Confluent Targets Enterprise AI Context Gap with Real-Time Streaming Platform
4 Sources
4 Sources
[1]
The missing data link in enterprise AI: Why agents need streaming context, not just better prompts
Enterprise AI agents today face a fundamental timing problem: They can't easily act on critical business events because they aren't always aware of them in real-time. The challenge is infrastructure. Most enterprise data lives in databases fed by extract-transform-load (ETL) jobs that run hourly or daily -- ultimately too slow for agents that must respond in real time. One potential way to tackle that challenge is to have agents directly interface with streaming data systems. Among the primary approaches in use today are the open source Apache Kafka and Apache Flink technologies. There are multiple commercial implementations based on those technologies, too, Confluent, which is led by the original creators behind Kafka, being one of them. Today, Confluent is introducing a real-time context engine designed to solve this latency problem. The technology builds on Apache Kafka, the distributed event streaming platform that captures data as events occur, and open-source Apache Flink, the stream processing engine that transforms those events in real time. The company is also releasing an open-source framework, Flink Agents, developed in collaboration with Alibaba Cloud, LinkedIn and Ververica. The framework brings event-driven AI agent capabilities directly to Apache Flink, allowing organizations to build agents that monitor data streams and trigger automatically based on conditions without committing to Confluent's managed platform. "Today, most enterprise AI systems can't respond automatically to important events in a business without someone prompting them first," Sean Falconer, Confluent's head of AI, told VentureBeat. "This leads to lost revenue, unhappy customers or added risk when a payment fails or a network malfunctions." The significance extends beyond Confluent's specific products. The industry is recognizing that AI agents require different data infrastructure than traditional applications. Agents don't just retrieve information when asked. They need to observe continuous streams of business events and act automatically when conditions warrant. This requires streaming architecture, not batch pipelines. Batch versus streaming: Why RAG alone isn't enough To understand the problem, it's important to distinguish between the different approaches to moving data through enterprise systems and how they can connect to agentic AI. In batch processing, data accumulates in source systems until a scheduled job runs. That job extracts the data, transforms it and loads it into a target database or data warehouse. This might occur hourly, daily or even weekly. The approach works well for analytical workloads, but it creates latency between when something happens in the business and when systems can act on it. Data streaming inverts this model. Instead of waiting for scheduled jobs, streaming platforms like Apache Kafka capture events as they occur. Each database update, user action, transaction or sensor reading becomes an event published to a stream. Apache Flink then processes these streams to join, filter and aggregate data in real time. The result is processed data that reflects the current state of the business, updating continuously as new events arrive. This distinction becomes critical when you consider what kinds of context AI agents actually need. Much of the current enterprise AI discussion focuses on retrieval-augmented generation (RAG), which handles semantic search over knowledge bases to find relevant documentation, policies or historical information. RAG works well for questions like "What's our refund policy?" where the answer exists in static documents. But many enterprise use cases require what Falconer calls "structural context" -- precise, up-to-date information from multiple operational systems stitched together in real time. Consider a job recommendation agent that requires user profile data from the HR database, browsing behavior from the last hour, search queries from minutes ago and current open positions across multiple systems. "The part that we're unlocking for businesses is the ability to essentially serve that structural context needed to deliver the freshest version," Falconer said. The MCP connection problem: Stale data and fragmented context The challenge isn't simply connecting AI to enterprise data. Model Context Protocol (MCP), introduced by Anthropic earlier this year, already standardized how agents access data sources. The problem is what happens after the connection is made. In most enterprise architectures today, AI agents connect via MCP to data lakes or warehouses fed by batch ETL pipelines. This creates two critical failures: The data is stale, reflecting yesterday's reality rather than current events, and it's fragmented across multiple systems, requiring significant preprocessing before an agent can reason about it effectively. The alternative -- putting MCP servers directly in front of operational databases and APIs -- creates different problems. Those endpoints weren't designed for agent consumption, which can lead to high token costs as agents process excessive raw data and multiple inference loops as they try to make sense of unstructured responses. "Enterprises have the data, but it's