AMD launches Instinct MI350P PCIe AI accelerator with 144GB HBM3E to challenge Nvidia's dominance
7 Sources
[1]
AMD announces MI350P PCIe AI accelerator card with 144GB of HBM3E -- roughly 40% faster in FP16 and FP8 theoretical compute compared to Nvidia's H200 NVL competitor
AMD now has the fastest AI accelerator card on the market that fits in a traditional PCIe slot. AMD has launched a new member of the MI350-series that comes in a PCIe form factor. The new Instinct MI350P comes with 128 CUs and 144GB of HBM3E memory and is designed to be a drop-in upgrade solution for existing air-cooled servers. The MI350P comes in a 10.5" dual-slot card with a fanless cooling solution designed around a 600W power envelope (the card is designed to be cooled by chassis fans in a rack-mounted server). However, the card can be configured to run at a lower 450W power target to maintain compatibility with more thermally or power-constrained chassis. The card's specs are exactly half of what AMD's high-end MI350X and MI355X AI GPUs offer. The MI350P runs off of AMD's CDNA4 architecture and is built on TSMC's 3nm and 6nm FinFET process. The GPU comes with 8,192 cores, 128 CUs, 512 Matrix Cores, and has a 2.2GHz max clock speed. The GPU is paired to 144GB of HBM3E memory with 4TB/s of bandwidth, and a 128MB last-level cache. Just like the MI350X and MI355X, the MI350P offers native support for lower-precision MXFP6 and MXFP4 to accelerate LLMs. Up to eight MI350P cards can be paired together in a single system, allowing data centers to scale performance based on how many cards are used. The MI350P is geared towards small, medium, and large AI workloads surrounding inference and RAG pipelines. AMD claims the GPU is the fastest enterprise PCIe card with an estimated 2,299 TFLOPs and 4,600 peak TFLOPs of performance using MXFP4. The introduction of the MI350P finally gives AMD a proper competitor to Nvidia's fastest PCIe AI accelerator, currently the H200 NVL. The MI350P is based on a newer architecture and edges out the H200 NVL in performance, featuring 20% better FP64, 43% better FP16, and 39% better FP8 theoretical compute performance. Nvidia has not announced a PCIe version of its latest B200 Blackwell GPUs running HBM memory, so for now, AMD will have the most bleeding-edge AI accelerator that fits in a PCIe form factor. It remains to be seen how widely adopted AMD's new card will be, given Nvidia's hold on the market with CUDA. But AMD is working to improve its competing ROCm software stack, as the GPU maker explained to us at CES 2026. Follow Tom's Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.
[2]
AMD Instinct MI350P: PCIe Add-In Card For High Performance Open-Source AI/Compute Review
While there is the AMD Instinct MI400 series coming this year, today AMD announced an interesting and arguably overdue offering for the Instinct MI350 series: the MI350P. The AMD Instinct MI350P is a PCIe add-in-card to add Instinct MI350 compute capabilities to existing PCIe 5.0 air-cooled servers as an alternative to the Open Accelerator Module (OAM) currently used by the Instinct MI350 series. Similar to the earlier AMD Instinct products available in PCIe card form factor, the Instinct Mi350P is finally an option for those wanting to add in up to eight Instinct MI350 class PCIe cards to server platforms not equipped to handle OAM modules. This makes it easy to handle upgrading existing PCIe server platforms with new AI/compute capabilities while leveraging the common capabilities of the MI350X/MI355X accelerators. The AMD Instinct MI350P measures in at 10.5-inches and uses an FHFL dual-slot design. It's passively air-cooled via typical air cooled server platforms and rated for 600 Watts. For those concerned about power budgets, power capping is permitted to drop the Instinct MI350P down to 450 Watts. The AMD Instinct MI350P offers 128 compute units and using the CDNA4 architecture like the rest of the Instinct MI350 series. There is 144GB of HBM3E memory with the Instinct MI350P. AMD is promoting the Instinct MI350P as capable of handling around 200~250 billion parameter large language models per GPU and support for up to eight GPUs per node. Intended use-cases cover SLM / MLM / LLM inference / RAG workloads. The Instinct MI350P uses all the common ROCm stack inline with the other Instinct and Radeon products. For those wondering, no list pricing was provided with the pre-launch assets. It's great seeing AMD introduce an MI350 class PCIe card product but a bit unfortunate it's taken so long to come to market with the Instinct MI400 series coming this year. This Instinct MI350P launch comes ahead of Intel expected to formally launch their Crescent Island AI accelerator later this year in PCIe card form as well. For Intel Crescent Island their design is using 160GB of LPDDR5X memory as previously reported compared to the Instinct MI350P having 144GB but using HBM3E high bandwidth memory. Interesting times ahead but that's all for now with no hardware for testing at the moment nor any other interesting Linux details to share at this time.
