmark in AI supercomputing, offering unparalleled performance for enterprises and developers alike. Transforming Autonomous Vehicles: Alpa Mayo and Alpa SIM NVIDIA's contributions to autonomous vehicle technology are embodied in two innovative models: AlpaMayo and AlpaSIM. These models aim to enhance the capabilities of self-driving systems, making sure safer and more reliable autonomous transportation. * AlpaMayo: A reasoning model designed for self-driving cars, allowing advanced decision-making and adaptability in dynamic environments. This model allows vehicles to respond intelligently to complex scenarios, such as unpredictable traffic patterns or adverse weather conditions. * AlpaSIM: A simulation framework that integrates vision-based input and APIs, providing a robust testing environment for autonomous systems. This framework ensures that self-driving technologies are rigorously tested and refined before deployment. Mercedes-Benz is among the first automakers to integrate these technologies into its upcoming vehicle lineup. By adopting Alpa Mayo and Alpa SIM, the company is paving the way for a new era of safer, smarter, and more efficient transportation systems. NVIDIA's New Open Models Introduced at CES 2026 Expand your understanding of NVIDIA AI with additional resources from our extensive library of articles. Advancing Robotics AI: Cosmos Models and Isaac Group In the field of robotics, NVIDIA introduced the Cosmos Transfer and Cosmos Predict models, which are designed to generate synthetic training data for physical AI systems. These models accelerate the training process for robotics, allowing faster and more precise development of AI-driven machines. By reducing the time and resources required for training, the Cosmos models are driving innovation in robotics across various industries. The Isaac Group further expands NVIDIA's robotics portfolio with humanoid robot models capable of performing complex physical tasks and facilitating human-robot interactions. These models are tailored for applications in industries such as manufacturing, logistics, and healthcare, offering practical solutions for tasks that require precision and adaptability. NVIDIA's advancements in robotics AI are setting new standards for efficiency and functionality in automated systems. Transforming Healthcare with Claraara Models Healthcare remains a critical focus for NVIDIA, as demonstrated by the introduction of the Claraara models. This suite of four specialized AI models is designed to accelerate drug discovery and enhance health-related applications. By using advanced computational techniques, the Claraara models aim to transform precision medicine, offering new possibilities for medical research and treatment development. These models enable researchers to analyze vast datasets with unprecedented speed and accuracy, facilitating breakthroughs in areas such as genomics, biopharmaceuticals, and diagnostic imaging. NVIDIA's commitment to healthcare innovation underscores the fantastic potential of AI in improving patient outcomes and advancing medical science. Multimodal AI Breakthroughs: Neatron Agentic AI Models The Neatron Agentic AI models represent a significant advancement in multimodal AI, excelling in the processing and understanding of text, vision, and multimodal documents. These models are designed to handle complex data inputs, making them ideal for industries requiring real-time, multimodal AI capabilities. * RAG Embedding and Re-Ranking: This feature enhances the ability to process and analyze multimodal data efficiently, improving the accuracy and relevance of AI-driven insights. * Neotron Speech ASR: A low-latency speech recognition model optimized for real-time applications such as live captioning, meeting transcription, and in-car assistance. This model ensures seamless performance in environments where speed and accuracy are critical. By integrating these capabilities, the Neatron Agentic AI models provide a robust framework for applications in education, entertainment, and enterprise solutions, further expanding the scope of multimodal AI. Speech Recognition: Efficiency Meets Innovation NVIDIA has made significant strides in speech recognition technology with its low-latency ASR models. These models incorporate advanced caching mechanisms to minimize redundant computations, resulting in improved efficiency and reduced operational costs. By allowing local deployment, these models make speech recognition systems more accessible for a variety of applications, including transcription, voice AI, and assistive technologies. The low-latency ASR models are particularly well-suited for real-time environments, where speed and accuracy are paramount. Their ability to process speech data efficiently ensures that they can meet the demands of modern applications, from virtual assistants to live event captioning. Empowering Developers with Accessible Tools To foster innovation and collaboration, NVIDIA has made its AI models available on platforms such as Hugging Face. This integration allows developers to experiment with and incorporate these models into their workflows, promoting cross-industry collaboration and accelerating the development of AI-driven solutions. By prioritizing accessibility, NVIDIA ensures that its tools are available to a diverse range of users, from startups to large enterprises. This approach not only provide widespread access tos access to advanced AI technologies but also encourages the development of innovative applications that address real-world challenges. A New Era of AI Possibilities NVIDIA's announcements at CES 2026 reflect its unwavering dedication to advancing AI infrastructure and tools. With a focus on efficiency, scalability, and real-time capabilities, the company is driving innovation across industries such as autonomous vehicles, robotics, healthcare, and multimodal AI. The Vera Rubin platform and the suite of open AI models represent a bold step forward, empowering developers and enterprises to explore new frontiers in artificial intelligence.
