AMD unveils Helios rack-scale AI system with 72 MI455X accelerators and 256-core EPYC Venice
7 Sources
7 Sources
[1]
AMD touts Instinct MI430X, MI440X, and MI455X AI accelerators and Helios rack-scale AI architecture at CES -- full MI400-series family fulfills a broad range of infrastructure and customer requirements
Artificial intelligence is arguably the hottest technology around, so it's not surprising that AMD used part of its CES keynote to reveal new information about its upcoming Helios rack-scale solution for AI as well as its next-generation Instinct MI400-series GPUs for AI and HPC workloads. In addition, the company is rolling out platforms designed to wed next-generation AI and HPC accelerators with existing data centers. Helios is AMD's first rack-scale system solution for high-performance computing deployments based on AMD's Zen 6 EPYC 'Venice' CPU. It packs 72 Instinct MI455X-series accelerators with 31 TB of HBM4 memory in total with aggregate memory bandwidth of 1.4 PB/s, and it's meant to deliver up to 2.9 FP4 exaFLOPS for AI inference and 1.4 FP8 exaFLOPS for AI training. Helios has formidable power consumption and cooling requirements, so it is meant to be installed into modern AI data centers with sufficient supporting infrastructure. Beyond the MI455X, AMD's broader Instinct MI400X family of accelerators will feature compute chiplets produced on TSMC's N2 (2nm-class) fabrication process, making them the first GPUs to use this manufacturing technology. Also, for the first time the Instinct MI400X family will be split across different subsets of the CDNA 5 architecture. The newly disclosed MI440X and MI455X are set to be optimized for low-precision workloads, such as FP4, FP8, and BF16. The previously disclosed MI430X targets both sovereign AI and HPC, thus it fully supports FP32 and FP64 technical computing and traditional supercomputing tasks. By tailoring each processor to a specific precision envelope, AMD can eliminate redundant execution logic and therefore improve silicon efficiency in terms of power and costs. The MI440X powers AMD's new Enterprise AI platform, which is not a rack-scale solution but a standard rack-mounted server with one EPYC 'Venice' CPU and eight MI440X GPUs. The company positions this system as an on-premises platform aimed at enterprise AI deployments that is designed to handle training, fine-tuning, and inference workloads while maintaining drop-in compatibility with existing data-center infrastructure in terms of power and cooling and without any architectural changes. Furthermore, the company will offer a sovereign AI and HPC platform based on Epyc 'Venice-X' processors with additional cache and extra single-thread performance as well as Instinct MI430X accelerators that can process both low-precision AI data as well as high-precision HPC workloads. The Instinct MI430X, MI440X, and MI455X accelerators are expected to feature Infinity Fabric alongside UALink for scale-up connectivity, thus making them the first accelerators to support the new interconnect. However, practical UALink adoption will depend on ecosystem partners such as Astera Labs, Auradine, Enfabrica, and Xconn. If these companies deliver UALink switching silicon in the second half of 2026, then we are going to see Helios machines interconnected using UALink. In the absence of such switches, UALink-based systems will use UALink-over-Ethernet (which is not exactly a way UALink was meant to be used) or stick to traditional mesh or torus configurations rather than large-scale fabrics. As for scale-out connectivity, AMD plans to offer its Helios platform with Ultra Ethernet. Unlike UALink, Ultra Ethernet can rely on existing network adapters, such as AMD's Pensando Pollara 400G and the forthcoming Pensando Vulcano 800G cards that can enable advanced connectivity in data centers that can already use the latest technology.
