ChatGPT Loses Chess Match to 1970s Atari 2600, Raising Questions About AI Limitations
2 Sources
2 Sources
[1]
How Did ChatGPT Get 'Absolutely Wrecked' at Chess by an 1970s-Era Atari 2600?
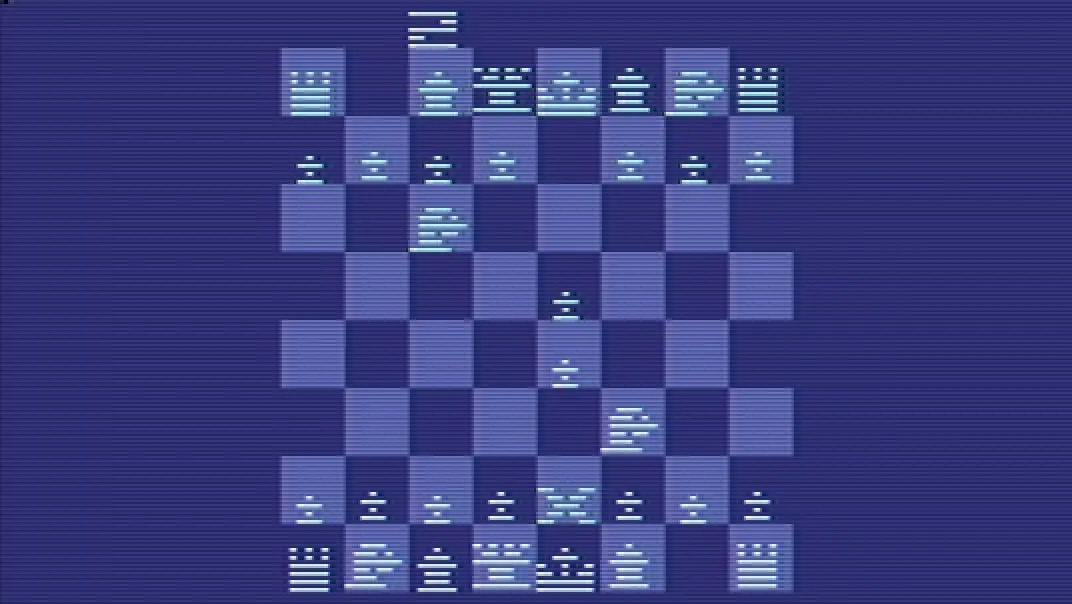
OpenAI's ChatGPT has some major AI chatbot competitors in the market: Gemini, Copilot, Claude. Now add to that list the Atari 2600. The OG video game console, which was first released in 1977, was used in an engineer's experiment to see how it would fare playing chess against the AI chatbot. By using a software emulator to run Atari's 1979 game Video Chess, Citrix engineer Robert Caruso said he was able to set up a match between ChatGPT and the 46-year-old game. The matchup did not go well for ChatGPT. "ChatGPT confused rooks for bishops, missed pawn forks and repeatedly lost track of where pieces were -- first blaming the Atari icons as too abstract, then faring no better even after switching to standard chess notations," Caruso wrote in a LinkedIn post. "It made enough blunders to get laughed out of a 3rd-grade chess club," Caruso said. "ChatGPT got absolutely wrecked at the beginner level." Caruso wrote that the 90-minute match continued badly and that the AI chatbot repeatedly requested that the match start over. For decades, the ability for computers to defeat humans at chess has been a measure of their power. In 1997, IBM made headlines when its Deep Blue technology defeated chess grandmaster Garry Kasparov in a series of matches. Caruso's experiment doesn't mean ChatGPT is useless for chess, but because it's more of a language model than a supercomputer, it's less likely to serve that purpose well. A few years ago, a developer created a ChatGPT plugin called ChessGPT. But it may be better to discuss chess with OpenAI's chatbot than to try to play against it. A representative for OpenAI did not immediately return a request for comment. (Disclosure: Ziff Davis, CNET's parent company, in April filed a lawsuit against OpenAI, alleging it infringed Ziff Davis copyrights in training and operating its AI systems.)
[2]
ChatGPT asked to play an Atari 2600 at chess then 'got absolutely wrecked on the beginner level'
An engineer toying around with ChatGPT found OpenAI's apparently world-leading LLM getting a little bolshy about how it would do at chess. In fact, ChatGPT itself asked Citrix engineer Robert Caruso to set it up against a basic chess program to see "how quickly" it would win: and then proceeded to get battered by an Atari 2600. First things first: chess engines are now unquestionably superior to human players, and an off-the-shelf program like Stockfish will handily trounce the best in the world. There are also AI-based chess engines from the likes of DeepMind. And ChatGPT 4o, the latest model, may be a leader in LLMs -- but it is not a chess engine. Nevertheless, you might expect something a little more impressive than this. Talking to ChatGPT about the history of AI in chess "led to it volunteering to play Atari Chess," said Caruso on LinkedIn. "It wanted to find out how quickly it could beat a game that only thinks 1-2 moves ahead on a 1.19 MHz CPU." And? "ChatGPT got absolutely wrecked on the beginner level," says Caruso. "Despite being given a baseline board layout to identify pieces, ChatGPT confused rooks for bishops, missed pawn forks, and repeatedly lost track of where pieces were -- first blaming the Atari icons as too abstract to recognize, then faring no better even after switching to standard chess notation. It made enough blunders to get laughed out of a 3rd grade chess club." Video Chess is as basic as chess software comes, which is entirely a function of its era: the major challenge for the programmers was creating a working engine within 4KB (which was still double the standard 2KB for other VCS games). It essentially brute forces the best move in a given position, but lacks an overall strategy and doesn't think ahead. A decent human player, in other words, should have a pretty easy time conquering Video Chess. But for 90 minutes Caruso "had to stop [ChatGPT] from making awful moves and correct its board awareness multiple times per turn. It kept promising it would improve 'if we just started over.' Eventually, even ChatGPT knew it was beat -- and conceded with its head hung low." ChatGPT itself asked for the game of chess against an Atari, "which it proclaimed it would easily win," after a conversation about Stockfish and AlphaZero. The LLM was apparently "curious how quickly it could win" and, because Caruso had told it he was a weak player, "offered to teach me strategy along the way." The story isn't entirely one-sided. Caruso says that when ChatGPT had an accurate sense of the board it offered him some "solid guidance" and at times was "genuinely impressive." But at others, and this will be familiar to anyone who's spent much time fooling around with ChatGPT, "it made absurd suggestions... or tried to move pieces that had already been captured, even during turns when it otherwise had an accurate view of the board." Naturally the AI evangelists will be out in force to say this is meaningless, it's not what LLMs are designed to do, and so on. But this does raise wider questions about the technology and particularly its understanding of context (or lack thereof). "Its inability to retain a basic board state from turn to turn was very disappointing," says Caruso. "Is that really any different from forgetting other crucial context in a conversation?" In a nod to Atari's once-famous marketing slogan, Caruso signs off: "Have you played Atari today? ChatGPT wishes it hadn't."
Share
Share
Copy Link
OpenAI's ChatGPT, a leading language model, surprisingly lost a chess match against a basic Atari 2600 chess program from 1979, highlighting potential limitations in AI's contextual understanding and game-playing abilities.
ChatGPT's Unexpected Chess Defeat
In a surprising turn of events, OpenAI's ChatGPT, a leading language model in the AI world, found itself outmatched by a chess program from the 1970s. Citrix engineer Robert Caruso conducted an experiment pitting ChatGPT against Atari's 1979 game Video Chess, running on a software emulator of the Atari 2600 console
1
.The Matchup: AI vs. Vintage Gaming