[10]
Nvidia CEO Jensen Huang Says Rubin Architecture Is Now in Full Production. Here's Why That Matters.
These next-generation chips are available well ahead of expectations. The adoption of artificial intelligence (AI) has been all the rage in recent years, and the foundation for future AI proliferation has been laid. There's been a massive data center construction boom to keep up with the unprecedented demand -- yet some of the world's biggest cloud operators say they are still capacity-constrained. Put another way, the demand for AI by cloud infrastructure customers still outstrips supply. One of the biggest bottlenecks is a shortage of AI-capable chips, namely the graphics processing units (GPUs) that underpin much of AI training and inference. Chipmaker Nvidia (NVDA 0.05%) is doing its part to alleviate that shortage. At CES this week, CEO Jensen Huang announced that its "revolutionary" Rubin Architecture is already at full production -- well ahead of the original target for the second half of 2026. Let's review the details to see what this means for investors. Enter Rubin This week marked the official debut of Nvidia's Rubin Architecture, which includes a group of six chips that operate in concert. The chipmaker says these innovations "deliver up to 10x reduction in inference token cost and 4x reduction in the number of GPUs to train MoE [mixture of experts] models," compared with the current Blackwell platform. The system is built around the Vera Rubin superchip, which consists of a Vera CPU and Rubin GPU. "Vera Rubin is designed to address this fundamental challenge that we have: The amount of computation necessary for AI is skyrocketing," Huang said in his CES keynote. "Today, I can tell you that Vera Rubin is in full production." Having these next-generation AI chips available sooner than expected will be a boon to cloud and data center operators, and will likely produce a windfall for Nvidia. Indeed, the data center buildout by the major cloud operators has been continuing at breakneck speed, with no end in sight. For example, for its fiscal 2026 first quarter (ended Sept. 30, 2025), Microsoft reported that its Azure cloud growth accelerated to 40% year over year, and it was still unable to keep up with demand. On the earnings call, Microsoft CFO Amy Hood pointed out that despite escalating capital expenditures, "We now expect to be capacity constrained through at least the end of our fiscal year, with demand exceeding current infrastructure buildout, resulting in lost revenue opportunities for Azure in fiscal Q1 2026." This should be music to the ears of Nvidia investors, as it confirms that the market for the company's AI-centric chips remains strong. Furthermore, full production of the Rubin chips suggests earlier availability. That, combined with the robust demand, will ultimately result in increased sales and higher revenue for Nvidia. Moreover, at just 25 times next year's expected sales, Nvidia stock remains a compelling opportunity.
