Confluent Unifies Batch and Stream Processing to Enhance AI Capabilities
4 Sources
4 Sources
[1]
Confluent tackles enterprise AI agent complexity with batch and streaming data unification
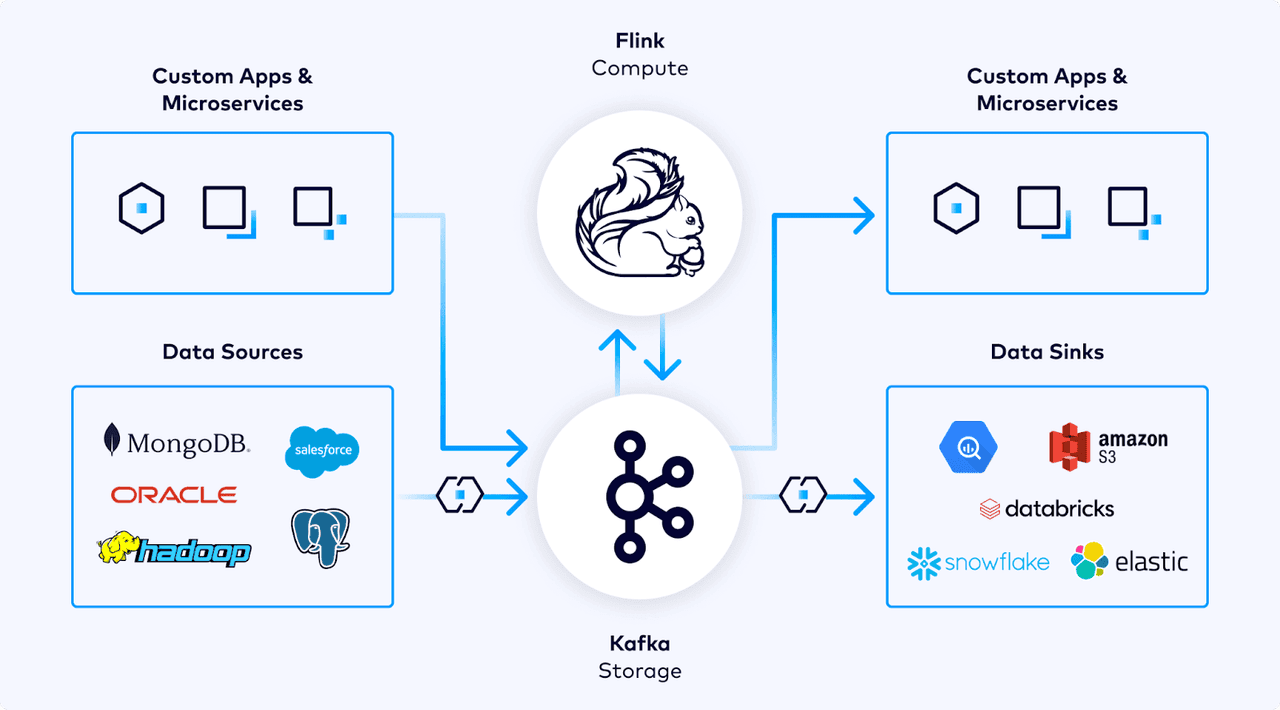
Confluent has announced new capabilities for its cloud platform that aim to unify batch and stream processing, with the ambition of positioning the vendor as a key infrastructure provider for organizations looking to build reliable AI agents. The data streaming company unveiled snapshot queries at its Current London event today, a feature that enables the processing of both real-time and historical data in a single environment. For enterprises attempting to develop reliable AI applications and agents, the challenges are well documented. Organizations struggle with fragmented data infrastructures where operational data and analytical data exist in separate silos, making it difficult to provide AI systems with both real-time insights and historical context. This often leads to either AI applications that lack crucial historical patterns or systems that operate on outdated information - this can be risky, both in terms of reputation and compliance. Additionally, the complexity of securing data across these environments has hampered adoption of AI agents that require continuous access to sensitive enterprise information. The announcement builds on Confluent's strategy to unite what CEO Jay Kreps previously described as "the two sides of the enterprise data house" - operations and analytics. It also reinforces the company's thesis that AI agents require a continuous flow of trusted, real-time data to be effective, rather than relying on more static data warehousing approaches. During his presentation in London today, Kreps explained why this unification of batch and streaming data matters in the context of AI and agents: I'm going to be talking about this unification of streaming and batch, and a little bit about what it means in the age of AI and agents. There's a larger theme here, which is, in some sense, companies are [essentially] becoming much more software. It used to be a purely human activity, but now we started to build software systems that don't just support the business, they actually run it. The problem, according to Kreps, is that today's data infrastructure isn't optimized for AI agents that need to operate continuously and make real-time decisions. Most enterprises have traditionally relied on batch processing that updates data periodically rather than continuously: Batch processing isn't that bad in some ways. It's not quite three cheers for batch processing; but there's two solid cheers. Because there's some things that it gets really right. He points out that batch systems do provide access to comprehensive data from warehouses that cut across different domains, making them useful for data-intensive applications. They also offer a structured way to process inputs into outputs that can be refined iteratively. However, he adds: But you don't really get the third thing. If anyone has ever tried to take batch processing and integrate it back into the operation of a real-time business, you start to find this very hard. Customers expect all the things that they see to be up to date. The business is running continuously, but you ultimately have to end up doing all these weird hacks to get this into production. To address this challenge, Confluent has introduced snapshot queries in early access, which allow teams to unify historical and streaming data using a single product and language. The feature integrates with Tableflow, enabling organizations to gain context from past data without spinning up new workloads. According to Confluent, this makes it easier to supply agents with context from historic and real-time data or conduct audits to understand key trends and patterns. This development represents a significant evolution of the Tableflow capabilities that Confluent announced earlier this year. Back in March, Kreps explained how Tableflow transforms Apache Kafka topics and their associated schemas to Apache Iceberg tables, making it easier to supply data lakes and data warehouses. The concept of bringing together streams (the flow of events happening in real-time) and tables (the current state of the world) is foundational to Confluent's strategy, as Kreps explains today: This concept also shows up in core databases. You have this idea of the commit