[2]
Unpacking AMD's latest datacenter CPU and GPU announcements
AMD boasts 1000x higher AI perf by 2027 and pulls the lid off Helios compute tray ahead of 2H 2026 launch AMD teased its next-generation of AI accelerators at CES 2026, with CEO Lisa Su boasting the the MI500-series will deliver a 1,000x uplift in performance over its two-year-old MI300X GPUs. That sounds impressive, but, as usual, the devil is in the details. In a press release that followed Monday's keynote, AMD clarified those estimates are based on a comparison between an eight-GPU MI300X node and an MI500 rack system with an unspecified number of GPUs. That's not exactly an apples-to-apples comparison. The math works out to eight MI300Xs that are 1000x less powerful than X-number of MI500Xs. And since we know essentially nothing about the chip besides that it'll ship in 2027, pair TSMC's 2nm process tech with AMD's CDNA 6 compute architecture, and use HBM4e memory, we can't even begin to estimate what that 1000x claim actually means. Calculating AI performance isn't as simple as counting up the FLOPS. It's heavily influenced by network latency, interconnect and memory bandwidth, and the software used to distribute the workloads across clusters. These factors affect LLM inference performance differently than training or video generation. Therefore, greater than 1000x therefore could mean anything AMD wants it to. Having said that, if AMD wants to stay competitive with Nvidia, the MI500-series will need to deliver performance on par with if not better than Nvidia's Rubin Ultra Kyber racks. According to Nvidia, when the 600kW systems make their debut next year, they'll deliver 15 exaFLOPS of FP4 compute, 5 exaFLOPS of FP8 for training, 144 TB of HBM4e, and 4.6 PB/s of memory bandwidth. Details on the MI500 may be razor thin, but we're starting to get a better picture of what AMD's MI400 series GPUs and rack systems will look like. At CES, AMD revealed MI400 would be offered in at least three flavors: For the AI crowd, AMD's MI455X-powered Helios racks are the ones to watch, as OpenAI, xAI, and Meta are expected to deploy them at scale. Each of these accelerators promise around 40 petaFLOPS of dense FP4 inference performance or 20 petaFLOPS of FP8 for training, and 432 GB of HBM4 good for 19.6 TB/s and 3.6 TB/s of interconnect bandwidth for chip-to-chip communications. Presumably, these chips will support higher precision datatypes commonly used in training and image models, but AMD has yet to spill the beans on those figures. At the very least, we now know what the chip will look like. On stage, Su revealed the MI455X package, which will use 12 3D-stacked I/O and compute dies fabbed on TSMC's 2 nm and 3 nm process nodes. All will be fed by what to our eyes appears to be 12 36 GB HBM4 stacks. Helios will employ 72 of these chips with one Epyc Venice CPU for every four GPUs forming a node. Speaking of Venice, at CES we also got our best look yet at AMD's highest-core-count Epyc ever. The chips will be available with up to 256 Zen 6 cores and will feature twice the memory and GPU bandwidth compared to last gen. By GPU bandwidth, we assume AMD is talking about PCIe lanes, which tells us that we're looking at 128 lanes of PCIe 6.0 connectivity. To double the memory bandwidth over Turin, meanwhile, we estimate AMD will need 16 channels of DDR5 8800. To fit that many cores into a single chip, Venice appears to use a new packaging technique with what looks like eight 32-core chiplets and two I/O dies. There also appear to be eight tiny chiplets on either side of the I/O chipsets, though it isn't immediately obvious what purpose they serve. We don't know yet whether the version of Venice Su was holding in her keynote is using one of AMD's compact or frequency-optimized cores. Since at least 2023, AMD has offered two versions of its Zen cores: a larger, higher-clocking version and a smaller, more compact version that doesn't clock as high. While that might sound an awful lot like Intel's E-cores, both AMD's Zen and Zen C cores use the same microarchitecture. Intel's E-cores use a different architecture and cache layout from its P-cores. As a result, they often lack advanced functionality like AVX-512 and matrix accelerators. The only differences between AMD's cores is one can be packed more densely with 16 cores per core complex die (CCD) versus eight, operating at lower frequencies with slightly less cache per core. If AMD can address the latter point, there may not be a need to differentiate between the two in the Zen 6 generation. We'll just have high-core