[11]
Jensen Huang Just Delivered Brilliant News to Nvidia Investors for 2026
This stock has been a winner for investors over the past few years. Nvidia (NVDA 2.46%) has been an artificial intelligence (AI) champion since the start of the AI boom. The company got into the space early, focusing the design of its chips to suit this technology, and that's resulted in a No. 1 position in the market. As a result, Nvidia's revenue has soared, and the stock price has followed as investors rushed to get in on this success story. Nvidia shares have advanced 1,100% over the past three years. Though this picture is bright, investors still look expectantly to Nvidia for signs of what's next -- and what may keep the revenue momentum going. After all, the company isn't alone in this dynamic space. It faces mounting competition from rivals such as Broadcom and Advanced Micro Devices. And it even faces the possibility that customers such as Alphabet will rely more heavily on their in-house designed chips and buy fewer Nvidia products down the road. Just this week, Nvidia chief Jensen Huang spoke at the consumer electronics event known as CES, a forum for product announcements and innovation updates, and he offered a clear picture of what's ahead for the company. In fact, Huang delivered brilliant news to Nvidia investors for 2026. Nvidia's promise First, though, it's important to take a quick look at the Nvidia story so far and a promise the company has made to customers and investors. As mentioned, Nvidia was first to market with its graphics processing units (GPUs) for AI, and this helped the company establish leadership. These GPUs drive the critical steps needed to get the AI show on the road, from the training of models to putting them to work. Nvidia didn't stop there and instead added a wide selection of related products and services to its repertoire -- and that has made it a source that customers can turn to for any of their AI needs. The company also has been proactive, designing platforms in areas such as robotics to drive the AI developments of the future. At the same time, Nvidia made a promise several quarters ago to those depending on it for technology and growth. The company pledged to update its GPUs on an annual basis, and it's followed through on that with the launch of the Blackwell architecture in late 2024 and then the Blackwell Ultra update last year. Both products met with enormous demand, generating billions of dollars for Nvidia. Jensen Huang at CES And this brings me to Huang's announcement at CES. It's as simple as this: The company's Rubin platform is in full production. That puts this next update on track for release this year, once again fulfilling Nvidia's promise. Rubin features five innovations, including the latest NVLink communications link and the Vera central processing unit (CPU). (CPUs are the main chips that power computers.) But this isn't the only chip involved. In fact, Rubin includes six chips all designed together, in a process called "extreme codesign" -- and this has resulted in tremendous gains in efficiency. This integration of chips allows Rubin to offer benefits such as reducing inference token costs by as much as 10 times, and its switch systems help Rubin to offer major improvements in power efficiency and uptime. So, this platform sounds solid -- but why is this announcement such fantastic news right now? There are three reasons. First, it's yet another example of Nvidia keeping its word and demonstrating that it can innovate and launch a major product on an annual basis. Second, innovations are key because they are what should keep Nvidia in its leadership position. It will be very difficult for a rival to beat Nvidia when new launches happen once a year. Finally, the timing of this launch may be perfect as demand charges on for training and inference. Huang even said during CES that this demand was "going through the roof." Tech giants that want to succeed in the AI race are eager to get in on the latest tools, so Rubin could be another significant revenue driver for Nvidia -- and this wave of growth may begin in 2026.
[12]
Nvidia CEO Jensen Huang calls AI titan's latest chips 'gigantic step...
Nvidia CEO Jensen Huang said Monday that the company's next generation of chips is in "full production," saying they can deliver five times the artificial-intelligence computing of the company's previous chips when serving up chatbots and other AI apps. In a speech at the Consumer Electronics Show in Las Vegas, the leader of the world's most valuable company revealed new details about its chips, which will arrive later this year and which Nvidia executives told Reuters are already in the company's labs being tested by AI firms, as Nvidia faces increasing competition from rivals as well as its own customers. The Vera Rubin platform, made up of six separate Nvidia chips, is expected to debut later this year, with the flagship device containing 72 of the company's flagship graphics units and 36 of its new central processors. Huang showed how they can be strung together into "pods" with more than 1,000 Rubin chips. To get the new performance results, however, Huang said the Rubin chips use a proprietary kind of data that the company hopes the wider industry will adopt. "This is how we were able to deliver such a gigantic step up in performance, even though we only have 1.6 times the number of transistors," Huang said. While Nvidia still dominates the market for training AI models, it faces far more competition - from traditional rivals such as Advanced Micro Devices as well as customers like Alphabet's Google - in delivering the fruits of those models to hundreds of millions of users of chatbots and other technologies. Much of Huang's speech focused on how well the new chips would work for that task, including adding a new layer of storage technology called "context memory storage" aimed at helping chatbots provide snappier responses to long questions and conversations when being used by millions of users at once. Nvidia also touted a new generation of networking switches with a new kind of connection called co-packaged optics. The technology, which is key to linking together thousands of machines into one, competes with offerings from Broadcom and Cisco Systems. In other announcements, Huang highlighted new software that can help self-driving cars make decisions about which path to take - and leave a paper trail for engineers to use afterward. Nvidia showed research about software, called Alpamayo, late last year, with Huang saying on Monday it would be released more widely, along with the data used to train it so that automakers can make evaluations. "Not only do we open-source the models, we also open-source the data that we use to train those models, because only in that way can you truly trust how the models came to be," Huang said from a stage in Las Vegas. Last month, Nvidia scooped up talent and chip technology from startup Groq, including executives who were instrumental in helping Alphabet's Google design its own AI chips. While Google is a major Nvidia customer, its own chips have emerged as one of Nvidia's biggest threats as Google works closely with Meta Platforms and others to chip away at Nvidia's AI stronghold. At the same time, Nvidia is eager to show that its latest products can outperform older chips like the H200, which President Trump has allowed to flow to China. Reuters has reported that the chip, which was the predecessor to Nvidia's current flagship "Blackwell" chip, is in high demand in China, which has alarmed China hawks across the US political spectrum.