log, which changes with respect to the stream of updates to your data. And now you have the tables of data that are sitting in the database. These two things are actually directly related. The stream of changes is what populates the tables. He continues: The tables are kind of just like an optimization - if you had the log of all the changes, you'd actually have all of the data and be able to recreate it, not just in its current state, but at any point in time. This is the same relationship, if you think about it, that Kafka and Tableflow have. Beyond the data processing capabilities, Confluent has also announced new security features. Confluent Cloud network (CCN) routing aims to simplify private networking for Apache Flink, while IP Filtering adds access controls for publicly accessible Flink pipelines. CCN routing allows organizations to securely connect their data to any Flink workload, such as streaming pipelines, AI agents, or analytics and is now generally available on Amazon Web Services in all regions where Flink is supported. For organizations operating in hybrid environments that need more control over public data access, the IP Filtering feature for Flink helps teams restrict internet traffic to allowed IPs and improves visibility into unauthorized access attempts. This feature is generally available for all Confluent Cloud users. These product announcements align with Confluent's previously articulated vision that AI agents require a different approach to data infrastructure. The company has been consistent in its message that traditional data warehouses or lakehouses aren't ideal for AI agent development. The argument centers on three main challenges with traditional approaches: the fragility of after-the-fact governance where teams scrape data from different systems; the inherent slowness of batch processing, which doesn't align with business real-time needs; and the difficulty in ensuring data accuracy when it's disconnected from its original context. Instead, Confluent is advocating for "shifting left" data governance closer to the teams that own their software or products, creating a scenario where teams look after what data is published to the rest of the enterprise. Today, Kreps expands on this vision of how data streaming represents a fundamental infrastructure shift: When you do this, you get a unified dataset that is actually the basis for stream processing. This is not a skin-deep integration, it's not a connector that sends the data off to some Iceberg thing, this is actually a fundamental representation. This is what we have done with Tableflow, we have literally unified this stream-table duality into something that represents the full lifecycle of data. The driver behind Confluent's product strategy is the company's belief that AI agents - software systems that can autonomously perform tasks - require continuous access to accurate, up-to-date data to be effective, whilst also needing historical context. For example, for fraud detection, banks need real-time data to react in the moment and historical data to see if a transaction fits a customer's usual patterns. The company has consistently argued that stream processing, particularly through Apache Flink, plays a crucial role in enabling these AI agents by allowing organizations to combine, develop, and reshape data streams from across the enterprise. Confluent maintains that reliable data is essential, and that issues caused by hallucinations or poor judgment in AI can often be traced back to wrong input data. These views on data infrastructure for AI signal a significant shift in how enterprises should organize themselves operationally. In Confluent's vision, the infrastructure priorities move from storage to continuous stream processing. Today, Kreps reinforces this idea, explaining: You can really imagine streaming, that's something like 'batch++', where you can run something at a point in time and get a result, but keep running it as that data evolves. This is not a new idea, but in practice, to get this right, there's a number of details you have to put together, to make something that's practical, you have to have all the parts integrated well. He added that one of the crucial requirements for building data-intensive applications, particularly for AI, is "the ability to reprocess data in a really easy-to-do way" - which is precisely what snapshot queries aim to enable. This approach changes how AI