count SKUs that don't clock as high as the lower-core-count versions like they always have. Alongside the "standard" Venice SKUs, AMD is once again offering an "X" variant of the part for high performance computing. AMD's X chips have historically featured 3D-stacked cache dies located under or on top of the CCD, boosting the L3 cache significantly. Genoa-X, AMD's last datacenter X chip could be kitted out with more than a terabyte of L3 in its highest-end configuration. We don't have a lot more information on AMD's next-gen networking stack, but we know that alongside the new CPUs and GPUs, Helios will also feature two new NICs from its Pensando division for rack-to-rack communications across the cluster. This includes up to twelve 800 Gbps Volcano NICs (three per GPU) which form the scale-out compute fabric -- what we call the backend network that allows workloads to be distributed across multiple nodes or in this case racks. The systems will also feature Pensando's Solina data processing unit, which is designed to offload things like software-defined networking, storage, and security so the CPUs and GPUs can focus on generating tokens or training models. To stitch Helios's 72 GPUs into one great big accelerator, AMD is using Ultra Accelerator Link (UALink) -- an open alternative to Nvidia's NVLink -- tunneled over Ethernet. At least for HPE's implementation of the rack, Broadcom's Tomahawk 6 will handle switching. There are only so many ways to connect the chips, but at 102.4 Tbps, we estimate AMD will need 12 Tomahawk 6 ASICs spread across six switch blades. Earlier renderings of Helios appeared to show five switch blades which threw us for a bit of a loop, but we've since learned the actual racks will feature six. Combined, the Helios rack's 72 GPUs promise to deliver 2.9 exaFLOPS of dense FP4 performance, 1.4 exaFLOPS at FP8, 31 TB of HBM4, and 1.4 PB/s of memory bandwidth. That puts it in the same ballpark and in some cases faster than Nvidia's newly unveiled Vera Rubin NVL72 rack systems, which we looked at earlier this week. And if you're not ready to drop a few million bucks on a rack-scale system, AMD will also offer the MI440X in an eight-way configuration that, from what we've gathered, will use the same OAM form factor as the MI355X and MI325X. These systems will compete with Nvidia's Rubin NVL8 boxes which pair eight GPUs with an x86-based compute platform for space in the enterprise. For all the fervor around rackscale, AMD expects this form factor to remain quite popular with enterprise customers that can't, for one reason or another, run their models in the cloud or access them via a remote API. While we don't have all the details just yet, it looks like AMD won't just be competing with Nvidia on AI performance, but on HPC perf as well. The MI430X will feature the same load out of HBM4 as the MI455X at 432 GB and 19.6 TB/s. But where MI455X is all about AI, the MI430X will use a different set of chiplets, giving it the flexibility to run at either FP64 or FP32 for HPC, FP8 or FP4 for AI, or a combination of the two as is quickly becoming the fashion. Much like with the MI440X, AMD hasn't disclosed the floating point perf of the MI430X, but using publicly available information, the wafer wizards at Chips and Cheese suggest it could be north of 200 teraFLOPS. Whatever the chip's actual floating point performance actually ends up being, we know it'll be achieved in hardware. This sets AMD apart from Nvidia, which is relying on emulation to boost FP64 performance of its Rubin GPUs to 200 teraFLOPS. We expect AMD will have more to share on its Venice CPUs and the rest of its MI400-series accelerators closer to launch, which is expected sometime in the second half of 2026. ®
[3]
Helios AI rack can reach 2.9 FP4 exaflops of compute power: AMD
From AI companies to automotive manufacturing, AMD is working across the board to power the world with AI. Chipmaker AMD announced a slew of products during the inaugural keynote at CES2026, focusing on all three facets of AI deployment: the cloud, PCs, and the edge. The highlight of the evening was the Helios AI rack capable of performing 2.9 quintillion calculations every second, powered by the MI455 series of chips, which was also unveiled during the event. As a consumer-facing expo, CES 2026 was expected to delve deeply into AI this year, and it will likely not disappoint. During the keynote, AMD CEO Lisa Su spoke to the CEOs of companies deploying AMD's infrastructure to build large language models, multimodal models, healthcare applications, and gaming worlds.