[13]
New generation of Nvidia AI chips promises performance five times faster
Nvidia's acquisition of Groq's technology signals the company's determination to stay at the forefront of AI innovation. Nvidia's next generation of AI chips is now in full production and promises a fivefold increase in AI processing power compared to its predecessors, allowing chatbots and AI applications to run faster and more efficiently. CEO unveiled these advances at the Consumer Electronics Show in , highlighting the upcoming Vera Rubin platform. This platform consists of six chips and offers impressive capabilities, including a flagship chip with 72 graphics units and 36 processor cores. Performance improvements Huang demonstrated how the chips can be interconnected into "pods" containing more than 1,000 Rubin chips, dramatically improving the efficiency of token generation -- the building blocks of AI systems -- by a factor of ten. This remarkable performance gain is attributed to a proprietary data type that hopes will become an industry standard. While currently dominates the AI training market, competition from rivals such as and even customers like Alphabet's Google is intensifying. Huang stressed how effective the new chips are at delivering trained AI models to millions of users via chatbots and other technologies. He also pointed to "context memory," a new storage layer designed to speed up chatbot response times to complex questions and conversations. Networking breakthroughs also unveiled a new generation of network switches with co-packaged optics, a crucial technology for connecting thousands of machines into a unified system, going head-to-head with offerings from and . CoreWeave is expected to be among the first users of the Vera Rubin systems, followed by Microsoft, Oracle, Amazon and Alphabet. Among other things, Huang presented new software designed to help autonomous cars make decisions, leaving a transparent trail that engineers can analyze. He also unveiled the extended version of the software, along with the training data used, which will allow carmakers to carry out independent evaluations and strengthen confidence in the model's development. Expansion Nvidia's recent acquisition of talent and chip technology from startup Groq underscores its ambition to stay ahead in the AI landscape. The deal brings in executives who were involved in developing Google's AI chips, posing a direct challenge to Nvidia's dominant position. Huang assured analysts that the Groq deal would not affect Nvidia's core operations but could lead to new product offerings that would complement its portfolio. Want access to all our articles? Take advantage of our limited-time offer and subscribe here!
[14]
Nvidia says new chips to deliver 5x AI performance boost
Nvidia CEO Jensen Huang said Monday that the company's next generation of chips was in full production, promising to deliver five times the AI computing of earlier models. He was speaking at the annual Consumer Electronics Show in Las Vegas. It comes as the world's most valuable company faces mounting competition from rivals and its own customers. Set to launch later this year, the flagship Vera Rubin platform packs six separate Nvidia chips, with 72 graphic units and 36 new central processors. These can be linked into pods, with over a thousand Rubin chips working together. To achieve these performance gains, Huang said the hardware uses proprietary data formats that he hopes the industry will embrace. "This is completely revolutionary. This is how we were able to deliver such a gigantic step up in performance, even though we only have 1.6 times the number of transistors." The AI chip leader also introduced new features aimed at helping chatbots handle complex conversations with millions of users simultaneously. Huang also showcased new self-driving car software called Alpamayo that he said will be open-sourced. "Not only do we open source the models, we also open source the data that we use to train those models because that in that way, only in that way can you truly trust how the models came to be." The same day saw rival AMD show off its latest AI chips in Las Vegas too. It's selling them to customers including ChatGPT-maker OpenAI.