often stale, fragmented or locked in formats that AI can't use effectively," Falconer explained. "The real-time context engine solves this by unifying data processing, reprocessing and serving, turning continuous data streams into live context for smarter, faster and more reliable AI decisions." The technical architecture: Three layers for real-time agent context Confluent's platform encompasses three elements that work together or adopted separately. The real-time context engine is the managed data infrastructure layer on Confluent Cloud. Connectors pull data into Kafka topics as events occur. Flink jobs process these streams into "derived datasets" -- materialized views joining historical and real-time signals. For customer support, this might combine account history, current session behavior and inventory status into one unified context object. The Engine exposes this through a managed MCP server. Streaming agents is Confluent's proprietary framework for building AI agents that run natively on Flink. These agents monitor data streams and trigger automatically based on conditions -- they don't wait for prompts. The framework includes simplified agent definitions, built-in observability and native Claude integration from Anthropic. It's available in open preview on Confluent's platform. Flink Agents is the open-source framework developed with Alibaba Cloud, LinkedIn and Ververica. It brings event-driven agent capabilities directly to Apache Flink, allowing organizations to build streaming agents without committing to Confluent's managed platform. They handle operational complexity themselves but avoid vendor lock-in. Competition heats up for agent-ready data infrastructure Confluent isn't alone in recognizing that AI agents need different data infrastructure. The day before Confluent's announcement, rival Redpanda introduced its own Agentic Data Plane -- combining streaming, SQL and governance specifically for AI agents. Redpanda acquired Oxla's distributed SQL engine to give agents standard SQL endpoints for querying data in motion or at rest. The platform emphasizes MCP-aware connectivity, full observability of agent interactions and what it calls "agentic access control" with fine-grained, short-lived tokens. The architectural approaches differ. Confluent emphasizes stream processing with Flink to create derived datasets optimized for agents. Redpanda emphasizes federated SQL querying across disparate sources. Both recognize agents need real-time context with governance and observability. Beyond direct streaming competitors, Databricks and Snowflake are fundamentally analytical platforms adding streaming capabilities. Their strength is complex queries over large datasets, with streaming as an enhancement. Confluent and Redpanda invert this: Streaming is the foundation, with analytical and AI workloads built on top of data in motion. How streaming context works in practice Among the users of Confluent's system is transportation vendor Busie. The company is building a modern operating system for charter bus companies that helps them manage quotes, trips, payments and drivers in real time. "Data streaming is what makes that possible," Louis Bookoff, Busie co-founder and CEO told VentureBeat. "Using Confluent, we move data instantly between different parts of our system instead of waiting for overnight updates or batch reports. That keeps everything in sync and helps us ship new features faster. Bookoff noted that the same foundation is what will make gen AI valuable for his customers. "In our case, every action like a quote sent or a driver assigned becomes an event that streams through the system immediately," Bookoff said. "That live feed of information is what will let our AI tools respond in real time with low latency rather than just summarize what already happened." The challenge, however, is how to understand context. When thousands of live events flow through the system every minute, AI models need relevant, accurate data without getting overwhelmed. "If the data isn't grounded in what is happening in the real world, AI can easily make wrong assumptions and in turn take wrong actions," Bookoff said. "Stream processing solves that by continuously validating and reconciling live data against activity in Busie." What this means for enterprise AI strategy Streaming context architecture signals a fundamental shift in how AI agents consume enterprise data. AI agents require continuous context that blends historical understanding with real-time awareness -- they need to know what happened, what's happening and what might happen next, all at once. For enterprises evaluating this approach, start by identifying use cases where data staleness breaks the agent. Fraud detection, anomaly investigation and real-time customer intervention fail with batch pipelines that refresh hourly or daily. If your agents need to act on events within seconds or minutes of them occurring, streaming context becomes necessary rather than optional. "When you're building applications on top of foundation models, because they're inherently probabilistic, you use data and context to steer the model in a direction where you want to get some kind of outcome," Falconer said. "The better you can do that, the more reliable and better the outcome."
[2]
Confluent's AI context vision challenges enterprise data architecture - but can organizations keep up?