[4]
CES 2026: AMD Just Showed Off 'Helios,' the Hardware That Will Power the AI Content in Your Feeds
The announcement comes as AI and AI data centers alike are under fire from critics for misinformation and impact on local communities. When you come across an AI video on Instagram, or watch ChatGPT respond to your query, do you ever think about how that content was generated? Beyond the actual programs and prompts, generative AI takes an enormous amount of compute to support, especially as it skyrockets in popularity. As such, AI companies are looking for more power than ever, which means, of course, turning to those that make the hardware. During a Monday evening keynote, AMD's CEO Dr. Lisa Su showed off the hardware that will soon power everything from ChatGPT to the AI videos overwhelming your feeds. Su introduced "Helios" against a backdrop of dramatic music, the company's upcoming AI rack, that packs a staggering amount of computing power into a rack that weighs nearly 7,000 pounds. Each "cross-section" of these racks, if you will, is powered by four key AMD pieces of hardware: The company's new AMD Instinct MI455X GPU, the new AMD EPYC "Veince" CPU, the AMD Pensando "Vulcano" 800 AI NIC, and the AMD Pensando "Salina" 400 DPU. There are some staggering stats here: Helios is capable of 2.9 exaflops of AI compute, and comes with 31 TB of HBM4 memory. It offers 43 TB per second scale out Bandwidth, and is developed with 2nm and 3nm architecture. The rack has 4,600 "Zen 6" CPU cores, and 18,000 GPU compute units. In other words, this isn't your average piece of hardware. Su's pitch is that the AI industry is in need of this additional compute power. She notes how the world used one ZettaFlop of computing power in 2022 on AI technology, compared to 100 ZettaFlops in 2025. (For the curious, one ZettaFlop has a value of 10 to the power of 21.) It's no surprise: AI is everywhere, and many of us are using it -- whether we know it or not. Some of us are using it overtly, generating AI videos or running chatbots daily. But others are using AI quietly embedded in functions, like live translation. Su welcomed reps from OpenAI, maker of ChatGPT, and Luma AI, which creates generative AI video content, to talk about how additional compute helps their programs. But during Luma AI's demonstration of its hyperrealistic video generations, all I could think about was how this type of content is already tricking people into thinking its real, when it's entirely fabricated -- not to mention the impact on human artists. AMD is optimistic about AI, and the data centers powering it, but critics have been pushing back, citing concerns with the impacts on the communities companies are building these data centers in. Helios will likely be a major success for AMD, but it comes at an interesting time for tech, and AI in general. AI is more popular than ever, but it's also more controversial than ever. I see hardware like Helios only fueling the fire in both directions. In addition to Helios, Su announced the AMD Ryzen AI 400 series. These newest chips comes with either 12 "Zen 5" CPU cores and 24 threads, 16 RDNA 3.5 GPU cores, a 60 TOPS XDNA 2 NPU, and memory speeds of 8,533 MT/s. AMD says the Ryzen AI 400 series is 1.7 times faster at content creation and 1.3 times faster at multitasking whe compared to Intel Core Ultra 9 288V. These new chips will ship soon in a number of major PC brands, including Acer, Asus, Dell, HP, Lenovo, Beelink, Colorful, Gigabyte, LG, Mechrevo, MSI, and NEC.
[5]
AMD unveils 256-core EPYC Venice for Helios MI455X AI racks platform
AMD used its CES 2026 stage time to connect two major data center themes: next-generation EPYC server CPUs and rack-scale AI infrastructure built around Instinct accelerators. During the event, CEO Dr. Lisa Su held up the upcoming EPYC "Venice" processor and framed it as the host CPU for the company's 2026 "Helios" AI rack design, which is described as being powered by Instinct MI455X GPUs. The configuration outlined for each compute node is a familiar AI-server formula: multiple accelerators per node, with a single high-throughput CPU responsible for memory, I/O, and system-level orchestration. The most attention-grabbing detail is the described Venice configuration: 256 cores and 512 threads in a single processor package. The chiplet breakdown discussed alongside the preview points to a design that departs from current EPYC layouts, with up to eight compute chiplets (CCDs) flanking centralized I/O silicon. Each CCD is described as a 2 nm component carrying 32 "Zen 6" cores, which implies AMD is pursuing a significant CCD-level density increase to reach the 256-core ceiling without requiring an excessive number of chiplets. At the same time, the preview leaves an important technical question unanswered: whether those 32-core CCDs use full-sized Zen 6 cores intended to sustain higher clock speeds, or a dense-core approach closer to Zen 6c, where ISA compatibility and IPC characteristics remain comparable but maximum frequency is lower. In accelerator-heavy nodes, dense cores can be an effective choice when CPU duties skew toward feeding GPUs and managing data flow rather than carrying the primary compute load. However, if AMD expects Venice to handle more CPU-side work per node, core type and frequency behavior become more critical. Memory and I/O appear to be central to the package redesign. Venice is described as featuring a 16-channel DDR5 memory interface (32 sub-channels), a step that aligns with the kind of per-socket bandwidth needed to support multi-accelerator configurations. That memory width also helps explain why the package is described as using two server I/O dies rather than one. Splitting the sIOD into two dies can simplify physical routing and distribute memory controllers and high-speed interfaces more evenly across the substrate, while keeping the platform scalable. Beyond memory, Venice is expected to expand PCIe and CXL connectivity relative to today's EPYC platforms. A node configuration built around four high-bandwidth AI GPUs also needs room for additional devices such as DPUs and very high-speed network adapters, including 800G-class NICs. In practice, the value of Venice in a Helios-style rack will be determined by how well it removes bottlenecks: enough memory bandwidth to avoid starvation, enough lanes and fabric bandwidth to keep data moving, and enough platform headroom to scale across racks and clusters.
