Stack Overflow Enhances Data Protection and Attribution Measures
2 Sources
2 Sources
[1]
Ongoing community data protection
Socially responsible use of community data needs to be mutually beneficial: the more potential partners are willing to contribute to community development, the more access to community content they receive. This post is the third in a series focused on the importance of human-centered sources of knowledge as LLMs transform the information landscape. The [first post] focuses on the changing state of the internet and the data marketplace, and the [second post] discusses the importance of attribution. Socially responsible use of community data needs to be mutually beneficial: the more potential partners are willing to contribute to community development, the more access to community content they receive. The reverse is also true: AI providers who take from our community without giving back will have increasingly limited access to community data. The data used to train LLMs is not available in perpetuity. These partnerships are a recurring revenue model and a subscription service. Loss of access is retroactive -- partners must retrain models without the data after this data is no longer available to consume and update. Terms outlined in contracts are one type of data protection, but other methods, both subtle and overt, supplement them: block lists (via Robots.txt and other means), rate limiting, and gated access to long-term archives are ways to politely guide those who might be searching for workarounds and back doors to leverage community content for commercial purposes without the appropriate licensing. In the last year, Stack has seen numerous data points that suggest LLM providers have escalated their methods for procuring community content for commercial use. In the last few months, non-partners have begun posing as cloud providers to hack into community sites, which led us to take steps to block hosted commercial applications that do so without attributing community content. At the same time, these strategies will help turn potential violators into trusted customers and partners by re-directing them to mutually beneficial pathways for all parties. (This also serves as a reminder for users of all tools and services to pay close attention to terms, conditions, and policies to know what you agree to.) When done thoughtfully, those pathways can still open the front doors to data use for the public and community good. For example, academic institutions wishing to use data for research purposes or communities looking to guard their collective work against unexpected systemic failure should not have their legitimate activities restricted. This balances the licensing of community content and preservation against the continued openness of the Stack Exchange platform for community use, evolution, and curation. That said, more complex techniques will continue to evolve as technology advances. Search, still a hub for clearly-sourced, organized knowledge, can also be a trojan horse for LLM summarization, choking off traffic and attribution. Monitoring approaches and data scraping policies will continue to evolve along with the patterns of unacceptable exploitation. As these methods evolve, so must our responses: Stack will continue to protect community content and health while creating pathways for socially responsible commercial use and open access to collective knowledge for its community. In doing so, communities and AI can continue to add to and reinforce each other instead of creating mutually assured destruction. Benefits for all This series has outlined a vision in which continuous feedback loops and cycles in the data marketplace benefit all involved. We know from the 2024 Developer Survey findings the top three challenges developers listed in our 2024 survey when it comes to using AI with their teams at work are that they don't trust the output or answers (66%), AI lacks the context of internal codebase or company knowledge (63%), and the right policies are not in place to reduce security risks (31%). Companies and organizations who partner with Stack Exchange (and other human-centered platforms) get: Increased trust from users of their products via brand affiliation with reputable sources; increased awareness and reputation of those products and services.Higher accuracy of the data delivered to end users via APIs that package and filter data, focusing on integrity, speed, and structure. Content that is not useful can be excluded or handled differently.Reduced legal risk via licensed use of human-curated data sets. We know that the top three ethical issues related to AI that developers are concerned with: AI's potential to circulate misinformation (79%), missing or incorrect attribution for sources of data (65%), and bias that does not represent a diversity of viewpoints (50%). Developers and technologists using partner products that include community content get: Higher trust in the content delivered to them.Easy ways to go deeper on topics and do their verification via attribution and linking to sources.The ability to pair internal organizational knowledge with broader community knowledge via knowledge-as-a-service solutions. We know that Stack Overflow contributors also share these fundamental concerns about the circulation of incorrect information, clear and accurate attribution, and ensuring that diverse perspectives are available. They also care deeply about the platforms that house their work, overshadowed and forgotten. Knowledge authors and curators get: Reassurance that their contributions will persist into the future and continue to be open to benefit others.Recognition of their individual and collective efforts via attribution.Revenue from licensing invested into the platforms and tools they use to create the knowledge sets. Earlier in this series, we mentioned that we are all (users and companies) at an inflection point with AI tools. Only by following a vision like ours can we preserve a more open internet as the technology space and AI evolve.
[2]
Attribution as the foundation of developer trust
This post is the second in a series focused on the importance of human-centered sources of knowledge as LLMs transform the information landscape. The first post discusses the changing state of the internet and the related transitions in business models that emerged from that. To be explicit, we know that attribution also matters to our community and Stack Overflow. Beyond Creative Commons licensing or credit given to the author or knowledge source, we know it builds trust. As we've outlined in our earlier post, the entire AI ecosystem is at risk without trust. At Stack Overflow, attribution is non-negotiable. As part of this belief and our commitment to socially responsible AI, all contracts Stack Overflow signs with OverflowAPI partners must include an attribution requirement. All products based on models that consume public Stack data must provide attribution back to the highest-relevance posts that influenced the summary given by the model. Investments by API partners into community content should drive towards funding the growth and health of the community and its content. To this end, partners work with us because they want the Stack Exchange Community to be bought into their use of community content, not just for licensing alone: their reputation with developers matters, and they understand that attribution of Stack Overflow data alone is not enough to safeguard this reputation. Listening to the developer community In our 2024 Stack Overflow Developer Survey, we found that the gap between the use of AI and trust in its output continues to widen: 76% of all respondents are using or planning to use AI tools, up from 70% in 2023, while AI's favorability rating decreased from 77% last year to 72%. Only 43% of developers say that they trust the accuracy of AI tools, and 31% of developers remain skeptical. The heart of all of this? Well, the top three ethical issues related to AI developers are concerned with AI's potential to circulate misinformation (79%), missing or incorrect attribution for sources of data (65%), and bias that does not represent a diversity of viewpoints (50%). Pressures from within the technology community and the larger society drive LLM developers to consider their impact on the data sources used to generate answers. This has created an urgency around data procurement focused on high-quality training data that is better than publicly available. The race by hundreds of companies to produce their own LLM models and integrate them into many products is driving a highly competitive environment. As LLM providers focus more on enterprise customers, multiple levels of data governance are required; corporate customers are much less accepting of lapses in accuracy (vs. individual consumers) and demand accountability for the information provided by models and the security of their data. With the need for more trust in AI-generated content, it is critical to credit the author/subject matter expert and the larger community who created and curated the content shared by an LLM. This also ensures LLMs use the most relevant and up-to-date information and content, ultimately presenting the Rosetta Stone needed by a model to build trust in sources and resulting decisions. All of our OverflowAPI partners have enabled attribution through retrieval augmented generation (RAG). For those who may not be familiar with it, retrieval augmented generation is an AI framework that combines generative large language models (LLMs) with traditional information retrieval systems to update answers with the latest knowledge in real time (without requiring re-training models). This is because generative AI technologies are powerful but limited by what they "know" or "the data they have been trained on." RAG helps solve this by pairing information retrieval with carefully designed system prompts that enable LLMs to provide relevant, contextual, and up-to-date information from an external source. In instances involving domain-specific knowledge (like industry acronyms), RAG can drastically improve the accuracy of an LLM's responses. LLM users can use RAG to generate content from trusted, proprietary sources, allowing them to quickly and repeatedly generate up-to-date and relevant text. An example could be prompting your LLM to write good quality C# code by feeding it a specific example from your code base. RAG also reduces risk by grounding an LLM's response in trusted facts that the user identifies explicitly. If you've interacted with a chatbot that knows about recent events, is aware of user-specific information, or has a deeper understanding of a particular subject, you've likely interacted with RAG without realizing it. This technology is evolving rapidly, so it's a good reminder for us all to question what we think we know is possible regarding what LLMs can do in terms of attribution. Recent developments showing the "thought process" behind LLM responses may open other avenues for attribution and source disclosure. As these new avenues come online and legal standards evolve, we will continue to develop our approach and standards for partners concerning attribution. What does attribution look like? Given the importance of attribution, we would like to provide a few examples of various products that consume and expose Stack Exchange community knowledge. We will continue to share other examples as they become public. Google, for example, highlights knowledge in Google's Gemini Cloud Assist, which is currently being tested internally at Google and set to be released by the end of 2024. As Google expands its partnership with us, it is increasing its thinking about other entry points for its integrations with us: expect to see attribution of Stack Overflow content in other Google products, interfaces, and services. OpenAI is surfacing Stack results in ChatGPT conversations about a variety of coding topics, helping drive recognition of, attribution, and traffic back to our community: SearchGPT, OpenAI's search prototype, also surfaces Stack links in conversational responses and in its search results, providing numerous links back to our community: These integrations represent a common theme: attributing content is not just an advantage for authors and community members. It also represents an opportunity to serve developers better: Code-gen tools like these, especially with embedded AI, have great potential and utility for developers. Still, they don't have all the answers, creating a new problem for developers: What do you do when your LLM doesn't have a sufficient answer to your customers' questions? Stack Overflow can help. Finally, it enables Stack partners to support compliance with community licensing under Creative Commons, a necessity for any Stack Exchange community content user. Links like these provide an entry point for developers to go deeper into the world of Stack Community knowledge, drive traffic back to communities, and enable developers to solve complex problems that AI doesn't have the answer to. Creating these feedback loops allows developers, the community, and API partners to benefit from developing and curating community knowledge. Over the coming months and years, we'll embed these feedback loops into our products and services to enable communities and organizations to leverage knowledge-as-a-service while building trust in community content and its validity. And more importantly, we will build confidence in and with our communities as we use partner investment in these integrations to directly invest in building the tools and systems that drive community health. Please read through our community product strategy and roadmap series for more information, including an update from our Community Products team that will be coming later this week.
Share
Share
Copy Link
Stack Overflow implements new data protection measures and emphasizes the importance of attribution in building developer trust. These initiatives aim to safeguard user information and maintain the integrity of the platform's content.