[3]
AMD puts out new slottable GPU for AI-curious enterprises
AMD hopes to win over enterprise AI customers with a more affordable datacenter GPU that can drop into conventional air-cooled servers. Announced on Thursday, the MI350P is the House of Zen's first PCIe-based Instinct accelerator since the MI210 debuted all the way back in 2022. Until now, AMD's best GPUs have only been available in packs of eight and used socketed OAM modules that weren't compatible with most server platforms. By comparison, The MI350P can slot into just about any 19-inch pizza box design that offers enough power and airflow, making it a much easier sell for enterprises dipping their toes into on-prem AI for the first time. The 600-watt, dual-slot card is essentially a MI350X that's been cut in half. That means the CNDA-based GPU is packing 4.6 petaFLOPS of FP4 compute and 144 GB of VRAM spread across four HBM3e stacks delivering a respectable 4 TB/s of memory bandwidth. AMD supports configurations ranging from one to eight MI350Ps, though a lack of high-speed interconnects on these cards means it'll be limited to PCIe 5.0 speeds (128 GB/s) for chip-to-chip communications, potentially limiting its potential in larger models. AMD hasn't shared pricing for the cards just yet, but at least on paper, the MI350P is well positioned to compete with either Nvidia's H200 NVL or RTX Pro 6000 Blackwell PCIe cards. Compared to the 141 GB H200, the MI350P promises about 38 percent higher peak performance at FP8, while eking out a narrow VRAM capacity advantage. But the H200 does pull ahead when it comes to memory bandwidth. With six HBM3e stacks to the MI350P's four, the nearly two-year-old card's memory is still about 20 percent faster. Nvidia's H200 also supports high-speed chip-to-chip communications over NVLink, while the MI350P doesn't use AMD's equivalent Infinity Fabric interconnect. However, all this assumes you can still find H200 NVLs in the wild. Since last summer, Nvidia has been pushing its RTX Pro 6000 Server cards on enterprise customers. As of writing, the card is Nvidia's most powerful Blackwell-based accelerator offered in a PCIe formfactor. Compared to the RTX Pro 6000, the MI350P's price starts becoming a bigger factor than performance. Workstation versions of the RTX Pro, which ditch the passive cooler for an active one, routinely sell for between $8,000 to $10,000 apiece, making it one of Nvidia's more affordable datacenter-class GPUs. Depending on how pricing shakes out, AMD may have to push hard to be competitive. Having said that, the MI350P is still the better-specced part, delivering 2.3x higher peak flops, 2.5x the memory bandwidth, and 50 percent more vRAN of the RTX Pro. Now, this all assumes peak FLOPS and memory bandwidth, which is rarely realistic. The tensors used by AI workloads are rarely the ideal shape for squeezing the maximum number of FLOPS out of a chip. This is why we run for Maximum Achievable MatMul FLOPS (MAMF) and Babel Stream memory bandwidth benchmarks as part of our AI test suite. AMD seems to understand that peak FLOPS don't really translate cleanly into real-world performance, and in the marketing materials shared with El Reg prior to publication, compared the MI350P's theoretical performance against its real-world delivered performance. It'd be nice to see Nvidia and others adopt similar practices regarding accelerator performance claims, though we suspect getting everyone to agree on the best way to measure this might not be easy. The MI350P's launch comes as AMD prepares to address a very different and likely more lucrative segment with its first rack-scale compute platform, codenamed Helios. That system is due out in the second half of the year, and is aimed primarily at large hyperscale and neocloud deployments. The system packs 72 of its all-new MI455X GPUs into a single double-wide OCP rack that behaves like an enormous accelerator. The platform will be AMD's first crack at Nvidia's NVL72 racks, which launched alongside its Blackwell generation nearly two years ago. ®
