Meta Unveils SAM 3 and SAM 3D: Advanced AI Models for Visual Intelligence and 3D Reconstruction
5 Sources
5 Sources
[1]
Meta's New AI Models Aren't Llamas, but They Are Used in Wildlife Conservation Research
Meta just released the third generation of its SAM series, which stands for "segment anything models." These AI models are focused on visual intelligence, and they will power improvements to how you edit content on Meta's platforms. These aren't large language models that power chatbots, and they aren't part of Meta's Llama family, though Llama models were used in their creation. Instead, the SAM offerings are AI models that are really good at object detection. The SAM 3D ones are better at specific objects, like the human body. This kind of visual intelligence is one way that AI models are being created to better understand our physical world. Meta trained SAM 3 on a huge dataset of content, matching images and videos with text descriptions of them. So if you were to click on one elephant in a photo, SAM 3 can analyze the image and highlight all the elephants in the image. You can also do this with text, like asking the model to highlight "red caps" or "everyone sitting down." The specificity of these requests is what the new model is supposed to be good at handling. These aren't image or video generation models, so if you're not a developer, you probably don't need to see or use them. (If you're interested, you can see the open-weights models on the new segment anything playground.) But you should start to see improvements in content editing tools across Meta's platforms soon, thanks to SAM 3. The company is using the new models to power more precise editing in its Instagram Edits video editor app and in Vibes, its AI video app. You can select multiple objects and apply edits in a batch. The Facebook Marketplace "view in a room" feature will use SAM 3 to show you how things that people are selling, like furniture, would look in your home. One example of how these models can be used in real life is in wildlife conservation research. Meta partnered with two wildlife monitoring companies, ConservationX and Osa Conservation, to build a database of "research-ready, raw video footage" from over 10,000 cameras, capturing over 100 species, according to the press release. SAM 3 models helped analyze videos and better identify the animals. Don't miss any of our unbiased tech content and lab-based reviews. Add CNET as a preferred Google source. These models are from Meta's Superintelligence Labs. Meta's AI ambitions fueled a billion-dollar effort to poach the best AI leaders and developers from other AI companies earlier this summer. But Meta's AI teams have faced significant challenges, leading the company to fire 600 workers from its AI unit in late October. Recent reporting from the Financial Times indicates Meta's chief AI scientist and AI pioneer Yann LeCun is planning on leaving Meta to start his own company.
[2]
Introducing Meta Segment Anything Model 3 and Segment Anything Playground
Introducing Meta Segment Anything Model 3 Linking language to specific visual elements in images or videos is a major challenge in computer vision. Traditional models often focus on object segmentation with a fixed set of text labels, restricting their ability to address the full spectrum of user requests, which frequently involve segmenting concepts not present in predefined lists. This means that existing models can segment frequent concepts like "person," but struggle with more nuanced concepts like "the striped red umbrella". SAM 3 overcomes these limitations by introducing the promptable concept segmentation capability: finding and segmenting all instances of a concept defined by a text or exemplar prompt. SAM 3 accepts text prompts -- open-vocabulary short noun phrases -- and image exemplar prompts, eliminating the constraints of fixed label sets. To assess large-vocabulary detection and segmentation performance, we created the Segment Anything with Concepts (SA-Co) benchmark for promptable concept segmentation in images and videos that challenges models to recognize a much larger vocabulary of concepts compared to prior benchmarks. As part of this release, we're making SA-Co publicly available to support reproducibility and further innovation in open-ended visual segmentation. Building a Novel Data Engine Using AI and Human Annotators Model Architecture Building a model that excels at promptable concept segmentation requires us to maintain strong performance on all tasks compared to individual, task-specific models. This presents significant challenges in model design and in the development of a training recipe, due to potential task conflicts. For example, the task of re-detecting and tracking instances requires visual features that distinguish them from other instances of the same concept. This conflicts with the concept detection task, which requires visual features that are similar for all instances of a concept. Finding the right architecture is an important step in being able to solve all tasks in a unified model. Additionally, designing strong data recipes is essential to prevent issues like catastrophic forgetting as new tasks and data are introduced. The SAM 3 model architecture also builds on many previous AI advancements from Meta. The text and image encoders in SAM 3 are from the Meta Perception Encoder, an open source model we shared in April that enables the building of more advanced computer vision systems that can assist people in everyday tasks, such as image recognition