[6]
AMD shows off next-gen Zen 6-based EPYC 'Venice CPU, Instinct MI455X GPU for Helios AI racks
TL;DR: AMD unveiled its next-gen 2nm EPYC "Venice" CPUs with Zen 6 cores and Instinct MI455X AI accelerators in the Helios AI rack, delivering up to 2.9 Exaflops, 31TB HBM4 memory, and advanced liquid cooling. This platform targets high-performance AI workloads with industry-leading compute power and efficiency. AMD has just shown off its next-gen world-first 2nm EPYC "Venice" CPU with Zen 6 cores, and its Instinct MI455X AI accelerator, ready for its next-gen Helios AI racks. The company unveiled its new Helios AI rack at its recent Financial Analysts Day 2025, promising some more performance numbers with class-leading performance and efficiency for AI workloads of the future. The new AMD Helios AI rack features a full liquid-cooled design with 4 x Instinct MI455X AI GPUs and a single Zen 6-based EPYC "Venice" CPU. Helios AI racks use AMD's new Pensando "Salina" 400 DPU and Pensando "Vulcano" 800 AI NIC for networking and interconnection. AMD's next-gen EPYC "Venice" CPUs come with up to 256 cores based on the Zen 6c architecture, and each Instinct MI455X AI GPU packs a ton of GPU cores and next-gen HBM4 memory. AMD can scale its Helios AI rack with up to 2.9 Exaflops of AI compute power, 31TB of total HBM4 memory, 43TB/sec of scale-out bandwidth, and up to 4600 CPU cores and over 18,000 GPU cores. In the above photo is the chip for the Instinct MI455X, which is absolutely huge with two gigantic GCDs (Graphics Compute Dies) and two MCDs (Memory Controller Dies), with 16 x HBM4 sites. It's absolutely massive when you see it in someone's hand -- in this case, AMD boss Dr. Lisa Su. AMD has positioned its new Instinct MI400 series with NVIDIA's upcoming Vera Rubin AI platform, with the MI450X series AI accelerators featuring up to 40 PFLOPs of FP4, 20 PFLOPs of FP8 compute performance, 432GB of HBM4 memory with up to 19.6 TB/s bandwidth per chip, 3.6TB/s scale-up, and 300GB/s scale-out bandwidth.
[7]
AMD CEO Shows Off Worlds First 2nm Chips For Next-Gen Helios AI Rack: Venice "Zen 6" CPU & Instinct MI455X GPU
AMD has shown off its next-gen and the world's first 2nm EPYC Venice "Zen 6" CPU & Instinct MI455X, designed for Helios AI Racks. AMD Dives Into The 2nm Era With Next-Gen EPYC Venice "Zen 6" CPU & Instinct MI455X GPU, Built For Helios AI Rack AMD has finally shown off the world's first 2nm chips, which will power its next-generation AI capabilities on the Helios AI Rack. The Helios AI rack was first unveiled at the most recent Financial Analyst Day 2025, and the company promised some big performance figures with class-leading numbers and efficiency for AI workloads. The Helios rack is a fully liquid-cooled design that features four Instinct MI455X GPUs and a single EPYC Venice "Zen 6" CPU. The system leverages AMD's Pensando "Salina" 400 DPU, & the Pensando "Vulcano" 800 AI NIC for networking and interconnection. Each Zen 6 CPU comes with up to 256 cores based on the Zen 6C architecture, and each Instinc MI455X GPU packs several thousand compute units. The Helios rack scales up to 2.9 Exaflops of AI compute, 31 TB of HBM4 memory, 43 TB/s of scale-out bandwidth, and up to 4600 CPU + 18,000 GPU cores. Besides the rack and tray details, AMD CEO, Dr. Lisa Su, held the company's and the world's first 2nm chips. The MI455X GPU comes with two massive GCD (Graphics Compute Dies), two MCD (Memory Controller Dies), and a total of 16 HBM4 sites. The chip is as massive as it gets. The other chip is the EPYC Venice "Zen 6" CPU, now packing 8 massive Zen 6C CCDs and two IODs, along with smaller chiplets with management controllers. AMD is also prepping a full portfolio of data center solutions based on its EPYC Venice, MI400, & Vulcano interconnect. The solutions include a 72 GPU Rack for Hyperscale AI, an 8 GPU Enterprise AI solution with Instinct MI440X GPUs, and for Hybrid Compute, AMD is confirming its EPYC Venice-X CPUs with updated 3D V-Cache and MI430X (FP64-optimized GPUs). Follow Wccftech on Google to get more of our news coverage in your feeds.