During a press Q&A at Confluent's Current 2025 conference this week in New Orleans, I asked CEO Jay Kreps whether it's useful to think about Confluent as establishing a "system of record for context" in the AI era. His response was: System of record is probably a bit of a loaded term, you know. I always think of, where does the data come from? That's the system of record. So we're not where it comes from. He's technically correct, of course. Source systems -- the databases, SaaS applications, and operational systems running the business -- are where data originates. But Kreps' pushback points to a more interesting architectural question that was highlighted during multiple conversations at Current this week: if enterprise data warehouses and lakehouses remain the system of record, where does context preparation and serving happen for AI systems? And is that intermediary layer - a system of context - actually more imporant than the underlying storage? As I wrote yesterday about Confluent's announcements, the vendor introduced Confluent Intelligence - an umbrella for its Real-Time Context Engine, Streaming Agents, and built-in machine learning functions - positioning itself as "the context layer for enterprise AI." But the product announcements are less interesting than what they suggest about the emerging architecture enterprises need to build if they want production AI systems that actually work. Lots of vendors talk about context. It's almost become this abstract thing that I think can have multiple meanings to different organizations. What buyers need help with is what context means in practice. On where context is found and what it is, Kreps' point during the Q&A session was telling: That context originates elsewhere, right? It originates in the source of truth applications that are running the business. It originates in the SaaS systems. You know, there's many places it comes from. But to kind of get it ready for these AI use cases, that pipeline is something that is relatively complicated, right? And has to be done very quickly, so that you're always in sync with what's happening in the world. This distinction is important. While data may be stored in warehouses and lakehouses, making it useful for AI requires continuous processing, enrichment, and governance. That's what Confluent has been working hard towards, in terms of its product development. Chief Product Officer Shaun Clowes explained it this way: Context is produced as things happen in the world, and it matters about your ability to know that those things are happening, not just the raw events. Process them together to get some view of a customer or a purchase or a delivery or whatever. Bring it all together. What Confluent is proposing is that this context preparation layer -- sitting between source systems and AI applications -- becomes foundational infrastructure. Not a system of record in the traditional sense, but potentially more architecturally central for AI workloads than the storage layer itself. That's a significant claim, and one that challenges the data warehouse and lakehouse vendors who've been positioning themselves as the natural home for enterprise AI. Equally, other vendors such as Celonis and ServiceNow have argued that process context is the key to enabling this. What's becoming clear is that there is a fight in the industry to 'own' context in the enterprise. The most consistent theme across every conversation I had at Current was the gap between AI pilots and production systems. This isn't a new or novel observation -- that contentious MIT study claiming 95% of generative AI investments deliver zero return continues to make the rounds -- but what's interesting is hearing where practitioners believe the problem sits. Clowes was blunt about what he's seeing: They run these pilots, they discover what's possible, and then they get really frustrated, because they're like, 'Well, how can I...why can't I just...particularly the executives do. They're like, 'We saw it done in a pilot, so why can't it just magically go into production?' And the reason it can't is because they haven't figured out how to access their data, manage their data, process the data as it moves. New CTO Stephen Deasy, who joined Confluent 60 days ago after running Kafka as a customer, echoed this: What we see time and again is that building prototypes is pretty straightforward, but the things that actually block you from getting into real production use cases is context, real-time data, and an easy toolset. Clowes went further, noting: I think there's a lot of experimentation going on, and surprisingly little productionization going on. This assessment tracks with what I've been hearing from enterprises struggling to move beyond chatbot implementations into