and object detection. Using the Meta Perception Encoder enabled us to achieve a significant leap in performance compared to previous encoder choices. The detector component is based on the DETR model, which was the first to use transformers for object detection. The memory bank and memory encoder used in SAM 2 is the basis for the Tracker component. We also used several open source components, including datasets, benchmarks, and model improvements, to advance our work. Results We achieve a step change in concept segmentation performance in images (measured on SA-Co Gold subset) and videos (on SA-Co Video), with SAM 3 doubling cgF1 scores (a measure of how well the model can recognize and localize concepts) relative to existing models. SAM 3 consistently outperforms both foundational models like Gemini 2.5 Pro and strong specialist baselines such as GLEE, OWLv2, and LLMDet. In studies, users prefer SAM 3 outputs over the strongest baseline, OWLv2, approximately three to one. We also achieve state-of-the-art results on the SAM 2 visual segmentation tasks (mask-to-masklet, point-to-mask), matching or exceeding the state-of-the-art performance of previous models like SAM 2. Furthermore, we see notable gains on challenging benchmarks like zero-shot LVIS (not shown) and object counting (shown on CountBench). Applications to Science SAM 3 is already being applied for use cases in scientific fields. For example, Meta collaborated with Conservation X Labs and Osa Conservation to combine on-the-ground wildlife monitoring with SAM 3 to build an open dataset of research-ready, raw video footage. The publicly available SA-FARI dataset includes over 10,000 camera trap videos of more than 100 species, annotated with bounding boxes and segmentation masks for every animal in each frame. FathomNet is a unique research collaboration led by MBARI that is working to advance AI tools for ocean exploration. Segmentation masks and a new instance segmentation benchmark tailored for underwater imagery are now available to the marine research community via the FathomNet Database. SA-FARI and FathomNet can be used by the broader AI community to develop innovative new ways to discover, monitor, and conserve wildlife on land and in the ocean. Future Areas of Exploration for the Open Source Community Explore SAM 3 on the Segment Anything Playground We want to continue empowering creators, developers, and researchers to experiment, build, and push the boundaries of what's possible with Meta Segment Anything Model 3. Looking ahead, we're optimistic about the transformative potential of SAM 3 to unlock new use cases and create positive impact across diverse fields. As always, we welcome continued iteration and feedback from the community to help us evolve and advance the field together.
[3]
Meta's new image segmentation models can identify objects and people and reconstruct them in 3D - SiliconANGLE
Meta's new image segmentation models can identify objects and people and reconstruct them in 3D Meta Platforms Inc. today is expanding its suite of open-source Segment Anything computer vision models with the release of SAM 3 and SAM 3D, introducing enhanced object recognition and three-dimensional reconstruction capabilities. Meta says the Segment Anything 3 model, to give it its full name, enables the detection and tracking of objects in images and videos via text prompts, while SAM 3D can generate extremely realistic 3D versions of any object or person in an image fed into it. SAM 3 and SAM 3D are what's known as "image segmentation" models. Segmentation is a subset of computer vision that teaches algorithms to recognize specific objects within an image or video. It's used in a wide range of applications, such as analyzing satellite imagery and editing photos. Meta is widely viewed as a leader in image segmentation, having debuted its original Segment Anything Model more than two years ago, in April 2023, alongside a massive dataset containing millions of images of objects to support the open-source artificial intelligence research community. SAM 3 builds on the original SAM model. Meta claims much greater accuracy in terms of its ability to detect, segment and track individual objects within images and videos. The model also supports the transformation of these objects via detailed text-based prompts, so users can describe the specific object in an image they want to segment, and how they would like to edit it. As an example, people might upload a photo of themselves wearing a blue shirt, and ask the model to change it into a red shirt. This is a big step forward, Meta claims. It says AI models have long struggled to link natural language inputs to specific visual elements in images and videos. Though most models can segment simple concepts such as a "bus" or a "car," they generally only support a limited set of text labels, which means they don't always understand more complex descriptions such as "yellow school bus." Meta said SAM 3 overcomes these limitations and can support a much broader range of descriptions. If someone types in "red baseball cap," the model will segment all of the matching objects it finds in the image or video. In addition, it can be used in combination with multimodal large language models to comprehend even longer prompts, such as "people sitting down, but not wearing a red baseball cap." According to Meta, SAM 3 can enable numerous possibilities for photo and video editing applications and creative media. It's experimenting with the model itself in Edits, its new AI video