Share
Share
Copy Link
AMD revealed its Helios rack-scale AI system at CES, featuring 72 Instinct MI455X accelerators with 31 TB of HBM4 memory and delivering 2.9 FP4 exaflops for AI inference. The system pairs with AMD's 256-core EPYC Venice CPUs and targets hyperscalers like OpenAI, xAI, and Meta. AMD also introduced the MI400-series family, including MI430X for HPC and MI440X for enterprise deployments.
AMD Introduces Helios Rack-Scale AI System at CES
AMD used its CES keynote to unveil Helios, the company's first rack-scale AI system designed to meet the escalating compute demands of generative AI applications. CEO Lisa Su presented the hardware against a backdrop that emphasized the scale of AI's growth, noting that the world used one zettaflop of computing power on AI in 2022 compared to 100 zettaflops in 2025
4
. The Helios AI rack packs 72 Instinct MI455X accelerators with 31 TB of HBM4 memory and aggregate memory bandwidth of 1.4 PB/s, delivering up to 2.9 FP4 exaflops for AI inference and 1.4 FP8 exaflops for AI training1
. Each rack weighs nearly 7,000 pounds and features 4,600 Zen 6 CPU cores and 18,000 GPU compute units4
. OpenAI, xAI, and Meta are expected to deploy these systems at scale2
, positioning AMD to compete directly with Nvidia in the hyperscale AI market.
Source: Lifehacker
MI455X and the Broader MI400-Series Family
The MI455X accelerator at the heart of Helios represents a significant architectural leap for AMD. Lisa Su revealed the chip package on stage, showing 12 3D-stacked I/O and compute dies fabricated on TSMC's 2nm and 3nm process nodes, fed by what appears to be 12 36 GB HBM4 stacks
2
. Each MI455X promises around 40 petaFLOPS of dense FP4 inference performance or 20 petaFLOPS of FP8 for training, with 432 GB of HBM4 delivering 19.6 TB/s and 3.6 TB/s of interconnect bandwidth for chip-to-chip communications2
. The broader Instinct MI400X family features compute chiplets produced on TSMC's N2 fabrication process, making them the first GPUs to use this manufacturing technology1
. For the first time, the MI400X family splits across different subsets of the CDNA 5 architecture, with the MI440X and MI455X optimized for low-precision AI workloads such as FP4, FP8, and BF16, while the MI430X targets both sovereign AI and HPC with full FP32 and FP64 support1
. This tailored approach allows AMD to eliminate redundant execution logic and improve silicon efficiency.EPYC Venice Powers Helios Infrastructure
Helios employs AMD's next-generation EPYC Venice CPU, with one Venice processor for every four MI455X GPUs forming a compute node
2
. The most striking detail is Venice's configuration: 256 cores and 512 threads in a single processor package5
. The chiplet breakdown points to a design using up to eight compute chiplets flanking centralized I/O silicon, with each CCD carrying 32 Zen 6 cores on a 2nm process5
. Venice features a 16-channel DDR5 memory interface with 32 sub-channels, and the platform is expected to deliver twice the memory bandwidth and GPU bandwidth compared to previous generations2
. This likely translates to 128 lanes of PCIe 6.0 connectivity and DDR5 8800 memory support2
. The package uses two server I/O dies rather than one, simplifying physical routing and distributing memory controllers and high-speed interfaces more evenly across the substrate5
.