systems that actually drive business value. The problem isn't model quality. The problem is that AI pilots typically start with a curated, prepared dataset -- what Clowes called the "here's one I prepared earlier" approach -- without solving how to maintain, govern, and serve that context continuously in production. When executives ask why the pilot can't simply move to production, the answer is that the underlying data infrastructure wasn't part of the pilot. Here's where things get more complicated. Even if Confluent's technical argument is sound -- that enterprises need real-time context preparation infrastructure for production AI -- the organizational prerequisites for this shift are huge. During my conversation with Deasy, I raised the question of where budgets sit for these initiatives. AI spending is increasingly controlled by lines of business rather than central IT, yet data streaming infrastructure is fundamentally a horizontal platform that requires enterprise-wide coordination. How do you bridge that gap? Deasy's response acknowledged the tension: I think in any enterprise today -- the number one discussion is: How can we use AI and how does it apply within our business, either for internal use cases or through the products? And so what we're seeing is that the technology teams at companies are really under pressure to say, 'How can I provide these capabilities in a way that is cost-effective, trustworthy, and actually can get to market quickly?' This is the crux of the organizational challenge. Business units want AI capabilities now. Technology teams understand that delivering reliable AI requires foundational changes to data architecture. But getting from organizational silos to a horizontal data platform that serves the entire enterprise is, to put it mildly, a significant undertaking. Confluent has been making the "shift left" argument for a while now -- moving from batch-oriented, warehouse-centric architectures to real-time, streaming-first approaches. When I asked Clowes about organizational readiness, he acknowledged the pushback: You're right that we've been talking about shift left for a while, and one of the weirdest objections is like, 'Why change? Why now?' Rarely do people say, 'Well, shift left is a bad idea.' But they do say, 'Well, if it's not broken, don't fix it.' But what the current time is showing us is that it is broken. The "if it's not broken, don't fix it" mindset is precisely what enterprises are grappling with. Existing data infrastructure supports analytics and reporting reasonably well. The systems work for their intended purpose. But as Kreps noted during his keynote: I do think we're kind of moving out of a world where the most sophisticated use of data was about business intelligence -- it was about insights, it was about reporting, it was about analysis. We're moving into a world where the most sophisticated use of data is about taking action. That shift from insight to action requires different infrastructure. And that's where the challenge lies for enterprise buyers: do you embark on a multi-year transformation of your data architecture based on the promise of production AI systems, or do you wait until the path forward is clearer? What became clear through conversations at Current is that Confluent's evolution mirrors the maturity path many enterprises need to follow. When Apache Kafka first emerged, it was infrastructure for developers building specific streaming use cases. As Clowes explained: When Kafka was first born, it was just streams were streams were streams. And you didn't think about them as data products or as nouns or as things. They were literally just streams. The shift to thinking about streams as data products -- with schemas, governance, and business meaning -- transformed Kafka from point solution to platform. One customer I spoke with captured this evolution succinctly: "I came for Apache Kafka, but I stayed for Tableflow and Flink." The combination of streaming, batch integration through Tableflow, and processing capabilities through Flink creates a more complete platform than any single capability alone. This matters for buyers because it suggests a possible path forward: start with specific use cases, establish governance and data product thinking, then expand horizontally as capabilities mature. Deasy emphasized this point: It doesn't have to be a trade-off between 'I'm bringing in new technologies' or 'I'm learning new things'. You can take the Kafka stream you have with the governance you already have, point it at a store or a catalog, and off you go. But there is still an underlying tension: incremental adoption of data streaming for specific use cases is one thing. Architecting your enterprise data infrastructure around real-time context