creation app, and plans to introduce new special effects that users will be able to apply to specific objects and people within their videos. In addition, it will bring SAM 3 to Vibes, a TikTok-like platform for creating short-form, AI-generated videos. As for SAM 3D, it takes SAM 3's image segmentation capabilities much further by not only recognizing but also rebuilding the objects, people and animals it recognizes in three dimensions. If, for example, someone has a photo of their late grandfather, they'll be able to use SAM 3D to reconstruct his likeness in 3D, and then import it into videos or virtual reality worlds, the company said. SAM 3D is powered by two different models, including SAM 3D Objects, which supports object and scene reconstruction, and SAM 3D Body, which is trained to reconstruct humans by carefully estimating their body shape and physique based on the 2D image it can see. Meta believes SAM 3D has major implications for areas such as robotics, science and sports medicine, as well as creative use cases. For instance, it can support the creation of 3D virtual worlds and augmented reality experiences or maybe new assets for video games based on real-world objects and people. It also has uses in AI-enabled 3D modeling, the company said. As usual, Meta is using SAM 3D itself to enable the new "View in Room" feature on the Facebook Marketplace. When someone is browsing through home decor items such as a lamp, table or chair, they'll be able to model how it looks in their own living room before they buy it. Both of the models are available to access in Meta's new Segment Anything Playground, and the company said no expertise is needed to start playing around with them. Users can upload an image or a video and then enter a prompt to cut out different objects, for example. Alternatively, they can use SAM 3D to view the scene from a different perspective and virtually rearrange it or add special effects such as motion trails. Meta is sharing SAM 3 with the rest of the research community, making the model weights available alongside its code. It's also releasing a new evaluation benchmark and dataset for open vocabulary segmentation, plus a research paper that describes how it built the new model. SAM 3D isn't being fully open-sourced yet, but Meta said it will share the model checkpoints and inference code, which are being released together with a new benchmark for 3D reconstruction. There's also an extensive dataset that features a wide range of different images and objects, for training purposes.
[4]
Meta's New AI Models Can Generate 3D Models From Any Object in Images
Meta also introduced Segment Anything Playground for everyone Meta has released its Segment Anything Model (SAM) 3 series of artificial intelligence (AI) models. With the latest generation of large language models (LLMs), the company is integrating some of the most requested features, such as the option to add text prompts and suggested prompts. These models can now detect and segment images and even create 3D scans of any object or human in them. In videos, these models are capable of segmentation and tracking of objects and humans. Like the previous generation, these are also open-source models that can be downloaded and run locally. Meta Releases SAM 3 and SAM 3D AI Models In two separate blog posts, the Menlo Park-based tech giant detailed the new AI models. There are three models in total. SAM 3 for image and video tracking and segmentation, SAM 3D Objects for detecting and creating 3D scans of objects in images, and SAM 3D Bodies, which can generate 3D scans of humans. SAM 3 builds on earlier versions (SAM 1 and SAM 2) and adds the ability to segment based on text prompts, enabling natural language object detection in images and videos. Whereas previous models required clicking or visually identifying regions, SAM 3 accepts noun phrases like "red baseball cap" or "yellow school bus" and generates segmentation masks for all matching instances in a scene. Meta highlights that this capability was highly requested by the open-source developer community. The model uses a unified architecture combining a perception encoder with a detector and tracker to support image and video workflows with minimal user input. Meanwhile, SAM 3D enables 3D reconstruction from a single 2D image. The reconstruction handles occlusion, clutter and real-world complexity, outputting detailed meshes and textured geometry using a progressive training pipeline and a new 3D data engine. Both models can be downloaded from Meta's GitHub listing, Hugging Face listing, or directly from the blog posts. Notably, these models are available under the SAM Licence, a custom, Meta-owned licence for specifically these models that allows both research-related and commercial usage. Apart from making the models available to the open-source community, Meta has also launched the Segment Anything Playground. It is an online platform where users can test out these models without having to download them or run them locally. The platform can be accessed by anyone. Meta is also integrating these models into its own platforms. Instagram's Edits app will soon be integrated with SAM 3, offering new effects that creators can apply to specific people or objects in their videos. This feature is also being added to Vibes on the Meta AI app and the website. On the other hand, SAM 3D is now powering Facebook Marketplace's new View in Room feature, which lets users visualise the style and fit of home decor items in their spaces before making a purchase.