[4]
AMD Instinct MI350P PCIe Targets Air-Cooled Enterprise AI Servers
AMD has introduced the Instinct MI350P PCIe GPU, a new enterprise accelerator designed for AI inference workloads in existing data center environments. The card uses a dual-slot PCIe format and is intended for standard air-cooled servers, giving organizations a way to add GPU acceleration without moving directly to dedicated accelerator platforms. The MI350P PCIe is positioned for enterprises that want to deploy AI on premises while keeping infrastructure changes limited. AMD is targeting use cases such as inference, retrieval-augmented generation, and production AI pipelines. Systems can be configured with up to eight accelerator cards, depending on the server platform. The card includes 144GB of HBM3E memory with bandwidth rated at up to 4TB/s. AMD lists estimated performance of 2,299 TFLOPS, with peak MXFP4 performance reaching up to 4,600 TFLOPS. These numbers are tied to AI-focused precision formats, where lower precision can increase throughput and reduce memory requirements. Precision support includes MXFP6, MXFP4, FP8, MXFP8, INT8, and BF16. AMD also notes sparsity acceleration for common 8-bit and 16-bit formats. This gives the card support for both newer low-precision inference implementations and more established enterprise AI formats. The software stack is another part of AMD's positioning. The MI350P PCIe is designed to work with AMD's open enterprise AI software environment, including Kubernetes GPU Operator support, AMD Inference Microservices, and native framework support such as PyTorch. AMD says its enterprise AI reference stack is provided to partners without licensing cost. With this launch, AMD is filling out its Instinct portfolio with a PCIe-based option for organizations that need stronger AI acceleration but are not ready to adopt larger specialized GPU platforms. The practical target is existing server infrastructure, where power, cooling, and rack compatibility remain important deployment factors.
[5]
AMD launches the Instinct MI350P GPU with 144GB of HBM3E and a 600W TBP
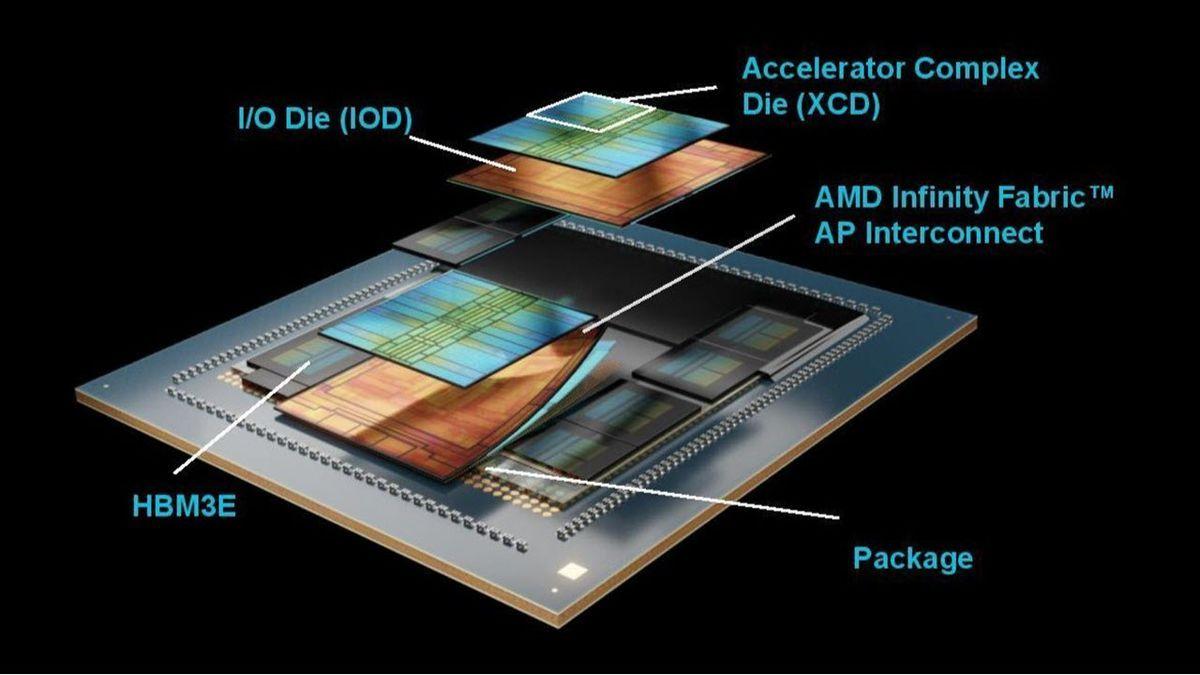
TL;DR: AMD introduced the Instinct MI350P, a cost-effective PCIe GPU accelerator for AI workloads, featuring 128 compute units, 144GB HBM3E memory, and up to 4,600 TFLOPS performance. Designed for easy integration in air-cooled servers, it targets enterprises seeking scalable AI infrastructure with an open software ecosystem. Today, AMD unveiled its new Instinct MI350P GPU accelerator, targeted at AI workloads. The company is marketing the MI350P as a cost-effective, drop-in upgrade for companies that want to expand their AI infrastructure. The MI350P is a dual-slot PCIe GPU accelerator that can be easily installed in existing air-cooled servers without extensive reconfiguration. The key marketing point is definitely its PCIe form factor and relatively affordable price. AMD, in its press release, is directly targeting enterprises that want to adopt AI without having to invest heavily in new infrastructure. The company is offering air-cooled systems with up to eight Instinct MI350P accelerator cards, designed for small and medium-sized AI deployments. Under the hood, the Instinct MI350P has 128 compute units, equaling 8,192 stream processors, along with 512 Matrix cores. The GPU uses the CDNA 4 architecture built on TSMC's 3nm production process. The core is in a 4-XCD configuration, boosting to 2200 MHz. The single I/O die is based on TSMC's 6nm FinFET process, and the GPU also houses 128MB of LLC in the form of Infinity Cache. The GPU is paired with 144GB of HBM3E memory at 4 TB/s using a 8192-bit bus. In