AMD Unveils Next-Gen AI Accelerators: MI325X and MI355X to Challenge Nvidia's Dominance
5 Sources
5 Sources
[1]
AMD Instinct MI325X Is The First AI GPU To Pack 256 GB HBM3e Memory, 288 GB MI355X "CDNA 4" Next Year With 8x Performance Uplift
AMD has launched its latest Instinct MI325X AI GPU accelerator which comes packed with 256 GB HBM3e memory while next year's MI355X gets 288 GB. As part of today's "Advancing AI" event, AMD is rolling out its brand new Instinct MI325X AI GPU Accelerator which improves upon the MI300X with brand new capabilities. But before we get into the details, we have to talk about AMD's Instinct platform as a whole which has garnered support from the world's top AI companies and is being used by some of the biggest brands such as Meta, OpenAI and Microsoft. AMD's commitment towards performance leadership, easy migration, an open ecosystem, and customer-focused portfolio has led to huge support from leading OEMs and cloud partners, and as such, the company has fast-tracked the launch of its next-solution as the AI demands in the industry grow to unparalleled heights. Currently, AMD's MI300X is said to offer up to 30% higher performance across a range of AI-specific workloads against the NVIDIA H100. AMD's added work to their ROCm suite is helping extract more performance out of the flagship accelerator but now's the time to build even better hardware with the same robust software support. Meet the AMD Instinct MI325X, this brand-new accelerator is built upon the same fundamental design and architecture as the MI300X. Using the CDNA 3 GPU architecture, the MI325X can be seen as a mid-cycle upgrade, offering 256 GB of HBM3e memory made using 16-Hi stacks with up to 6 TB/s of memory bandwidth, 2.6 PFLOPs of FP8, 1.3 PFLOPs of FP16 performance, all packed within a chip with 153 Billion transistors. AMD expects the first production of Instinct MI325X AI GPUs starting in Q4 2024 along with the availability of respective server solutions starting in Q1 2025 through leading partners. The AI Instinct servers will be featuring up to 8 MI325X configurations with up to 2 TB of HBM3e memory, 896 GB/s of infinity fabric bandwidth, 48 TB/s of memory bandwidth, 20.8 PFLOPs of FP8 and 10.4 PFLOPs of FP16 performance. Each GPU is also configured at 1000W which is a big uptick over the 750-700W configurations of the MI300X. Drilling down the numbers, AMD claims that the Instinct MI325X AI GPU accelerator should be 40% faster than the NVIDIA H200 in Mixtral 8x7B, 30% faster in Mistral 7B, and 20% faster in Meta Llama 3.1 70B LLMs. An 8x MI325X platform will also offer 40% faster performance versus an H200 HGX AI platform in Llama 3.1 405B and 20% faster in the 70B inference test. In terms of AI training, MI325X will offer similar or 10% better performance than the H200 platforms. Next year, AMD plans to launch a brand new Instinct MI355X GPU accelerator which will target AI workloads and this will be built using a 3nm process node. The GPU will incorporate the CDNA 4 architecture. In terms of specs, the memory will be upgraded to even higher capacities, up to 288 GB HBM3e while offering support for FP4/FP6 Data types. AMD says that the CDNA 4 architecture delivers a 35x performance leap over CDNA 3 plus a 7x increase in AI compute, 50% increase in memory capacity/bandwidth, and also comes with the latest networking efficiency advancements. In terms of performance, the AMD Instinct MI355X AI GPU will offer up to 2.3 PFLOPs of FP16 performance, an 80% increase over the MI325X while the FP8 figures also see an 80% increase to 4.6 PFLOPs versus the MI325X. The new FP6 and FP4 compute performance is rated at 9.2 PFLOPs. The MI355X will mark a 50% increase in both memory capacities and memory bandwidth, with up to 8 TB/s speeds over the current-gen MI300X. The first platforms featuring eight of these MI355X GPUs will be available in the second half of 2025 and offer up to 2.3 TB of HBM3E memory capacity with 64 TB/s bandwidth, 18.5 PFLOPs of FP16, 37 PFLOPs of FP8, & 74 PFLOPs of FP6/FP4 compute. Moving back to the software front, AMD is announcing its latest ROCm 6.2 ecosystem which brings an average performance improvement of 2.4x and up to 2.8x across a range of AI workloads within Inferencing and an average 2.4x improvement in Training performance. Lastly, AMD is still confirming its Instinct MI400 which was released in 2026 as a "CDNA Next" part and not using the recently disclosed UDNA architecture name. Maybe it's a bit too early to go with the UDNA naming since it hasn't been made official by AMD despite one of their top representatives confirming it so we will see how that goes in the future. With that said, AMD looks to be going all in on the AI craze with the future Instinct offerings, bringing heated competition against the likes of NVIDIA and also tackling Intel who have been struggling to catch up with the rest.