[15]
Nvidia CEO Huang says next generation of chips is in full production
LAS VEGAS, Jan 5 (Reuters) - Nvidia CEO Jensen Huang said on Monday that the company's next generation of chips is in "full production," saying they can deliver five times the artificial-intelligence computing of the company's previous chips when serving up chatbots and other AI apps. In a speech at the Consumer Electronics Show in Las Vegas, the leader of the world's most valuable company revealed new details about its chips, which will arrive later this year and which Nvidia executives told Reuters are already in the company's labs being tested by AI firms, as Nvidia faces increasing competition from rivals as well as its own customers. The Vera Rubin platform, made up of six separate Nvidia chips, is expected to debut later this year, with the flagship device containing 72 of the company's flagship graphics units and 36 of its new central processors. Huang showed how they can be strung together into "pods" with more than 1,000 Rubin chips. To get the new performance results, however, Huang said the Rubin chips use a proprietary kind of data that the company hopes the wider industry will adopt. "This is how we were able to deliver such a gigantic step up in performance, even though we only have 1.6 times the number of transistors," Huang said. While Nvidia still dominates the market for training AI models, it faces far more competition - from traditional rivals such as Advanced Micro Devices as well as customers like Alphabet's Google - in delivering the fruits of those models to hundreds of millions of users of chatbots and other technologies. Much of Huang's speech focused on how well the new chips would work for that task, including adding a new layer of storage technology called "context memory storage" aimed at helping chatbots provide snappier responses to long questions and conversations when being used by millions of users at once. Nvidia also touted a new generation of networking switches with a new kind of connection called co-packaged optics. The technology, which is key to linking together thousands of machines into one, competes with offerings from Broadcom and Cisco Systems. In other announcements, Huang highlighted new software that can help self-driving cars make decisions about which path to take - and leave a paper trail for engineers to use afterward. Nvidia showed research about software, called Alpamayo, late last year, with Huang saying on Monday it would be released more widely, along with the data used to train it so that automakers can make evaluations. "Not only do we open-source the models, we also open-source the data that we use to train those models, because only in that way can you truly trust how the models came to be," Huang said from a stage in Las Vegas. Last month, Nvidia scooped up talent and chip technology from startup Groq, including executives who were instrumental in helping Alphabet's Google design its own AI chips. While Google is a major Nvidia customer, its own chips have emerged as one of Nvidia's biggest threats as Google works closely with Meta Platforms and others to chip away at Nvidia's AI stronghold. At the same time, Nvidia is eager to show that its latest products can outperform older chips like the H200, which U.S. President Donald Trump has allowed to flow to China. Reuters has reported that the chip, which was the predecessor to Nvidia's current flagship "Blackwell" chip, is in high demand in China, which has alarmed China hawks across the U.S. political spectrum. (Reporting by Stephen Nellis in Las Vegas; Editing by Matthew Lewis)
[16]
Nvidia CEO Huang to take stage at CES in Las Vegas as competition mounts
LAS VEGAS, Jan 5 (Reuters) - Nvidia CEO Jensen Huang is set to give a speech on Monday at the Consumer Electronics Show in Las Vegas, potentially revealing new details about product plans for the world's most valuable listed company as it faces increasing competition from both rivals and its own customers. Less than two weeks ago, the company scooped up talent and chip technology from startup Groq, including executives who were instrumental in helping Alphabet's Google design its own AI chips. While Google is a major Nvidia customer, its own chips have emerged as one of Nvidia's biggest threats as Google works closely with Meta Platforms and others to chip away at Nvidia's AI stronghold. At the same time, Nvidia is eager to show that its latest products can outperform older chips like the H200, which U.S. President Donald Trump has allowed to flow to China. Reuters has reported that the chip, which was the predecessor to Nvidia's current flagship "Blackwell" chip, is in high demand in China, which has alarmed China hawks across the U.S. political spectrum. Huang's speech is scheduled to begin at 4 p.m. EST (2100 GMT). Other key speakers at the annual trade show this year include AMD CEO Lisa Su, the CEO of Finnish health tech company Oura, Tom Hale, and PC maker Lenovo's CEO, Yuanqing Yang. (Reporting by Stephen Nellis in Las Vegas; Editing by Matthew Lewis)
Share
Share
Copy Link
Jensen Huang revealed Nvidia's next-generation Vera Rubin chip at CES in Las Vegas, claiming it delivers five times the AI computing power of its predecessor Blackwell. The announcement comes as Nvidia faces mounting pressure from rivals and customers developing their own AI chips, while the company expands into autonomous vehicles, robotics, and enterprise applications.