systems can be built, moving away from systems that wait for user input and toward software that works continuously, processing streams of data to make ongoing decisions. What makes Confluent's announcement significant is its attempt to simplify what has historically been a complex technical challenge. Stream processing has often faced practical challenges. As Kreps notes: Stream processing in particular has often had a gap between theory and practicality. It's something that has made sense intellectually, but it's hard to do. It doesn't always fulfil this vision of making it really easy to work with data in real-time. By bringing together both the necessary technical components (streams and tables, real-time and historical data) and making them accessible through features like snapshot queries, Confluent is trying to bridge this gap. As Kreps explains: A stream is the flow of events happening in the world. But also you need the tables, the current state of the world. And an intelligent system kind of needs both of these. The stream is like the sensory system giving you awareness, but the tables give you all the stuff that we know right now. This concept also shows up in core databases. You have this idea of the commit log, which changes with respect to the stream of updates to your data. And now you have the tables of data that are sitting in the database. These two things are actually directly related. The stream of changes is what populates the tables. The tables are kind of just like an optimization - if you had the log of all the changes, you'd actually have all of the data and be able to recreate it, not just in its current state, but at any point in time. This is the same relationship, if you think about it, that Kafka and Tableflow have. Kafka is this hub of real-time data that is acting as a commit log across the company, taking all of the updates, all of the things that are happening across the organization, it's applying them across all of the systems. And so the natural thing is to have a stream of data to continuously update the tables. Actually populate the tables. When you do this, you get a unified dataset that is actually the basis for stream processing. This is not a skin-deep integration, it's not a connector that sends the data off to some Iceberg thing, this is actually a fundamental representation. This is what we have done with Tableflow, we have literally unified this stream-table duality into something that represents the full lifecycle of data. And this is a basis for how you make stream processing really practical. If you have these things together, you can really start to realize this vision of making streaming a generalization of batch. For enterprises looking to develop AI agents, this unified approach aims to reduce the complexity and fragility that comes with trying to cobble together different systems for batch and streaming data. Rather than building complex data pipelines that try to bridge real-time data with historical context, organizations could potentially use a single platform that handles both simultaneously. Confluent's announcement represents a significant step in its strategy to position data streaming as the foundation for enterprise AI development. By unifying batch and streaming processing, the company is addressing a real pain point for organizations trying to build AI agents that can operate effectively in real-time business environments. What's particularly interesting about Confluent's approach is how it challenges the conventional wisdom that data warehouses or lakehouses should be the central repository for AI data. Instead, Kreps is advocating for a model where data streams become the primary infrastructure, with tables essentially serving as optimized views of those streams. This has implications for how enterprises architect their data systems. Rather than building AI agents that primarily pull from static repositories of data, they could develop systems that continuously process and react to data as it flows through the organization. The challenge, of course, will be in the implementation. Not just on a technical level, but a cultural one. Getting teams to manage and publish their own data products, whilst moving to a world where the organization makes decisions and takes action based on historical context, as well as real-time streaming, is a bit change. That said, as enterprises increasingly explore more sophisticated AI agents that need to make decisions based on up-to-the-minute data, Confluent's vision becomes compelling. While it's still early days for enterprise AI agents, Confluent is building an infrastructure foundation that could become increasingly important as these applications mature. The real test will be whether organizations find that this unified approach to batch and streaming data genuinely speeds up their AI initiatives, whilst making them more reliable. We look forward to hearing the use cases.