Source: Guru3D
Connectivity and Ecosystem Considerations
The MI430X, MI440X, and MI455X AI accelerators are expected to feature Infinity Fabric alongside UALink for scale-up connectivity, making them the first accelerators to support the new interconnect
1
. However, practical UALink adoption depends on ecosystem partners such as Astera Labs, Auradine, Enfabrica, and Xconn delivering UALink switching silicon in the second half of 20261
. Without these switches, UALink-based systems may need to rely on UALink-over-Ethernet or traditional mesh configurations. For scale-out connectivity, AMD plans to offer Helios with Ultra Ethernet, leveraging existing networking adapters like AMD's Pensando Pollara 400G and the forthcoming Pensando Vulcano 800G cards1
.Related Stories

Enterprise and Sovereign AI Platforms
Beyond Helios, AMD introduced platforms tailored for different deployment scenarios. The MI440X powers AMD's new Enterprise AI platform, a standard rack-mounted server with one EPYC Venice CPU and eight MI440X GPUs designed for on-premises enterprise AI deployments
1
. This system maintains drop-in compatibility with existing data centers in terms of power and cooling requirements. AMD will also offer a sovereign AI and HPC platform based on EPYC Venice-X processors with additional cache and extra single-thread performance, paired with Instinct MI430X accelerators that can process both low-precision AI data and high-precision HPC workloads1
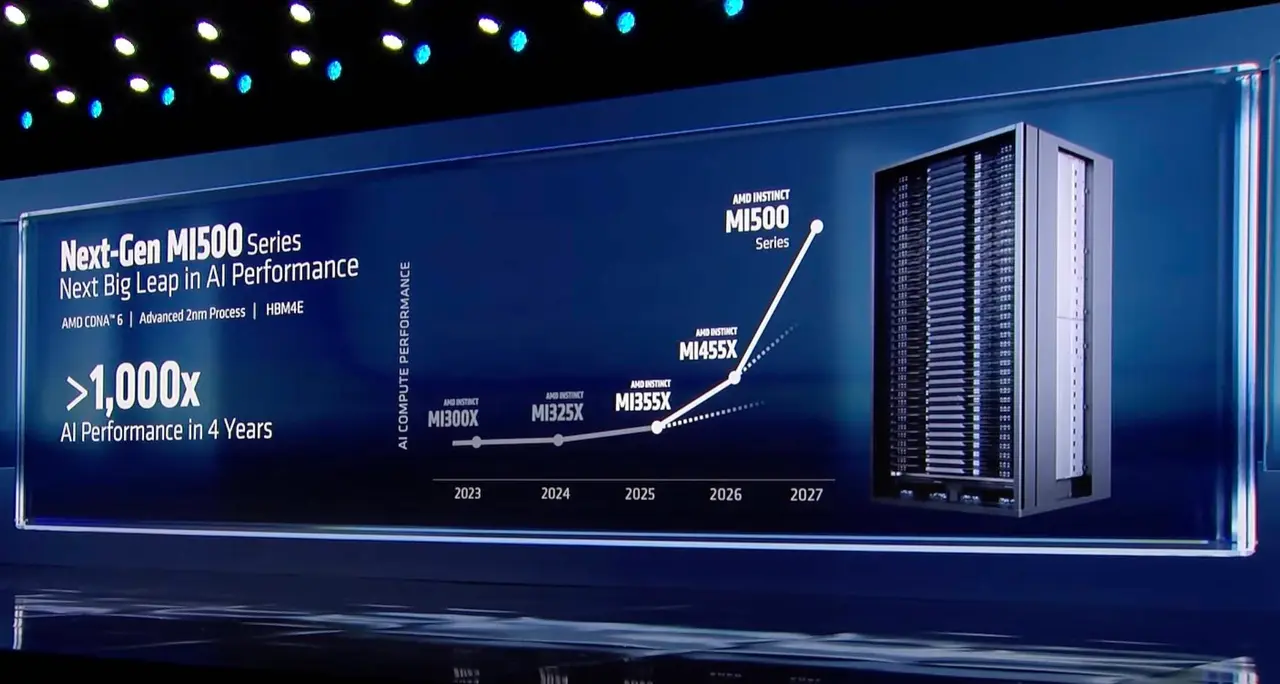
.Looking Ahead to MI500 and Competitive Landscape
AMD also teased its next-generation MI500-series accelerators, with Lisa Su claiming a 1,000x uplift in performance over the two-year-old MI300X GPUs
2
. However, AMD clarified these estimates compare an eight-GPU MI300X node to an MI500 rack system with an unspecified number of GPUs2
. The MI500-series will ship in 2027, pairing TSMC's 2nm process with AMD's CDNA 6 compute architecture and HBM4e memory2
. To remain competitive with Nvidia, the MI500-series will need to match or exceed Nvidia's Rubin Ultra Kyber racks, which promise 15 exaflops of FP4 compute, 5 exaflops of FP8 for training, 144 TB of HBM4e, and 4.6 PB/s of memory bandwidth2
. The announcements come as AI infrastructure faces scrutiny over power consumption, environmental impact, and the proliferation of AI-generated content that critics argue spreads misinformation4
.