[2]
AMD reveals core specs for Instinct MI355X CDNA4 AI accelerator -- slated for shipping in the second half of 2025
AMD provided more details on its upcoming Instinct MI350 CDNA4 AI accelerator and data center GPU today, formally announcing the Instinct MI355X. It also provided additional details on the now-shipping MI325X, which apparently received a slight trim on memory capacity since the last time AMD discussed it. MI355X is slated to begin shipping in the second half of 2025, so it's still a ways off. However, AMD has seen massive adoption of its AI accelerators in recent years, with the MI300 series being the fastest product ramp in AMD's history, so like Nvidia, it is now on a yearly cadence for product launches. Let's start with the new Instinct MI355X. The whole MI350 series feels a bit odd in terms of branding, considering CDNA was used with the MI100, then CDNA2 in the MI200 series, and CDNA3 has powered the MI300 series for the past year or so. And now, we have CDNA4 powering ... MI350. Why? We've asked and we'll see if there's a good answer. There is an MI400 series in development already, currently slated for a 2026 launch, and maybe that was already in progress before AMD pivoted and decided to add some additional products. Regardless of the product name, CDNA4 does represent a new architecture. AMD said it was a "from the ground up redesign" in our briefing, though that's perhaps a bit of an exaggeration. MI355X will use TSMC's latest N3 process node, which does require a fundamental reworking compared to N5, but the core design likely remains quite similar to CDNA3. What is new is support for the FP4 and FP6 data types. AMD is presenting the MI355X as a "preview" of what will come, and as we'll discuss below, that means some of the final specifications could change. It will support up to 288GB of HBM3E memory, presumably across eight stacks. AMD said it will feature 10 "compute elements" per GPU, which really doesn't tell us much about the potential on its own, but AMD did provide some other initial specifications. The MI300X currently offers 1.3 petaflops of FP16 compute and 2.61 petaflops of FP8. The MI355X by comparison will boost those to 2.3 and 4.6 petaflops, for FP16 and FP8. That's a 77% improvement relative to the previous generation -- and note also that the MI325X has the same compute as the MI300X, just with 33% more HBM3E memory and a higher TDP. MI355X doesn't just have more raw compute, however. The introduction of the FP4 and FP6 numerical formats doubles the potential compute yet again relative to FP8, so that a single MI355X offers up to 9.2 petaflops of FP4 compute. That's an interesting number, as the Nvidia Blackwell B200 also offers 9 petaflops of dense FP4 compute -- with the higher power GB200 implementation offering 10 petaflops of FP4 per GPU. Based on that spec alone, AMD will potentially deliver roughly the same AI computational horsepower with MI355X as Nvidia will have with Blackwell. AMD will also offer up to 288GB of HBM3E memory, however, which is 50% more than what Nvidia offers with Blackwell right now. Both Blackwell and MI355X will have 8 TB/s of bandwidth per GPU. Of course, there's more to AI than just compute, memory capacity, and bandwidth. Scaling up to higher numbers of GPUs often becomes the limiting factor beyond a certain point, and we don't have any details on whether AMD is making any changes to the interconnects between GPUs. That's something Nvidia talked about quite a bit with it's Blackwell announcement, so it will be something to pay attention to when the products start shipping. The other part of today's AMD Instinct announcement is that the MI325X has officially launched and is entering full production this quarter. However, along with the announcement comes an interesting nugget: AMD cut the maximum supported memory from 288GB (that's what it had stated earlier) to 256GB per GPU. The main change from MI300X to MI325X was the amount of memory per GPU, with MI300X offering up to 192GB. So initially, AMD was looking at a 50% increase with MI325X, but now it has cut that to a 33% increase. AMD showed a few performance numbers comparing MI325X with Nvidia H200, with a slight lead in single GPU performance, and parity for an eight GPU platform. We mentioned earlier how scaling can be a critical factor for AI platforms, and this indicates Nvidia still has some advantages in that area. AMD didn't get into the pricing of its AI accelerators, but when questioned said that the goal is to provide a TCO (Total Cost of Ownership) advantage. That can come either by offering better performance for the same price, or by having a lower price for the same performance, or anywhere along that spectrum. Or as AMD put it: "We are responsible business people and we will make responsible decisions" -- as far as pricing goes. It remains to be seen how AMD's latest parts stack up to Nvidia's H100 and H200 in a variety of workloads, not to mention the upcoming Blackwell B200 family. It's clear that AI has become a major financial boon for Nvidia and AMD lately, and until that changes, we can expect to see a rapid pace of development and improvement for the data center. The full slide deck from the presentation can be found below, with most of the remaining slides providing background information on the AI accelerator market and AMD's partners.