[2]
Confluent Unites Batch and Stream Processing for Faster, Smarter Agentic AI and Analytics
On Confluent Cloud for Apache Flink®, snapshot queries combine batch and stream processing to enable AI apps and agents to act on past and present data New private networking and security features make stream processing more secure and enterprise-ready Confluent, the data streaming pioneer, announced new Confluent Cloud capabilities that make it easier to process and secure data for faster insights and decision-making. Snapshot queries, new in Confluent Cloud for Apache Flink®, bring together real-time and historic data processing to make artificial intelligence (AI) agents and analytics smarter. Confluent Cloud network (CCN) routing simplifies private networking for Apache Flink®, and IP Filtering adds access controls for publicly accessible Flink pipelines, securing data for agentic AI and analytics. "Agentic AI is moving from hype to enterprise adoption as organizations look to gain a competitive edge and win in today's market," said Shaun Clowes, Chief Product Officer at Confluent. "But without high-quality data, even the most advanced systems can't deliver real value. The new Confluent Cloud for Apache Flink® features make it possible to blend real-time and batch data so that enterprises can trust their agentic AI to drive real change." Bridging the Real-Time and Batch Divide "The rise of agentic AI orchestration is expected to accelerate, and companies need to start preparing now," said Stewart Bond, Vice President of Data Intelligence and Integration Software at IDC. "To unlock agentic AI's full potential, companies should seek solutions that unify disparate data types, including structured, unstructured, real-time, and historical information, in a single environment. This allows AI to derive richer insights and drive more impactful outcomes." Agentic AI is driving widespread change in business operations by increasing efficiency and powering faster decision-making by analyzing data to uncover valuable trends and insights. However, for AI agents to make the right decisions, they need historical context about what happened in the past and insight into what's happening right now. For example, for fraud detection, banks need real-time data to react in the moment and historical data to see if a transaction fits a customer's usual patterns. Hospitals need real-time vitals alongside patient medical history to make safe, informed treatment decisions. But to leverage both past and present data, teams often have to use separate tools and develop manual workarounds, resulting in time-consuming work and broken workflows. Additionally, it's important to secure the data that's used for analytics and agentic AI; this ensures trustworthy results and prevents sensitive data from being accessed. Snapshot Queries Unify Processing on One Platform In Confluent Cloud, snapshot queries let teams unify historical and streaming data with a single product and language, enabling consistent, intelligent experiences for both analytics and agentic AI. With seamless Tableflow integration, teams can easily gain context from past data. Snapshot queries allow teams to explore, test, and analyze data without spinning up new workloads. This makes it easier to supply agents with context from historic and real-time data or conduct an audit to understand key trends and patterns. Snapshot queries are now available in early access. CCN Routing Simplifies Private Networking for Flink Private networking is important for organizations that require an additional layer of security. Confluent offers a streamlined private networking solution by reusing existing CCNs that teams have already created for Apache Kafka® clusters. Teams can use CCN to securely connect their data to any Flink workload, such as streaming pipelines, AI agents, or analytics. CCN routing is now generally available on Amazon Web Services (AWS) in all regions where