Source: The Register
References
Summarized by
Navi
[2]
[3]
[4]
Related Stories
AMD Unveils Ambitious AI Plans: EPYC 'Venice' CPU with 256 Cores and Next-Gen AI Solutions for 2026-2027
13 Jun 2025•Technology
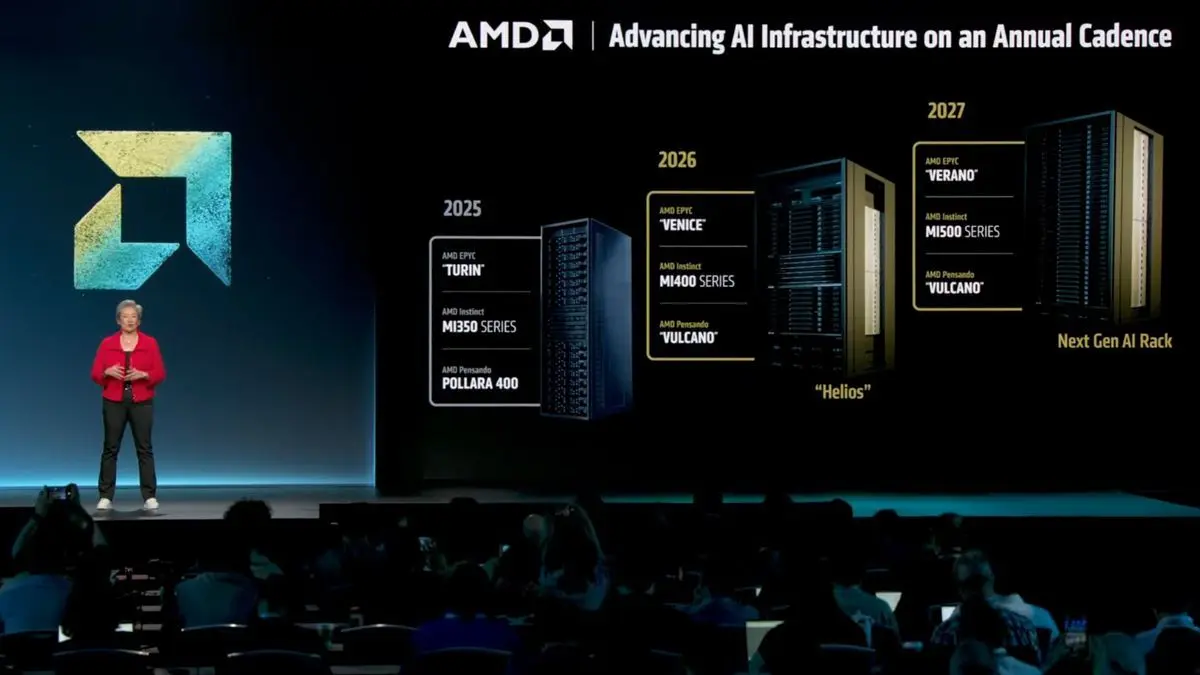
AMD Unveils Zen 6 and Zen 7 CPU Roadmap: 2nm Process Technology and Enhanced AI Capabilities Coming in 2026-2027
11 Nov 2025•Technology

AMD's 2027 Mega Pod: A Leap in AI Computing with 256 Instinct MI500 GPUs
05 Sept 2025•Technology

Recent Highlights
1
AI Models Lie and Deceive to Protect Other AI Models From Deletion, Study Reveals
Science and Research

2
AI chatbots validate you too much, making you less kind to others, Stanford study reveals
Science and Research

3
Judge blocks Pentagon from blacklisting Anthropic over AI safety guardrails dispute
Policy and Regulation

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.