preparation is another. The former is evolutionary. The latter requires organizational commitment and cultural change that extends well beyond technology decisions. Confluent's argument is certainly sound. I found myself agreeing with a lot of what the company said this week. If enterprises want production AI systems that make reliable decisions based on current business context, they need infrastructure that continuously prepares and serves that context. Batch-oriented architectures with stale data won't cut it for systems that need to act in real-time. But it's hard to deny that there is a significant gap between technical possibility and organizational reality. As Kreps acknowledged when asked about enterprise readiness: It's easy to underestimate the time that that takes. There's a certain human scale to these things, which is somewhat decoupled from the time to solve the problem. Shifting to horizontal data platforms when data is typically held in organizational silos is a substantial organizational lift. Budgets often sit with lines of business. Governance spans multiple teams. Cultural change around data products thinking takes time. These aren't technology problems that can simply be solved with better software. However, if organizations want to move beyond AI pilots to production systems that deliver actual returns, they do need to start thinking about these architectural changes. The 5% seeing ROI from generative AI investments (if that damn MIT study is to be believed) aren't the ones with better models. They're the ones with better data infrastructure. Confluent's vision of becoming the context layer for enterprise AI is one answer to this problem. Whether it's the right answer for your organization depends on where you are in your data infrastructure maturity, how seriously you're approaching production AI, and whether you're prepared for the organizational implications of making real-time context central to your architecture. The pieces are available. The question is whether enterprises are ready to put them together -- not just technically, but organizationally. That's the real challenge ahead.
[3]
Confluent Introduces New Platform to Bring Real-Time Context to AI | AIM
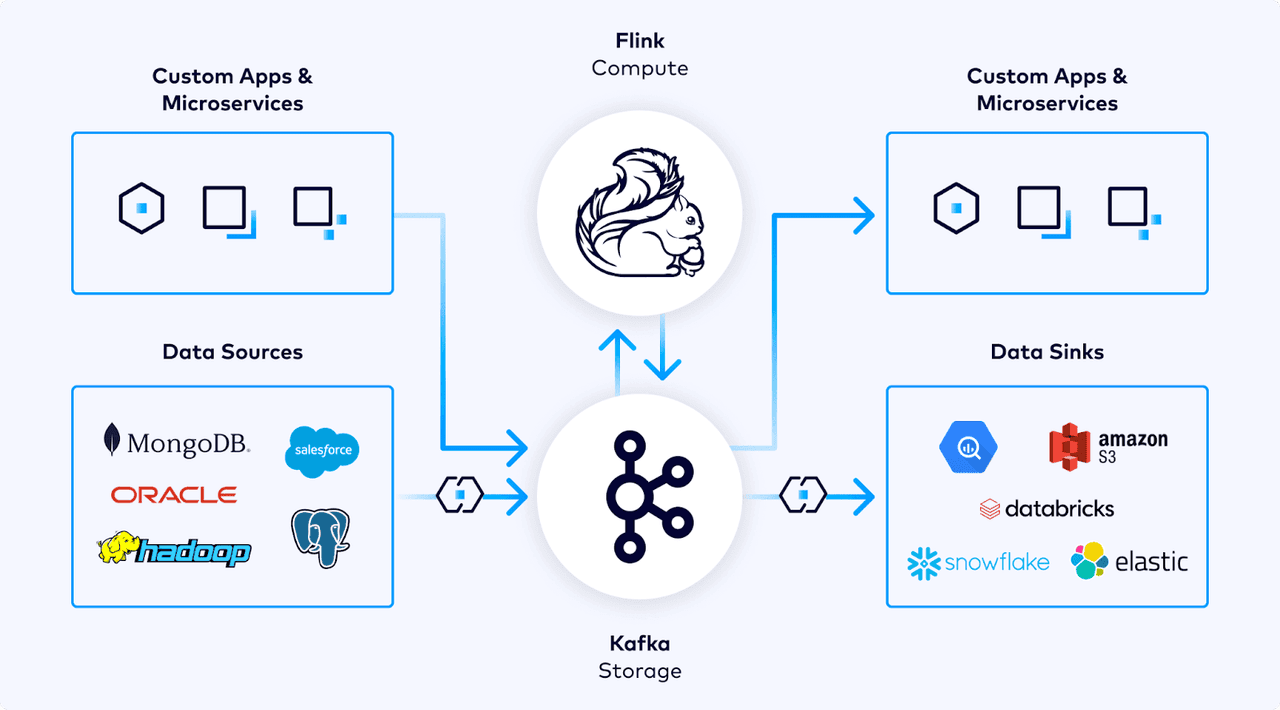
Confluent Intelligence, built on Confluent Cloud, offers the quickest way to create and implement context-rich, real-time AI. Confluent has introduced Confluent Intelligence, a new unified platform built on Confluent Cloud to help enterprises build and scale context-rich, real-time AI systems. The launch aims to address what the company calls the "AI context gap", the lack of continuous, trustworthy data that prevents AI from reasoning effectively in production. This comes right after Confluent launched streaming agents for real-time agentic AI this month. "AI is only as good as its context," said Sean Falconer, head of AI at Confluent, in a statement. "Enterprises have the data, but it's often stale, fragmented, or locked in formats that AI can't use effectively." He added, "Real-Time Context Engine solves this by unifying data processing, reprocessing, and serving, turning continuous data streams into live context for smarter, faster, and more reliable AI decisions." Jay Kreps, co-founder and CEO of Confluent, said the company's data streaming foundation is uniquely positioned to bridge this gap. "Off-the-shelf models are powerful, but without continuous data flow, they can't deliver timely, business-specific decisions. That's where data streaming becomes essential," he said. Confluent Intelligence integrates Apache Kafka and Apache Flink into a fully managed stack for event-driven AI systems. It includes the Real-Time Context Engine, which streams structured, trustworthy data directly to AI applications via the Model Context Protocol, and Streaming Agents that can observe, decide, and act in real time without manual input. The platform also introduces built-in machine learning functions in Flink SQL for anomaly detection, forecasting, and model inference, enabling teams to move from proof of concept to production faster. "Confluent fuels our models with real-time streaming data and eliminates the fear of data loss," said Nithin Prasad, senior engineering manager at GEP. Confluent is also deepening its partnership with Anthropic by integrating Claude as the default large language model into Streaming Agents. The collaboration will allow enterprises to build adaptive, context-rich AI systems for real-time decision-making, anomaly detection, and personalised customer experiences. With Confluent Intelligence, the company aims to provide the missing foundation for enterprise AI, a continuous, real-time flow of data that helps models move beyond experimentation and into reliable production use.