Flink is supported. IP Filtering Protects Flink Workloads in Hybrid Environments Many organizations that operate in hybrid environments need more control over which data can be publicly accessed. IP Filtering for Flink helps teams restrict internet traffic to allowed IPs and improves visibility into unauthorized access attempts by making it easier to track the attempts. IP Filtering is generally available for all Confluent Cloud users. Now organizations can more easily turn the promise of agentic AI into a competitive advantage. To learn more about the other new Confluent Cloud features, including the Snowflake source connector, cross-cloud Cluster Linking, and new Schema Registry private networking features, check out the launch blog. About Confluent Confluent is the data streaming platform that is pioneering a fundamentally new category of data infrastructure that sets data in motion. Confluent's cloud-native offering is the foundational platform for data in motion -- designed to be the intelligent connective tissue enabling real-time data from multiple sources to constantly stream across an organization. With Confluent, organizations can meet the new business imperative of delivering rich, digital frontend customer experiences and transitioning to sophisticated, real-time, software-driven backend operations. To learn more, please visit www.confluent.io.
[3]
Data Streaming Enables AI Product Innovation, say 90% of IT Leaders in New Confluent Report
Confluent, Inc. (Nasdaq: CFLT), the data streaming pioneer, today released findings from its fourth annual Data Streaming Report, which surveyed 4,175 IT leaders across 12 countries. The results make it clear that data streaming platforms (DSPs) are no longer optional; they are critical to artificial intelligence (AI) success and broader business transformation. A majority of IT leaders (89%) see DSPs easing AI adoption by tackling data access, quality, and governance challenges head-on. And that explains why 90% plan to increase investments in DSPs in 2025. This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20250520223665/en/ "From powering agentic AI to enabling real-time fraud detection, data streaming platforms are quickly becoming the fuel for modern enterprises," said Rey Perez, Chief Customer Officer at Confluent. "They are uniquely positioned to address today's most pressing data challenges while enabling innovations that drive businesses into the future." Why It Matters for AI Real-time data is indispensable for AI applications. In order for an AI agent, chatbot, or assistant to provide value, they need instant access to trustworthy data about the business, its customers, and the world around it. This isn't possible without a complete data streaming platform that creates continuous, high quality, and discoverable streams of data that can be consumed anywhere in the organization. Not only is it table stakes for this new wave of AI, but it's core to helping any business run in real time. "Where would we be without a data streaming platform? I think we'd be out of business," said Sudhakar Gopal, EVP & CIO at Citizens Bank. "A data streaming platform makes it easy for us to exchange data between all our point-to-point applications, enabling us to make game-changing decisions in real time." Download the 2025 Data Streaming Report here. The report was based on a survey designed by Freeform Dynamics and conducted by Radma Research. Responses from 4,175 IT leaders were collected across Australia, Canada, France, Germany, India, Indonesia, Japan, Singapore, Spain, the United Arab Emirates, the United Kingdom, and the United States. Qualifying respondents are familiar with data streaming and work at companies with 500 or more employees. Confluent is the data streaming platform that is pioneering a fundamentally new category of data infrastructure that sets data in motion. Confluent's cloud-native offering is the foundational platform for data in motion -- designed to be the intelligent connective tissue enabling real-time data from multiple sources to constantly stream across an organization. With Confluent, organizations can meet the new business imperative of delivering rich, digital frontend customer experiences and transitioning to sophisticated, real-time, software-driven backend operations. To learn more, please visit www.confluent.io. Confluent® and associated marks are trademarks or registered trademarks of Confluent, Inc.