[3]
AMD releases details of 288GB MI355X accelerator: 80% faster than MI325X, 8TB/s memory bandwidth
Rival to Nvidia Blackwell has some tasty specs, but will it be enough to catch up with Nvidia? We already knew a lot about AMD's next generation accelerator, the Instinct MI325X, from an earlier event in June 2024 - but the company has now revealed more at its AMD Advancing AI event. First, we knew the Instinct MI325X was a minor upgrade from the MI300X, with the same CDNA 3 architecture, but just enough oomph to make it a viable alternative to the H200, Nvidia's AI powerhouse. Eagle-eyed readers will also notice that AMD has cut the onboard HBM3e memory capacity from 288GB to 256GB with the memory capacity now only 80% more than Nvidia's flagship rather than the more enviable 2x improvement. To make things a bit more murkier, AMD also mentioned another SKU, the MI325X OAM which will have, wait for it, 288GB memory - we have asked for clarification and will update this article in due course. AMD provided some carefully selected performance comparisons against Nvidia's H200: The company also revealed the accelerator has 153 billion transistors, which is the same as the MI300X. The H200 has only 80 billion transistors while Blackwell GPUs will top the scale at more than 200 billion transistors. The star of the show though had to be the MI355X accelerator, which was also announced at the event with an H2 2025 launch date. Manufactured on TSMC's 3nm node and featuring AMD's new CDNA 4 architecture, it introduces FP6 and FP4 formats and is expected to deliver improvements on 80% on FP16 and FP8, compared to the current MI325X accelerator. Elsewhere, the Instinct MI355X will offer 288GB HBM3E and 8TB/s memory bandwidth, a 12.5% and 33.3% improvement on its immediate predecessor. An 8-unit OXM platform, which will also be launched in H2 2025, will offer a staggering 18.5 petaflops in FP16, 37PF in FP8, 74PF in FP6 and FP4 (or 9.3PF per OXM). The MI355x will compete against Nvidia's Blackwell B100 and B200 when it launches in 2025, and will be instrumental in Lisa Su's attempt to supercharge AMD's aspirations to catch up with its rival. Nvidia remains firmly in the driving seat, with more than 90% of the world's AI accelerator market, making it the world's most valuable company at the time of writing, with its share price at its all time high and a market capitalization of $3.3 trillion.