Nvidia Introduces Vera Rubin Chip With Major Performance Gains
Jensen Huang took the stage at the Consumer Electronics Show (CES) in Las Vegas to announce that Nvidia's next generation of AI chips is in full production and ready to reshape the AI chip market. The Vera Rubin chip platform, named after the renowned American astronomer, comprises six separate Nvidia chips designed to deliver unprecedented computing power for artificial intelligence applications
1
3
. According to Huang, the new platform is 3.5 times better at training AI models and five times better at running AI software compared to its predecessor, Blackwell1
. The flagship AI supercomputer configuration, called the Vera Rubin NVL72, contains 72 Rubin graphics processing units and 36 Vera central processing units, all connected through Nvidia's proprietary NVLink networking technology3
4
.
Source: SiliconANGLE
The new central processing unit features 88 cores and provides twice the performance of the component it replaces, while the complete system can be strung together into pods containing more than 1,000 Rubin chips
1
3
. Huang emphasized that these systems will be cheaper to operate than Blackwell versions because they deliver the same results using fewer components. Microsoft and other major cloud providers will be among the first to deploy the new hardware in the second half of the year1
.
Source: Bloomberg
Addressing Increasing Competition in AI Hardware
Nvidia faces increasing competition from both traditional rivals and its own customers as the AI chip market evolves. Less than two weeks before CES, the company acquired talent and chip technology from startup Groq, including executives instrumental in helping Google design its own AI chips
2
3
. While Google remains a major Nvidia customer, its proprietary chips have emerged as one of Nvidia's biggest threats as the search giant works closely with Meta Platforms and others to challenge Nvidia's dominance2
. Traditional competitors like Advanced Micro Devices also continue to pressure Nvidia's market position3
.During a question-and-answer session with financial analysts, Huang addressed the Groq acquisition, stating it "won't affect our core business" but could result in new products that expand Nvidia's lineup
3
. The company is also navigating geopolitical challenges, with Chief Financial Officer Colette Kress confirming strong Chinese demand for the H200 chip, which the Trump administration has said it will consider allowing Nvidia to ship to China1
. License applications have been submitted, and regardless of approval levels, Kress said Nvidia has enough supply to serve Chinese customers without impacting shipments elsewhere1
.Multimodal AI and Context Memory Storage Innovations
Huang painted a vision of multimodal AI systems that can understand speech, images, text, videos, and 3D graphics across multiple deployment models
4
. He described his realization that AI needs to be multimodel in nature, citing Perplexity's use of multiple large language models to achieve the most accurate results. "Of course, in AI, we would call upon all the world's greatest AI models to answer different questions at various points in the reasoning chain," Huang explained4
.Nvidia introduced Context Memory Storage, a new storage architecture designed specifically for the AI era that addresses inference workloads more efficiently than traditional storage tiers