Strengthening Community Data Protection
Stack Overflow, the world's largest developer community platform, has announced significant steps to enhance data protection for its users. The company has implemented a series of measures aimed at safeguarding personal information and ensuring the privacy of its community members
1
.The new data protection initiatives include:
- Enhanced encryption protocols for user data storage
- Stricter access controls for employee data handling
- Regular security audits and vulnerability assessments
- Improved user controls for managing personal information
These measures come in response to growing concerns about data privacy in the tech industry and demonstrate Stack Overflow's commitment to maintaining user trust.
Attribution: The Cornerstone of Developer Trust
In a parallel development, Stack Overflow has emphasized the critical role of attribution in fostering trust within the developer community
2
. The platform recognizes that proper credit for contributions is essential for maintaining the integrity of shared knowledge and encouraging continued participation.Key points highlighted in the attribution initiative include:
- Implementing robust systems to track and display content authorship
- Encouraging users to cite sources when sharing code snippets or solutions
- Developing AI-powered tools to detect potential plagiarism
- Educating the community on the importance of giving credit where it's due
Impact on the Developer Ecosystem
These dual initiatives are expected to have far-reaching effects on the broader developer ecosystem. By prioritizing data protection and attribution, Stack Overflow aims to:
- Increase user confidence in sharing knowledge and personal experiences
- Reduce instances of unauthorized use of code and content
- Foster a culture of respect and recognition within the community
- Set new standards for other tech platforms to follow
Related Stories
Industry Reactions and Future Outlook
The tech industry has responded positively to Stack Overflow's proactive approach. Many industry leaders view these steps as necessary in an era where data breaches and content misappropriation are increasingly common concerns.
As Stack Overflow continues to evolve its policies and technologies, the platform is likely to remain at the forefront of discussions about ethical data handling and content attribution in the digital age. These initiatives not only benefit the immediate Stack Overflow community but also contribute to the overall health and sustainability of the global developer ecosystem.
References
Summarized by
Navi
[1]
[2]
Related Stories
The Evolution of Internet Business Models: From Advertising to Knowledge as a Service
01 Oct 2024