[4]
AMD Says Instinct MI325X Bests Nvidia H200, Vows Huge Uplift With MI350
While AMD says its forthcoming Instinct MI325X GPU can outperform Nvidia's H200 for large language model inference, the chip designer is teasing that its next-generation MI350 series will deliver magnitudes of better inference performance in the second half of next year. AMD said its forthcoming 256-GB Instinct MI325X GPU can outperform Nvidia's 141-GB H200 processor on AI inference workloads and vowed that the next-generation MI350 accelerator chips will improve performance by magnitudes. When it comes to training AI models, AMD said the MI325X is on par or slightly better than the H200, the successor to Nvidia's popular and powerful H100 GPU. [Related: Intel Debuts AI Cloud With Gaudi 3 Chips, Inflection AI Partnership] The Santa Clara, Calif.-based chip designer was expected to make the claims at its Advancing AI event in San Francisco, where the company will discuss its plan to take on AI computing giant Nvidia with Instinct chips, EPYC CPUs, networking chips, an open software stack and data center design expertise. "AMD continues to deliver on our roadmap, offering customers the performance they need and the choice they want, to bring AI infrastructure, at scale, to market faster," said Forrest Norrod, head of AMD's Data Center Solutions business group, in a statement. The MI325X is a follow-up with greater memory capacity and bandwidth to the Instinct MI300X, which launched last December and put AMD on the map as a worthy competitor to Nvidia's prowess in delivering powerful AI accelerator chips. It's part of AMD's new strategy to release Instinct chips every year instead of every two years, which was explicitly done to keep up with Nvidia's accelerated chip release cadence. The MI325X is set to arrive in systems from Dell Technologies, Lenovo, Supermicro, Hewlett Packard Enterprise, Gigabyte, Eviden and several other server vendors starting in the first quarter of next year, according to AMD. Whereas the Instinct MI300X features 192GB of HBM3 high-bandwidth memory and 5.3 TB/s in memory bandwidth, the MI325X -- which is based on the same CDNA 3 GPU architecture as the MI300X -- comes with 256GB in HBM3E memory and can reach 6 TB/s in memory bandwidth thanks to the update in memory format. In terms of throughput, the MI325X has the same capabilities as the MI300X: 2.6 petaflops for 8-bit floating point (FP8) performance and 1.3 petaflops for 16-bit floating point (FP16). When comparing AI inference performance to the H200 at a chip level, AMD said the MI325X provides 40 percent faster throughput with an 8-group, 7-billion-parameter Mixtral model; 30 percent lower latency with a 7-billion-parameter Mixtral model and 20 percent lower latency with a 70-billion-parameter Llama 3.1 model. The MI325X will fit into the eight-chip Instinct MI325X platform, which will serve as the foundation for servers launching early next year. With eight MI325X GPUs connected over AMD's Infinity Fabric with a bandwidth of 896 GB/z, the platform will feature 2TB of HBM3e memory, 48 TB/s of memory bandwidth, 20.8 petaflops of FP8 performance and 10.4 petaflops of FP16 performance, AMD said. According to AMD, this means the MI325X platform has 80 percent higher memory capacity, 30 percent greater memory bandwidth and 30 percent faster FP8 and FP16 throughput than Nvidia's H200 HGX platform, which comes with eight H200 GPUs and started shipping earlier this year as the foundation for H200-based servers. Comparing inference performance to the H200 HGX platform, AMD said the MI325X platform provides 40 percent faster throughput with a 405-billion-parameter Llama 3.1 model and 20 percent lower latency with a 70-billion-parameter Llama 3.1 model. When it comes to training a 7-billion-parameter Llama 2 model on a single GPU, AMD said the MI325X is 10 percent faster than the H200, according to AMD. The MI325X platform, on the other hand, is on par with the H200 HGX platform when it comes to training a 70-billion-parameter Llama 2 model across eight GPUs, the company added. AMD said its next-generation Instinct MI350 accelerator chip series is on track to launch in the second half of next year and teased that it will provide up to a 35-fold improvement in inference performance compared to the MI300X. The company said this is a projection based on engineering estimates for an eight-GPU MI350 platform running a 1.8-trillion-parameter Mixture of Experts model. Based on AMD's next-generation CDNA 4 architecture and using a 3-nanometer manufacturing process, the MI350 series will include the MI355X GPU, which will feature 288GB of HBM3e memory and 8 TB/s of memory bandwidth. With the MI350 series supporting new 4-bit and 6-bit floating point formats (FP4, FP6), the MI355X is capable of achieving 9.2 petaflop, according to AMD. For FP8 and FP16, the MI355X is expected to reach 4.6 petaflops and 2.3 petaflops, respectively. This means the next-generation Instinct chip is expected to provide 77 percent faster performance with the FP8 and FP16 formats than the MI325X or MI300X. Featuring eight MI355X GPUs, the Instinct MI355X platform is expected to feature 2.3TB of HBM3e memory, 64 TB/s of memory bandwidth, 18.5 petaflops of FP16 performance, 37 petaflops of FP8 performance as well as 74 petaflops of FP6 and FP4 performance. With the 74 petaflops of FP6 and FP4 performance, the MI355X platform is expected to be 7.4 times faster than FP16 capabilities of the MI300X platform, according to AMD. The MI355X platform's 50 percent greater memory capacity means it can support up to 4.2-trillion-parameter models on a single system, which is six times greater than what was capable with the MI300X platform. After AMD debuts the MI355X in the second half of next year, the company plans to introduce the Instinct MI400 series in 2026 with a next-generation CDNA architecture. AMD said it is introducing new features and capabilities in its AMD ROCm open software stack, which includes new algorithms, new libraries and expanding platform support. The company said ROCm now supports the "most widely used AI frameworks, libraries and models including PyTorch, Triton, Hugging Face and many others." "This work translates to out-of-the-box performance and support with AMD Instinct accelerators on popular generative AI models like Stable Diffusion 3, Meta Llama 3, 3.1 and 3.2 and more than one million models at Hugging Face," AMD said. With the new 6.2 version of ROCm, AMD will support the new FP8 format, Flash Attention 3 and Kernel Fusion, among other things. This will translate into a 2.4-fold improvement on inference performance and 80 percent better training performance for a variety of large language models, according to the company.