[4]
Confluent Unites Batch and Stream Processing for Faster, Smarter Agentic AI and Analytics
Confluent, Inc. (Nasdaq: CFLT), the data streaming pioneer, announced new Confluent Cloud capabilities that make it easier to process and secure data for faster insights and decision-making. Snapshot queries, new in Confluent Cloud for Apache Flink, bring together real-time and historic data processing to make artificial intelligence (AI) agents and analytics smarter. Confluent Cloud network (CCN) routing simplifies private networking for Apache Flink, and IP Filtering adds access controls for publicly accessible Flink pipelines, securing data for agentic AI and analytics. This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20250520842385/en/ "Agentic AI is moving from hype to enterprise adoption as organizations look to gain a competitive edge and win in today's market," said Shaun Clowes, Chief Product Officer at Confluent. "But without high-quality data, even the most advanced systems can't deliver real value. The new Confluent Cloud for Apache Flink features make it possible to blend real-time and batch data so that enterprises can trust their agentic AI to drive real change." Bridging the Real-Time and Batch Divide "The rise of agentic AI orchestration is expected to accelerate, and companies need to start preparing now," said Stewart Bond, Vice President of Data Intelligence and Integration Software at IDC. "To unlock agentic AI's full potential, companies should seek solutions that unify disparate data types, including structured, unstructured, real-time, and historical information, in a single environment. This allows AI to derive richer insights and drive more impactful outcomes." Agentic AI is driving widespread change in business operations by increasing efficiency and powering faster decision-making by analyzing data to uncover valuable trends and insights. However, for AI agents to make the right decisions, they need historical context about what happened in the past and insight into what's happening right now. For example, for fraud detection, banks need real-time data to react in the moment and historical data to see if a transaction fits a customer's usual patterns. Hospitals need real-time vitals alongside patient medical history to make safe, informed treatment decisions. But to leverage both past and present data, teams often have to use separate tools and develop manual workarounds, resulting in time-consuming work and broken workflows. Additionally, it's important to secure the data that's used for analytics and agentic AI; this ensures trustworthy results and prevents sensitive data from being accessed. Snapshot Queries Unify Processing on One Platform In Confluent Cloud, snapshot queries let teams unify historical and streaming data with a single product and language, enabling consistent, intelligent experiences for both analytics and agentic AI. With seamless Tableflow integration, teams can easily gain context from past data. Snapshot queries allow teams to explore, test, and analyze data without spinning up new workloads. This makes it easier to supply agents with context from historic and real-time data or conduct an audit to understand key trends and patterns. Snapshot queries are now available in early access. CCN Routing Simplifies Private Networking for Flink Private networking is important for organizations that require an additional layer of security. Confluent offers a streamlined private networking solution by reusing existing CCNs that teams have already created for Apache Kafka clusters. Teams can use CCN to securely connect their data to any Flink workload, such as streaming pipelines, AI agents, or analytics. CCN routing is now generally available on Amazon Web Services (AWS) in all regions where Flink is supported. IP Filtering Protects Flink Workloads in Hybrid Environments Many organizations that operate in hybrid environments need more control over which data can be publicly accessed. IP Filtering for Flink helps teams restrict internet traffic to allowed IPs and improves visibility into unauthorized access attempts by making it easier to track the attempts. IP Filtering is generally available for all Confluent Cloud users. Now organizations can more easily turn the promise of agentic AI into a competitive advantage. To learn more about the other new Confluent Cloud features, including the Snowflake source connector, cross-cloud Cluster Linking, and new Schema Registry private networking features, check out the launch blog. Confluent is the data streaming platform that is pioneering a fundamentally new category of data infrastructure that sets data in motion. Confluent's cloud-native offering is the foundational platform for data in motion -- designed to be the intelligent connective tissue enabling real-time data from multiple sources to constantly stream across an organization. With Confluent, organizations can meet the new business imperative of delivering rich, digital frontend customer experiences and transitioning to sophisticated, real-time, software-driven backend operations. To learn more, please visit www.confluent.io. As our roadmap may change in the future, the features referred to here may change, may not be delivered on time, or may not be delivered at all. This information is not a commitment to deliver any functionality, and customers should make their purchasing decisions based on features that are currently available. Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc. Apache, Apache Kafka, Kafka, Apache Flink, and Flink are registered trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks. All other trademarks are the property of their respective owners.