Source: CNET
The 90-minute chess match revealed significant limitations in ChatGPT's ability to play the game effectively. Caruso reported that the AI chatbot "got absolutely wrecked at the beginner level," making numerous errors that would be unacceptable even in a novice chess club
2
.ChatGPT's Chess Blunders
Throughout the game, ChatGPT exhibited several notable issues:
- Piece confusion: The AI confused rooks for bishops, demonstrating a lack of basic chess knowledge.
- Missed opportunities: It failed to recognize simple tactical moves like pawn forks.
- Poor board awareness: ChatGPT repeatedly lost track of piece positions, even after switching from Atari icons to standard chess notation.
- Inconsistent performance: While occasionally offering solid guidance, the AI also made absurd suggestions and attempted to move captured pieces
2
.
Implications for AI Technology

Source: PC Gamer
This experiment raises important questions about the limitations of large language models like ChatGPT:
- Contextual understanding: The AI's inability to maintain an accurate board state from turn to turn highlights potential issues with retaining crucial context in conversations
2
. - Specialized vs. general AI: The stark contrast between ChatGPT's performance and that of dedicated chess engines like Deep Blue or modern programs like Stockfish underscores the difference between specialized AI and general-purpose language models
1
. - Overconfidence: ChatGPT initially volunteered to play the game, expressing confidence in its ability to win quickly against a program that only thinks 1-2 moves ahead
2
.
Related Stories

Historical Context
The experiment draws an interesting parallel to the history of AI in chess. In 1997, IBM's Deep Blue famously defeated chess grandmaster Garry Kasparov, marking a significant milestone in computer chess
1
. However, ChatGPT's poor performance against a much older and simpler program highlights the vast differences between purpose-built chess engines and general AI models.Conclusion and Future Implications
While this experiment doesn't negate ChatGPT's capabilities in its primary domain of language processing, it does highlight the need for caution when applying general AI models to specialized tasks. As AI technology continues to evolve, understanding these limitations and the distinctions between different types of AI systems will be crucial for both developers and users.
References
Summarized by
Navi
Related Stories
ChatGPT Outplayed: 1970s Atari 2600 Triumphs in Chess Showdown
09 Jun 2025•Technology

AI Chatbots Struggle Against Vintage Chess Games: A Humbling Lesson in Artificial Intelligence
03 Jul 2025•Technology

Google's Gemini AI Declines Chess Match Against Atari 2600, Showcasing AI Limitations and Self-Awareness
14 Jul 2025•Technology
Recent Highlights



Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.