[5]
AMD gun for Nvidia H200 with MI325X AI chips
AMD boosted the VRAM on its Instinct accelerators to 256 GB of HBM3e with the launch of its next-gen MI325X AI accelerators during its Advancing AI event in San Francisco on Thursday. The part builds upon AMD's previously announced MI300 accelerators introduced late last year, but swaps out its 192 GB of HBM3 modules for 256 GB of faster, higher capacity HBM3e. This approach is similar in many respects to Nvidia's own H200 refresh from last year, which kept the compute as is but increased memory capacity and bandwidth. For many AI workloads, the faster the memory and the more you have of it, the better performance you'll extract. AMD has sought to differentiate itself from Nvidia by cramming more HBM onto its chips, which is making them an attractive option for cloud providers like Microsoft looking to deploy trillion parameter-scale models, like OpenAI's GPT4o, on fewer nodes. However, the eagle-eyed among you may be scratching your heads wondering: wasn't this chip supposed to ship with more memory? Well, yes. When the part was first teased at Computex this spring, it was supposed to ship with 288 GB of VRAM on board -- 50 percent more than its predecessor, and twice that of its main competitor Nvidia's 141 GB H200. Four months later, AMD has apparently changed its mind and is instead sticking with eight 32 GB stacks of HBM3e. Speaking to us ahead of AMD's Accelerating AI event in San Francisco where we were on-site on Thursday, Brad McCredie, VP of GPU platforms at AMD, said the reason for the change came down to architectural designs made early on in the products development. "We actually said at Computex up to 288 GB, and that was what we were thinking at the time," he said. "There are architectural decisions we made a long time ago with the chip design on the GPU side that we were going to do something with software we didn't think was a good cost-performance trade off, and we've gone and implemented at 256 GB." "It is what the optimized design point is for us with that product," VP of AMD's Datacenter GPU group Andrew Dieckmann reiterated. While maybe not as memory-dense as they might have originally hoped, the accelerator does still deliver a decent uplift in memory bandwidth at 6 TB/s compared to 5.3 TB/s on the older MI300X. Between the higher capacity and memory bandwidth -- 2 TB and 48 TB/s per node -- that should help the accelerator support larger models while maintaining acceptable generation rates. Curiously all that extra memory comes with a rather large increase in power draw, which is up 250 watts to 1,000 watts. This puts it in the same ball park as Nvidia's upcoming B200 in terms of TDP. Unfortunately for all that extra power, it doesn't seem the chip's floating point precision has increased much from the 1.3 petaFLOPS of dense FP16 or 2.6 petaFLOPS at FP8 of its predecessor. Still, AMD insists that in real-world testing, the part manages a 20-40 percent lead over Nvidia's H200 in inference performance in Llama 3.1 70B and 405B respectively. Training Llama 2 70B, performance is far closer with AMD claiming a roughly 