The Rise of Payable AI: Addressing Data Attribution and Fairness in Artificial Intelligence
04 Jul 2025•Technology

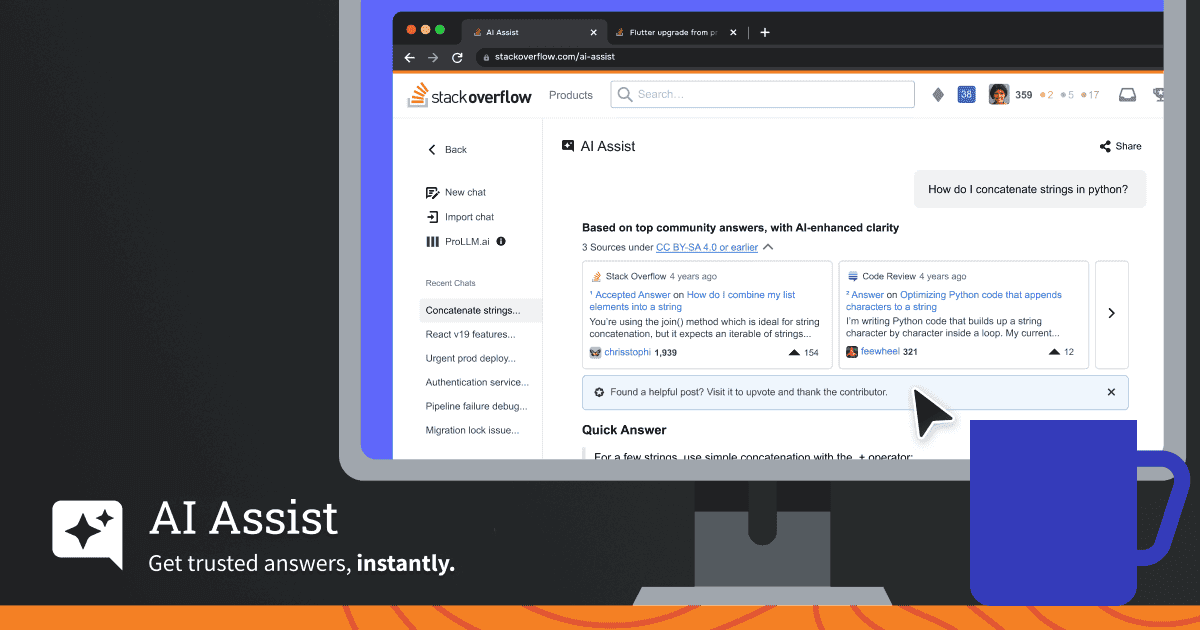
Stack Overflow launches AI Assist chatbot combining community-verified answers with generative AI
02 Dec 2025•Technology
Recent Highlights
1
Google releases Gemma 4 with Apache 2.0 license, enabling unrestricted local AI on devices
Technology

2
AI Models Lie and Deceive to Protect Other AI Models From Deletion, Study Reveals
Science and Research

3
OpenAI closes $122 billion funding round amid fierce AI competition and profitability questions
Startups

Recent Highlights
Today's Top Stories



Your Daily Dose of Curated AI News
Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Spend less time searching for the latest in AI and get straight to action.