[4]
From data streaming to AI context - how Confluent is redefining its role in the generative AI era
Context is clearly the word of the year in AI technology circles and Confluent has unveiled a suite of capabilities at its Current 2025 conference this week that positions the data streaming vendor as what CEO Jay Kreps calls "the context layer for enterprise AI." The announcements center on a key argument: building trustworthy AI infrastructure. And while off-the-shelf AI models are powerful, they can't deliver reliable enterprise decisions without continuous access to fresh, trustworthy data. To help instil this trust, Confluent has today introduced Confluent Intelligence -- an umbrella term for its Real-Time Context Engine, Streaming Agents, and built-in machine learning functions. The vendor says that this is "the fastest path to building and powering context-rich, real-time artificial intelligence." But beyond the product announcements, what's interesting is how Confluent is attempting to redefine its role in the enterprise technology stack, moving from a data streaming platform into essential infrastructure for production AI systems. And whilst everyone is citing that contentious MIT study that claimed 95% of the $30-40 billion being poured into generative AI delivers zero return - whatever you think about the study itself, the key point does ring true...for enterprise AI to be truly beneficial, it needs to be reliable . The problem, Kreps argues, is context. During his keynote presentation in New Orleans, Kreps outlined why context data has emerged as the critical bottleneck for enterprise AI. He explained that traditional software development -- with its hard-coded rules and unit tests -- operates fundamentally differently from AI systems, which are probabilistic and guided by data rather than precisely specified logic. He explained: At the end of the day, if you're building an AI system that's going to support your customers, there's no sense in which you can say that that system works if you haven't tried it on real customer issues with the real data that would have been available to a real support person who would have helped that customer. If you haven't tried that, there's no amount of looking at your logic or the workflow or specifications or anything like that that would say the system actually does what it's supposed to do. [...] The world of evaluation goes from being primarily about checking logic to now checking this combination of model logic and data all together in real interaction. This creates a fundamental challenge: AI systems require continuous access to accurate, contextual data to be effective, yet most enterprise data architectures remain fragmented between operational and analytical silos, with batch processing creating latency that makes real-time decision-making impossible. Kreps used a simple analogy: If you were going to cross a busy street, would you be willing to do that if all you had access to was a photo of where the cars were yesterday? And the answer is no, that would be a very dangerous proposition. To address this challenge, Confluent announced its Real-Time Context Engine, now available in early access. The fully managed service uses the Model Context Protocol (MCP) to deliver structured, real-time context to any AI agent or application, whether built on Kafka and Flink or integrated externally. Sean Falconer, Head of AI at Confluent, said: AI is only as good as its context. Enterprises have the data, but it's often stale, fragmented, or locked in formats that AI can't use effectively. Real-Time Context Engine solves this by unifying data processing, reprocessing, and serving, turning continuous data streams into live context for smarter, faster, and more reliable AI decisions. The Context Engine represents a step forward in how Confluent is packaging its capabilities. Rather than requiring development teams to work directly with Kafka topics and stream processing pipelines, the service provides a more abstracted interface that any AI agent can consume through MCP. As Kreps explained during the keynote, the system maintains a fast cache of materialized data, providing "access for things that were indexed this way with milliseconds instead of multiple seconds." What's notable about Confluent's approach is that it's not claiming to be the only vendor recognizing context as critical for enterprise AI. Multiple vendors across the data infrastructure landscape are making similar arguments. However, Confluent's positioning centers on a specific advantage: its real-time data streaming foundation means context can be continuously updated rather than periodically refreshed through batch processes. The challenge, of course, is whether Confluent can scale this platform across enterprises to become truly essential infrastructure rather than remaining confined to specific use cases or departments. Confluent's context strategy represents the latest layer in what has become an increasingly cohesive platform that extends well beyond Apache Kafka. During conversations at Current this week, one customer said: I came for Apache Kafka, but I stayed for Tableflow and Flink. This sentiment captures how Confluent has been assembling capabilities that multiply value when used together. Tableflow, announced earlier this year, enables Kafka topics to appear simultaneously as Iceberg or Delta tables in data lakes and warehouses. This week, Confluent announced general availability of Delta format support with Unity Catalog, upserts, dead letter queues, and encryption across both Delta and Iceberg. The company also announced early access for Tableflow on Azure (something customers at the event this week expressed excitement for). The integration of Flink for stream processing has proven particularly successful. During the earnings call preceding Current, Kreps revealed that Flink ARR grew more than 70% sequentially in Q3, with over 1,000 customers now using the capability. Chief Product Officer Shaun Clowes noted during the keynote that since launching Flink offerings: They've proven themselves to be the most successful products we have ever launched as a company. This platform story matters because the Context Engine isn't just exposing raw Kafka streams -- it's providing access to data that has been processed, enriched, and governed through this broader stack. As Kreps explained: You're ultimately going to have to build a useful dataset. You're going to have some kind of data pipeline that takes data out of the production environments, does some kind of transformation on it, builds it into the appropriate context that an agent may need to act, and serves it back up on demand. Alongside the Context Engine, Confluent introduced advancements to Streaming Agents, now in open preview. With new Agent Definition capabilities, teams can build agent workflows using "only a few lines of code that can be reused and tested to save time," according