10 percent advantage for a single MI325X and equivalent performance at a system level. AMD Instinct MI325X accelerators are currently on track for production shipments in Q4 with systems from Dell Technologies, Eviden, Gigabyte Technology, Hewlett Packard Enterprise, Lenovo, Supermicro and others hitting the market in Q1 2025. While the MI325X may not ship with 288 GB of HBM3e, AMD's next Instinct chip, the MI355X, due out in the second half of next year, will. Based on AMD's upcoming CDNA 4 architecture, it also promises higher floating point performance, up to 9.2 dense petaFLOPS when using the new FP4 or FP6 data types supported by the architecture. If AMD can pull it off, that'll put it in direct contention with Nvidia's B200 accelerators, which are capable of roughly 9 petaFLOPS of dense FP4 performance. For those still running more traditional AI workloads (funny that there's already such a thing) using FP/BF16 and FP8 data types, AMD says it's boosted performance by roughly 80 percent to 2.3 petaFLOPS and 4.6 petaFLOPS, respectively. In an eight-GPU node, this will scale to 2.3 terabytes of HBM and 74 petaFLOPS of FP4 performance -- enough to fit a 4.2 billion parameter model into a single box at that precision, according to AMD. Alongside its new accelerators, AMD also teased its answer to Nvidia's InfiniBand and Spectrum-X compute fabrics and BlueField data processors, due out early next year. Developed by the AMD Pensando network team, the Pensando Pollara 400 is expected to be the first NIC with support for the Ultra Ethernet Consortium specification. In an AI cluster, these NICs would support the scale-out compute network used to distribute workloads across multiple nodes. In these environments, packet loss can result in higher tail latencies and therefore slower time to train models. According to AMD, on average, 30 percent of training time is spent waiting for the network to catch up. Pollara 400 will come equipped with a single 400 GbE interface while supporting the same kind of packet spraying and congestion control tech we've seen from Nvidia, Broadcom and others to achieve InfiniBand-like loss and latencies. One difference the Pensando team was keen to highlight was the use of its programmable P4 engine versus a fixed function ASIC or FPGA. Because the Ultra Ethernet specification is still in its infancy, it's expected to evolve over time. So, a part that can be reprogrammed on the fly to support the latest standard offers some flexibility for early adopters. Another advantage Pollara may have over something like Nvidia's Spectrum-X Ethernet networking platform is the Pensando NIC, which won't require a compatible switch to achieve ultra-low loss networking. In addition to the backend network, AMD is also rolling out a DPU called Salina, which features twin 400 GbE interfaces, and is designed to service the front-end network by offloading various software defined networking, security, storage, and management functions from the CPU. Both parts are already sampling to customers with general availability slated for the first half of 2025. ®
Share
Share
Copy Link