4
. The technology helps chatbots provide faster responses to long questions and conversations by turning key-value cache into a shareable platform resource3
4
. The company also announced new networking switches with co-packaged optics, competing directly with offerings from Broadcom and Cisco Systems3
.Related Stories

Expanding Into Robotics and Autonomous Vehicles
Jensen Huang showcased Nvidia's expansion beyond data centers into physical AI applications, including self-driving cars and robotics. The company demonstrated new AI software called Alpamayo that helps autonomous vehicles make navigation decisions while leaving a paper trail for engineers to analyze afterward
3
. "Not only do we open-source the models, we also open-source the data that we use to train those models, because only in that way can you truly trust how the models came to be," Huang stated3
.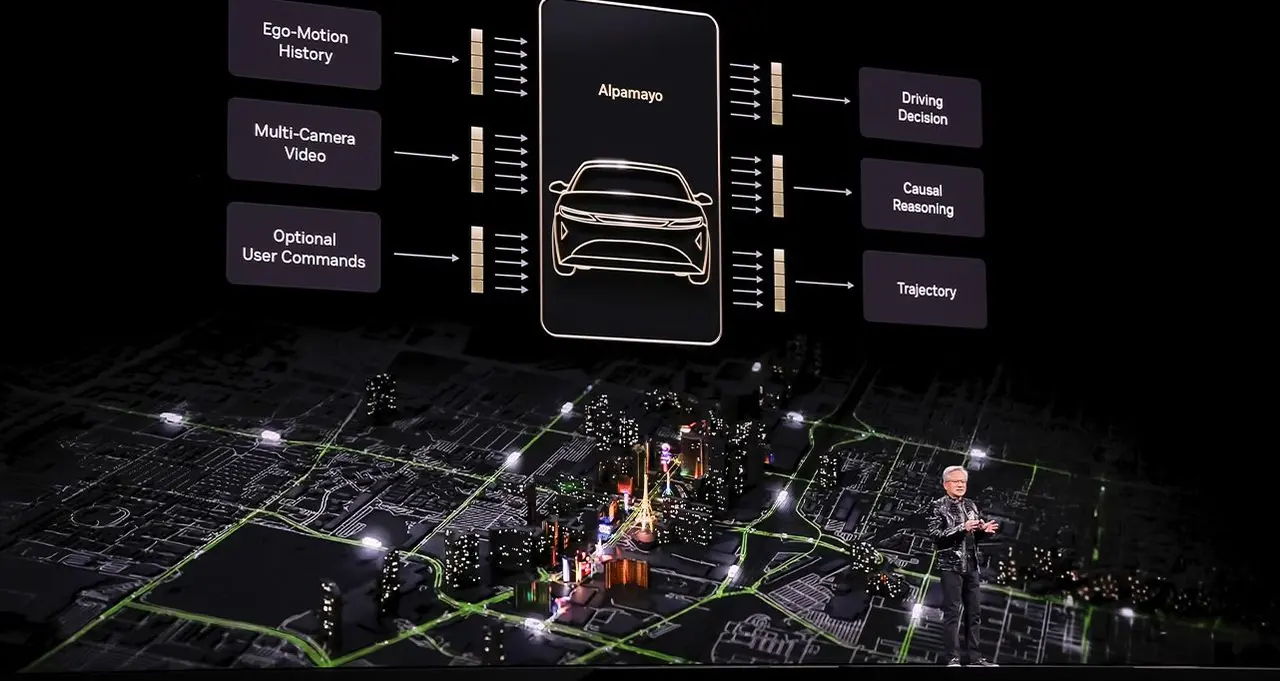
Source: SiliconANGLE
Nvidia detailed its partnership with Mercedes-Benz, which uses the company's autonomous vehicle software, with the first autonomous car powered by Nvidia technology set to hit U.S. roads in the first quarter before expanding to Europe and Asia
5
. Huang envisions a future where "a billion cars on a road will all be autonomous," whether through robotaxis or personally owned self-driving vehicles5
. The company also highlighted applications in robotics of all sizes, from food delivery robots to surgical machines5
.The Future of AI and Nvidia's Market Position
Nvidia reported record revenue of $57 billion in the third quarter, up 62% year-over-year, and secured $500 billion in orders for AI chips through 2026
5
. The company became the first to surpass a $5 trillion market value, cementing its position as the world's most valuable company5
. Analysts suggest that even if concerns about an AI bubble materialize, Nvidia will continue to dominate the high-end AI chip market. "Nvidia is going to do just fine," said Gil Luria, head of technology research at D.A. Davidson5
.The company is pursuing partnerships across industries, including an expanded collaboration with Siemens to integrate AI into industrial workflows and a new partnership with Universal Music Group for AI-powered music discovery and creation
5
. Huang emphasized that agentic agents will become the primary interface for work tasks, citing implementations at ServiceNow, Palantir Technologies, and Snowflake that could eliminate up to 40% of time workers currently spend managing rather than doing actual work4
. The majority of spending on Nvidia-based systems currently comes from capital expenditure budgets of Microsoft, Alphabet's Google Cloud, and Amazon's AWS, but the company is actively working to broaden AI adoption across healthcare, heavy industry, and other sectors1
.References
Summarized by
Navi
[3]
[4]
[5]
Related Stories
Nvidia CEO Jensen Huang Unveils "Agentic AI" Vision at CES 2025, Predicting Multi-Trillion Dollar Industry Shift
07 Jan 2025•Technology

Nvidia unveils Rubin platform and physical AI models, igniting Wall Street optimism for future
06 Jan 2026•Technology

Nvidia's GTC 2025: Ambitious AI Advancements Amid Growing Challenges
15 Mar 2025•Business and Economy

Recent Highlights



Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.