[5]
Meta unveils SAM 3, its most advanced AI model for visual understanding yet
A new SAM 3D model suite adds object reconstruction and human pose estimation for AR, robotics, and spatial computing. Meta has introduced the Segment Anything Model 3 (SAM 3), the next generation of visual understanding tools. The new model includes big improvements in object detection, segmentation, and tracking across images and videos. Users can now use text-based and exemplar prompts to identify and segment almost any visual concept. Meta has also introduced the Segment Anything Playground. This new interface allows the general public to experiment with SAM 3 and test its media editing capabilities without the need for technical knowledge. The company will also release model weights, a detailed research paper, and a new evaluation benchmark called SA-Co (Segment Anything with Concepts) to assist developers working on open-vocabulary segmentation. Meta is also releasing SAM 3D, a collection of models capable of object and scene reconstruction, as well as human pose and shape estimation, with applications in augmented reality, robotics, and other spatial computing fields. SAM 3 introduces "promptable concept segmentation," which enables the model to segment anything users describe using short noun phrases or image examples. Meta claims SAM 3 outperforms previous systems on its new SA-Co benchmark for both images and video. The model accepts a variety of prompts, such as masks, bounding boxes, points, text, and image examples, giving users multiple options for specifying what they want to detect or track. The new model was trained using a large-scale data pipeline that included human annotators, SAM 3, and supporting AI systems like a Llama-based captioner. It processes and labels visual data much more efficiently than traditional methods, reducing annotation time and allowing for a dataset of over 4 million visual concepts. Meta already uses SAM 3 and SAM 3D to power features like View in Room on Facebook Marketplace, which allows customers to see furniture in their own homes. The technology will also be integrated into upcoming visual editing tools on the Meta AI, Meta.AI, and Edits apps.
Share
Share
Copy Link
Meta releases its third-generation Segment Anything Models (SAM 3 and SAM 3D) featuring enhanced object detection, text-based prompting, and 3D reconstruction capabilities. The open-source models advance visual intelligence for content editing, wildlife conservation, and AR applications.
Revolutionary Visual Intelligence Technology
Meta has unveiled its third-generation Segment Anything Models (SAM 3 and SAM 3D), marking a significant advancement in computer vision and visual intelligence technology.
1
These models represent a major leap forward from traditional object detection systems, introducing "promptable concept segmentation" capabilities that allow users to identify and segment visual elements using natural language descriptions.
Source: SiliconANGLE
Enhanced Object Detection and Segmentation
The SAM 3 model addresses a fundamental challenge in computer vision: linking natural language to specific visual elements in images and videos.
2
Unlike previous models that were limited to fixed label sets and could only segment common concepts like "person" or "car," SAM 3 can handle nuanced descriptions such as "the striped red umbrella" or "yellow school bus."3
The model accepts various input types including text prompts, image exemplars, masks, bounding boxes, and points, providing users with multiple ways to specify what they want to detect or track.
4
This flexibility enables applications ranging from simple photo editing to complex video analysis tasks.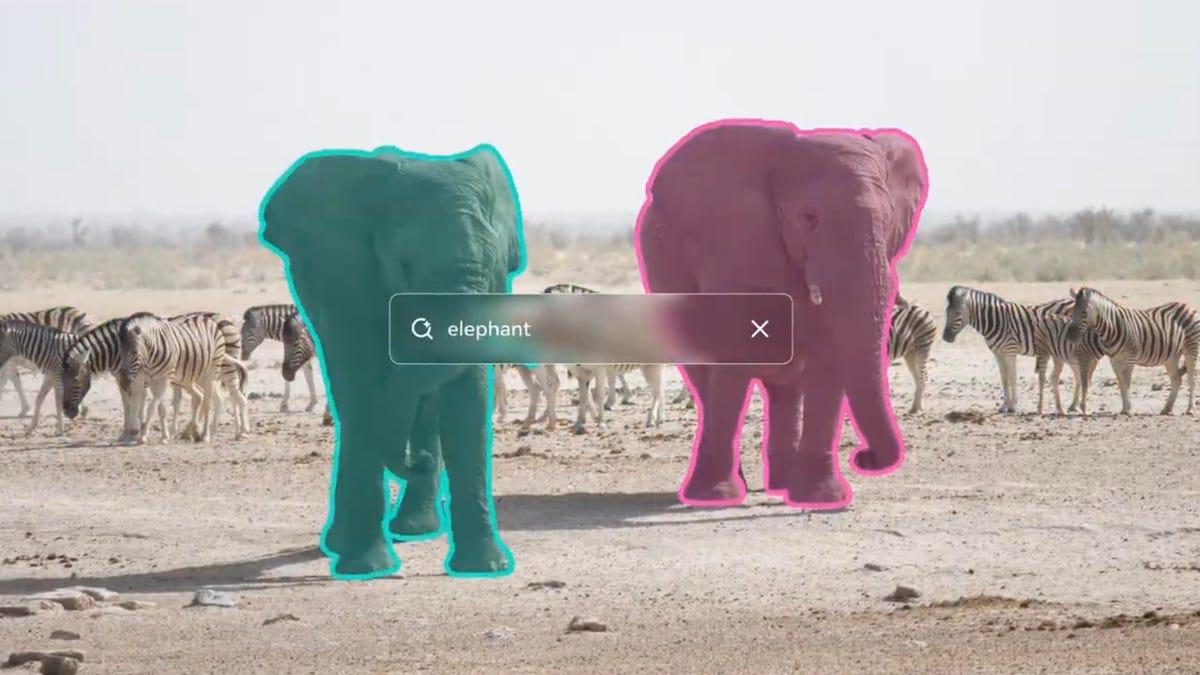