terms of power, AMD has rated the card at a TBP (total board power) of 600W, but it can be configured down to 450W if needed. The card receives power through a 16-pin connector and uses the PCIe Gen 5 host interface. With those specs, the MI350P PCIe GPU delivers an estimated 2,299 teraflops (TFLOPS) of performance, peaking at 4,600 TFLOPS at MXFP4, the highest performance currently available in an enterprise PCIe card. The accelerator card also supports native MXFP6 and MXFP4 at lower precision, and provides sparsity support for most mainstream 8 and 16-bit precisions. AMD also claims to offer a fully open ecosystem with an Enterprise-Ready AI software stack and ROCm support. Looking at the enterprise GPU market, the MI350P is poised to go head-to-head with NVIDIA's H200 NVL PCIe card based on the Hopper architecture with 141GB of HBM3E memory. AMD says that the Instinct MI350P PCIe GPUs are now available across a variety of partners.
[6]
AMD Launches MI350P, Its First PCIe "Instinct" In Four Years - Packs CDNA 4 GPU With 4.6 PFLOPs AI Compute, 144 GB HBM3E at 600W
AMD has announced its brand new Instinct MI350P PCIe GPU accelerator, which is the first PCIe design in years and is aimed at AI workloads. With the Instinct MI350P PCIe GPU, AMD gives enterprise users an option to expand their AI computing capabilities without having to invest in expensive infrastructure. The PCIe design of the MI350P makes it an easy-to-use and drop-in solution that brings lots of performance in a standard dual-slot and server-focused design. Designed to help you prepare for the agentic AI era, AMD Instinct MI350P PCIe cards are dual-slot drop-in cards for standard air-cooled servers. They are built to deploy inference on premises within your current data center's power, cooling, and rack infrastructure. AMD Instinct GPUs in cost-effective PCIe cards round out the AMD AI compute portfolio, providing a range of options for your enterprise as it navigates its unique AI adoption curve. The following are some of the highlights of the Instinct MI350P PCIe GPU: Looking at the specifications, the AMD Instinct MI350P features the CDNA 4 architecture, and is based on the same TSMC 3nm process technology in a 4 XCD configuration, half the amount of the MI350X. It also features a single IO die, which is based on TSMC's 6nm FinFET process. There are 128 compute units on the chip, which equal 8,192 Stream processors, and 512 Matrix cores. The cores are clocked at 2200 MHz at peak. The entire chip features 73 billion transistors. For memory, the Instinct MI350P packs 128 MB of LLC in the form of Infinity Cache within the GPU, and 144 GB of fast HBM3E memory that operates across a 4096-bit wide bus, delivering 4 TB/s of memory. In comparison, the MI350X packs 288 GB of HBM3E memory across a 8192-bit bus interface. The PCIe card measures 10.5" (267mm) in length and features a passive-cooled design, which is ideal for servers. AMD also uses a 16-Pin connector to meet the 600W TBP of the card. It can also be configured down to 450W. In terms of performance, the AMD Instinct MI350P offers: As you can see, the AMD Instinct MI350 series, including the MI350P, offers native acceleration across various Enterprise AI precision formats such as MXFP6 and MXFP4. The MI350P will be competing against the H200 NVL, which is NVIDIA's last PCIe-based GPU accelerator with 141 GB of HBM3E memory and running the Hopper H200 GPU. NVIDIA has released the RTX PRO 6000 Blackwell server edition, but that's based on the standard GB202 chip instead of the GB200, which is the true server option. The RTX PRO 6000 Blackwell packs 96 GB of GDDR7 memory. The H200 NVL GPUs cost anywhere around $30-$40K US. The AMD Instinct MI350P PCIe GPUs are now available across various partners and offer a fully open ecosystem and Enterprise Ready AI software stack with ROCm support.