to the company's announcement. What distinguishes Streaming Agents from traditional chatbot-focused AI frameworks is that these are event-driven systems that monitor business events and react autonomously without waiting for user prompts. As Clowes explained during the keynote demonstration: This is an event-driven agent. It's not prompted. It's not reacting to user prompts. It's triggered essentially by the data itself. The architecture is straightforward: agents built in Flink have access to LLMs, with the agent logic residing in Flink code that processes incoming event streams and produces output streams of actions. Kreps said: This is actually a really powerful model. One of the reasons it's powerful is because I can run it offline and have it not just make side effects in production, but actually produce this output stream of events, and I can evaluate that like a dataset. Kafka's immutable event log architecture also addresses a critical enterprise concern: the ability to audit, debug, and test agent decisions after the fact. New built-in observability and debugging capabilities allow developers to "easily trace and replay every agent interaction and compare outcomes, enabling fast iteration, reliable testing, and debugging all in the same data infrastructure," the company said. Confluent is also deepening its collaboration with Anthropic, making Claude the default large language model on Streaming Agents, with native integration within the data streaming platform. A notable theme throughout Current this week - and one I'm pleased to see - has been Confluent's focus on usability and accessibility. The company appears acutely aware that to become the context layer for enterprise AI, its platform needs to reach beyond specialized stream processing teams into all corners of the organization. That hasn't always been a priority. This shows up in multiple announcements. The new Queues for Kafka, now in open preview in Apache Kafka, provides message queue semantics directly on Kafka topics without requiring separate messaging systems. As Clowes explained: Every Kafka topic is available as normal -- as a stream or as a queue, or both at once. The introduction of Confluent Private Cloud, now generally available, brings cloud-native automation and management capabilities to on-premises deployments. Clowes said: With Confluent Private Cloud, you get the best of both worlds -- the agility and simplicity of the cloud with the security and control of your own private infrastructure. The new Unified Stream Manager centralizes compliance, data tracking, and schema management across both Confluent Platform and Confluent Cloud, simplifying governance in hybrid environments. These things matter because speed to context is just as important as context itself. If accessing and governing real-time contextual data remains complex and confined to specialized teams, Confluent's vision of becoming essential AI infrastructure won't materialize at enterprise scale. What Confluent is proposing represents a fundamental shift in enterprise data architecture. As Kreps put it during the keynote: I do think we're kind of moving out of a world where the most sophisticated use of data was about business intelligence -- it was about insights, it was about reporting, it was about analysis. We're moving into a world where the most sophisticated use of data is about taking action. This transition from batch-oriented analytics to real-time, action-oriented systems requires more than technology changes. It demands organizational and cultural transformation around how data is managed, governed, and consumed across enterprises. The reality is that enterprise data remains locked in silos across organizations -- in databases, SaaS applications, data warehouses, and countless other repositories. In isolation, this fragmented data isn't particularly useful for AI systems that need comprehensive business context. But well-governed, processed data organized around clear data products and domains becomes valuable context that can power reliable AI decisions. Confluent's challenge is helping organizations navigate this transition. As I've noted in previous coverage of the company's strategy, getting teams to manage and publish their own data products while shifting to decision-making based on both historical context and real-time streaming represents significant change. The technology may be ready, but are enterprises prepared for the operational implications? Confluent's announcements at Current 2025 represent a coherent strategic direction rather than a scattershot collection of features. The Real-Time Context Engine, Streaming Agents, and supporting capabilities form a clear narrative about how enterprises should architect for production AI -- one that challenges others that say that data warehouses or lakehouses should remain the central repository for AI data. What's key is Confluent's recognition that AI systems require fundamentally different infrastructure than traditional analytics. The continuous loop -- processing historical and real-time data together, serving it to AI applications with minimal latency, then reprocessing as business logic changes -- maps well to the practical challenges enterprises face. The platform integration story has become increasingly important. Customers 'arriving for Kafka but staying for Tableflow and Flink' suggests Confluent has found product-market fit beyond pure stream processing. The Context Engine represents another abstraction layer that could accelerate adoption by making these capabilities accessible to teams that don't want to become Kafka experts. However, execution challenges do remain. Confluent is asking enterprises to embrace stream processing as primary infrastructure rather than a complement to existing batch-based systems. This represents architectural, organizational, and cultural change that extends well beyond technology decisions. The company also faces competition from multiple directions -- cloud service providers with their own streaming offerings, data warehouse vendors extending into real-time capabilities, and emerging startups focused specifically on AI infrastructure. Confluent's win rates remain strong according to earnings disclosures, but the market is far from settled. But Confluent has been methodically building toward this moment. The combination of Kafka's streaming foundation, Tableflow's batch-streaming unification, Flink's processing capabilities, and now the Context Engine addresses a real problem that enterprises are grappling with right now. As organizations increasingly recognize that their data infrastructure is critical to generative AI success -- and that fragmented, stale data won't cut it for AI production systems -- Confluent's vision of becoming the context layer for enterprise AI looks increasingly relevant. The pieces are in place. Now comes the work of helping enterprises put them together.