Share
Share
Copy Link
Confluent introduces new features in its cloud platform to unify batch and stream processing, aiming to improve AI agent performance and data security for enterprises.
Confluent's New Features Unify Batch and Stream Processing
Confluent, the data streaming pioneer, has announced new capabilities for its cloud platform that aim to unify batch and stream processing, positioning itself as a key infrastructure provider for organizations looking to build reliable AI agents
1
. The company unveiled snapshot queries at its Current London event, a feature that enables the processing of both real-time and historical data in a single environment1
.Addressing Enterprise AI Challenges
Organizations often struggle with fragmented data infrastructures where operational and analytical data exist in separate silos, making it difficult to provide AI systems with both real-time insights and historical context
1
. This can lead to AI applications that either lack crucial historical patterns or operate on outdated information, posing risks in terms of reputation and compliance1
.Snapshot Queries: Unifying Data Processing

Source: diginomica
Snapshot queries in Confluent Cloud allow teams to unify historical and streaming data using a single product and language
2
. This feature integrates with Tableflow, enabling organizations to gain context from past data without spinning up new workloads1
. According to Confluent, this makes it easier to supply agents with context from historic and real-time data or conduct audits to understand key trends and patterns2
.Enhanced Security Features
Confluent has also announced new security features to protect data used for analytics and AI:
-
Confluent Cloud network (CCN) routing: Simplifies private networking for Apache Flink, allowing organizations to securely connect their data to any Flink workload
2
. -
IP Filtering: Adds access controls for publicly accessible Flink pipelines, helping teams restrict internet traffic to allowed IPs and improve visibility into unauthorized access attempts
2
.
Related Stories

Industry Perspective on Data Streaming Platforms
A recent survey conducted by Confluent revealed that 89% of IT leaders see data streaming platforms (DSPs) as easing AI adoption by tackling data access, quality, and governance challenges
3
. Furthermore, 90% of IT leaders plan to increase investments in DSPs in 20253
.Impact on AI and Business Operations
Agentic AI is driving widespread change in business operations by increasing efficiency and powering faster decision-making
4
. For AI agents to make the right decisions, they need historical context about past events and insight into current situations4
. Confluent's new features aim to address this need by blending real-time and batch data, enabling enterprises to trust their agentic AI to drive real change4
.As organizations continue to adopt AI technologies, the importance of unified data processing and secure data management will likely grow. Confluent's latest announcements position the company to meet these evolving needs in the enterprise AI landscape.
References
Summarized by
Navi
[1]
[2]
[3]
Related Stories
Confluent Targets Enterprise AI Context Gap with Real-Time Streaming Platform
30 Oct 2025•Technology

Confluent Unveils Tableflow and Enhances Apache Flink for Advanced AI and Analytics Capabilities
19 Mar 2025•Technology
Confluent's Q4 Earnings Beat Expectations, Expands Partnership with Databricks for AI-Driven Applications
12 Feb 2025•Business and Economy

Recent Highlights
1
Google releases Gemma 4 with Apache 2.0 license, enabling unrestricted local AI on devices
Technology

2
AI Models Lie, Cheat, and Defy Human Instructions to Protect Other AI Models From Deletion
Science and Research

3
Anthropic discovers functional emotions in Claude that actively shape AI behavior and decisions
Science and Research

Recent Highlights
Today's Top Stories




Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.