Source: CNET
3D Reconstruction Capabilities
SAM 3D introduces groundbreaking three-dimensional reconstruction capabilities, consisting of two specialized models: SAM 3D Objects for object and scene reconstruction, and SAM 3D Body for human pose and shape estimation.
3
These models can generate detailed 3D meshes and textured geometry from single 2D images, handling real-world complexity including occlusion and clutter.The 3D reconstruction technology has immediate applications in augmented reality, robotics, and spatial computing. Users can potentially reconstruct 3D likenesses of people from photographs and import them into videos or virtual reality environments, opening new possibilities for creative content and memorial applications.
Training and Technical Architecture
Meta developed SAM 3 using an innovative data engine that combines human annotators with AI systems, including Llama-based captioners.
5
The model architecture builds upon Meta's Perception Encoder and incorporates components from the DETR model, which pioneered the use of transformers for object detection.The training process involved processing over 4 million visual concepts, significantly reducing annotation time compared to traditional methods.
5
Meta claims SAM 3 doubles the cgF1 scores (a measure of concept recognition and localization) compared to existing models and consistently outperforms foundational models like Gemini 2.5 Pro.Related Stories

Real-World Applications and Partnerships
The models are already being deployed in scientific research and conservation efforts. Meta partnered with ConservationX Labs and Osa Conservation to create the SA-FARI dataset, containing over 10,000 camera trap videos of more than 100 species with detailed annotations.
2
This collaboration demonstrates the technology's potential for wildlife monitoring and conservation research.
Source: Digit
Additionally, Meta is working with FathomNet and MBARI to advance AI tools for ocean exploration, providing segmentation masks and benchmarks tailored for underwater imagery.
2
These partnerships highlight the models' versatility across different scientific domains.Platform Integration and Accessibility
Meta is integrating these technologies across its platforms, with SAM 3 powering enhanced editing capabilities in Instagram's Edits app and the Vibes platform.
4
The Facebook Marketplace "View in Room" feature utilizes SAM 3D to help users visualize furniture and home decor items in their own spaces before purchasing.To democratize access to these advanced capabilities, Meta launched the Segment Anything Playground, an online platform where users can experiment with the models without technical expertise.
5
The company is releasing model weights, code, and evaluation benchmarks under the SAM License, supporting both research and commercial applications.References
Summarized by
Navi
[3]
Related Stories
Meta Unveils SAM 2: A Revolutionary AI Model for Video Object Manipulation
31 Jul 2024

Meta Unveils Suite of Advanced AI Models and Tools, Emphasizing Open-Source Collaboration
20 Oct 2024•Technology

Meta releases SAM Audio AI model to isolate and edit sounds with simple text prompts
16 Dec 2025•Technology

Recent Highlights
1
Tennessee Teens Sue Elon Musk's xAI Over Grok AI-Generated Child Abuse Images
Policy and Regulation

2
Supermicro Co-Founder Indicted in $2.5 Billion Nvidia AI Chip Smuggling Scheme to China
Policy and Regulation

3
Val Kilmer to appear posthumously in As Deep as the Grave through AI-generated performance
Entertainment and Society

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.