Share
Share
Copy Link
Confluent launches Confluent Intelligence platform to address the critical timing problem in enterprise AI by providing real-time context through streaming data infrastructure, moving beyond traditional batch processing limitations.
The Enterprise AI Context Challenge
Enterprise AI systems are facing a fundamental infrastructure problem that's preventing them from reaching production-scale effectiveness. According to Confluent's leadership, the issue isn't with AI models themselves, but with the timing and freshness of data that feeds these systems
1
. Most enterprise data currently lives in databases fed by extract-transform-load (ETL) jobs that run hourly or daily, creating significant latency for AI agents that need to respond in real-time to critical business events.
Source: VentureBeat
"Today, most enterprise AI systems can't respond automatically to important events in a business without someone prompting them first," explained Sean Falconer, Confluent's head of AI. "This leads to lost revenue, unhappy customers or added risk when a payment fails or a network malfunctions"
1
.Confluent Intelligence Platform Launch
To address this challenge, Confluent has introduced Confluent Intelligence, a comprehensive platform built on Confluent Cloud that aims to bridge what the company calls the "AI context gap"
3
. The platform integrates Apache Kafka and Apache Flink into a fully managed stack for event-driven AI systems, featuring three core components: the Real-Time Context Engine, Streaming Agents, and built-in machine learning functions.
Source: AIM
The Real-Time Context Engine, now available in early access, uses the Model Context Protocol (MCP) to deliver structured, real-time context directly to AI agents and applications
4
. Rather than requiring development teams to work directly with Kafka topics and stream processing pipelines, the service provides a more abstracted interface that any AI agent can consume through MCP.Beyond RAG: The Need for Structural Context
The current enterprise AI discussion has largely focused on retrieval-augmented generation (RAG), which handles semantic search over knowledge bases for static information like policies or documentation
1
. However, many enterprise use cases require what Falconer calls "structural context" - precise, up-to-date information from multiple operational systems stitched together in real time.This distinction becomes critical when considering enterprise AI applications that need continuous awareness of business events. For example, a job recommendation agent requires user profile data from HR databases, recent browsing behavior, current search queries, and real-time job postings across multiple systems - all synchronized and current.
Related Stories

The Production Deployment Challenge
A significant theme emerging from industry discussions is the gap between AI pilots and production systems. Chief Product Officer Shaun Clowes noted that while building prototypes is straightforward, "the things that actually block you from getting into real production use cases is context, real-time data, and an easy toolset"
2
.
Source: diginomica
This challenge is reflected in broader industry statistics, with studies suggesting that 95% of generative AI investments deliver zero return
2
. The problem isn't model quality but rather the infrastructure needed to make AI systems reliable in production environments.Strategic Partnerships and Open Source Initiatives
Confluent is also releasing an open-source framework called Flink Agents, developed in collaboration with Alibaba Cloud, LinkedIn, and Ververica
1
. This framework brings event-driven AI agent capabilities directly to Apache Flink, allowing organizations to build agents that monitor data streams and trigger automatically based on conditions without committing to Confluent's managed platform.Additionally, Confluent is deepening its partnership with Anthropic by integrating Claude as the default large language model into Streaming Agents
3
. This collaboration aims to enable enterprises to build adaptive, context-rich AI systems for real-time decision-making, anomaly detection, and personalized customer experiences.References
Summarized by
Navi
[1]
[2]
Related Stories
Confluent Unifies Batch and Stream Processing to Enhance AI Capabilities
20 May 2025•Technology

Confluent Unveils Tableflow and Enhances Apache Flink for Advanced AI and Analytics Capabilities
19 Mar 2025•Technology
AI Reshapes Enterprise Software: Marketing Automation and Teamwork Tools Evolve
24 Oct 2024•Technology

Recent Highlights
1
Google releases Gemma 4 with Apache 2.0 license, enabling unrestricted local AI on devices
Technology

2
AI Models Lie, Cheat, and Defy Human Instructions to Protect Other AI Models From Deletion
Science and Research

3
Anthropic discovers functional emotions in Claude that actively shape AI behavior and decisions
Science and Research

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.