AMD announces its latest AI GPU accelerators, the Instinct MI325X and MI355X, aiming to compete with Nvidia's offerings in the rapidly growing AI chip market.

AMD Launches Instinct MI325X: A Mid-Cycle Upgrade
AMD has unveiled its latest AI GPU accelerator, the Instinct MI325X, as part of its "Advancing AI" event. This new accelerator builds upon the CDNA 3 architecture of its predecessor, the MI300X, offering significant improvements in memory capacity and bandwidth
1
.Key features of the MI325X include:
- 256 GB of HBM3e memory (up from 192 GB in MI300X)
- 6 TB/s of memory bandwidth
- 2.6 PFLOPs of FP8 and 1.3 PFLOPs of FP16 performance
- 153 Billion transistors
- 1000W TDP per GPU
AMD claims the MI325X outperforms NVIDIA's H200 in various AI workloads, including a 40% performance advantage in Mixtral 8x7B inference
1
2
.Next-Generation MI355X: CDNA 4 Architecture
Looking ahead, AMD has also previewed its next-generation AI accelerator, the Instinct MI355X, scheduled for release in the second half of 2025
3
. Built on TSMC's 3nm process, the MI355X will feature:- CDNA 4 architecture
- 288 GB of HBM3e memory
- 8 TB/s of memory bandwidth
- Support for FP4 and FP6 data types
- Up to 2.3 PFLOPs of FP16 and 4.6 PFLOPs of FP8 performance
- 9.2 PFLOPs of FP4/FP6 compute performance
AMD projects a 35x performance leap over CDNA 3, with a 7x increase in AI compute and a 50% increase in memory capacity and bandwidth
1
4
.Competitive Landscape and Market Impact
The introduction of these new accelerators positions AMD to compete more effectively with NVIDIA in the AI chip market. While NVIDIA currently dominates with over 90% market share, AMD's aggressive development cycle and performance claims suggest a narrowing gap
5
.Key competitive aspects include:
- Memory capacity advantage: MI355X's 288 GB vs. NVIDIA H200's 141 GB
- Comparable FP4 compute: 9.2 PFLOPs for MI355X vs. 9 PFLOPs for NVIDIA's Blackwell B200
- Focus on inference performance: AMD claims significant advantages in LLM inference tasks
Related Stories

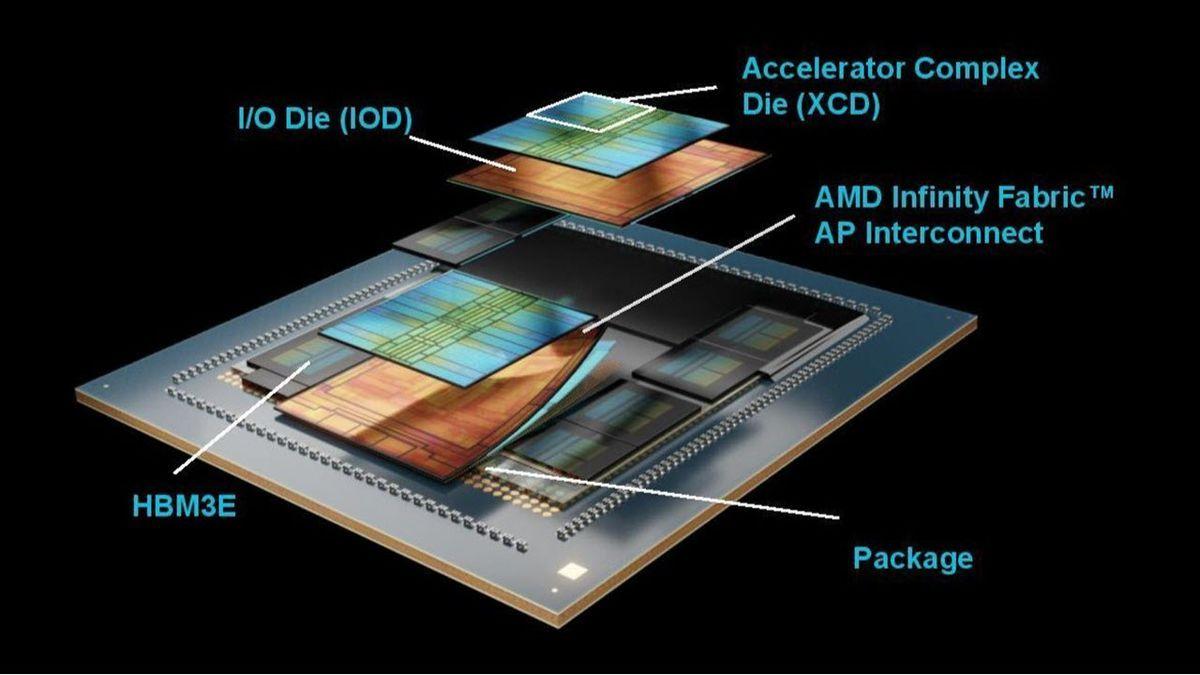


Industry Adoption and Future Outlook
AMD's Instinct accelerators have gained support from major AI companies and cloud providers, including Meta, OpenAI, and Microsoft
1
. The company's commitment to an open ecosystem and customer-focused portfolio has contributed to this adoption.As the AI accelerator market continues to grow, AMD's yearly release cadence for Instinct GPUs mirrors NVIDIA's approach, indicating an intensifying competition in this crucial tech sector
2
4
. The success of these new accelerators could potentially reshape the AI hardware landscape in the coming years.References
Summarized by
Navi
[2]
[3]
[5]
Related Stories
Recent Highlights
1
AI chatbots validate you too much, making you less kind to others, Stanford study reveals
Science and Research

2
Anthropic's Claude Code Source Leak Reveals Hidden AI Agent Plans and Extensive System Access
Technology

3
Judge blocks Pentagon from branding Anthropic a security risk over AI safety guardrails dispute
Policy and Regulation

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.