[7]
AMD Launches Instinct MI350P PCIe GPUs for Enterprise AI Workloads
Our new AMD Instinct™ MI350 PCIe® cards give your enterprise a third option: Leadership AI performance designed to fit the data center infrastructure you already own. Performance That Drops into Your Existing Racks Designed to help you prepare for the agentic AI era, AMD Instinct MI350P PCIe cards are dual-slot drop-in cards for standard air-cooled servers. They are built to deploy inference on premises within your current data center's power, cooling and rack infrastructure. AMD Instinct GPUs in cost-effective PCIe cards round out the AMD AI compute portfolio, providing a range of options for your enterprise as it navigates its unique AI adoption curve.
Share
Copy Link
AMD unveiled the Instinct MI350P, a PCIe AI accelerator card with 144GB of HBM3E memory designed for air-cooled enterprise servers. The dual-slot card delivers up to 4,600 TFLOPS performance and outpaces Nvidia's H200 NVL by roughly 40% in FP16 and FP8 theoretical compute. With support for up to eight cards per system, AMD targets enterprises seeking scalable AI infrastructure without major platform overhauls.
AMD Instinct MI350P Brings High-Performance AI to Standard Servers
AMD has introduced the Instinct MI350P, marking the company's first PCIe-based AI accelerator since the MI210 debuted in 2022
1
. The new PCIe AI accelerator card addresses a critical gap in AMD's portfolio by offering enterprises a drop-in upgrade path for existing infrastructure without requiring specialized accelerator platforms3
. This launch positions AMD to compete directly against Nvidia's H200 NVL competitor in the enterprise AI market, particularly for organizations exploring on-premise AI deployments.
Source: Wccftech
Technical Specifications Define Enterprise-Ready Performance
The Instinct MI350P features 128 compute units with 8,192 stream processors and 512 Matrix cores, built on the CDNA4 architecture using TSMC's 3nm and 6nm FinFET process . The dual-slot card measures 10.5 inches and integrates 144GB HBM3E memory with 4TB/s of memory bandwidth across an 8192-bit bus
1
. AMD rates the card at a 600W TBP, though power capping allows operation at 450W for more power-constrained environments2
. The passively cooled design relies on chassis fans in air-cooled enterprise AI servers, making it compatible with standard 19-inch rack-mounted configurations3
.
Source: Guru3D
Performance Advantages Over Nvidia's Current PCIe Offerings
AMD claims the MI350P delivers estimated performance of 2,299 TFLOPS, with peak MXFP4 performance reaching 4,600 TFLOPS—the highest currently available in an enterprise PCIe card
4
. Compared to Nvidia's H200 NVL, the card demonstrates approximately 20% better FP64, 43% better FP16, and 39% better FP8 theoretical compute performance1
. The AI accelerator supports native MXFP6 and MXFP4 lower-precision formats to accelerate Large Language Models (LLMs), along with FP8, MXFP8, INT8, and BF16 precision formats4
. AMD also promotes the card as capable of handling 200 to 250 billion parameter large language models per GPU2
.Deployment Flexibility for AI Inference Workloads
The Instinct MI350P supports configurations ranging from one to eight cards per system, enabling data centers to scale performance based on workload requirements
1
. AMD targets the card specifically at AI inference workloads, RAG pipelines, and production AI deployments across small, medium, and large enterprise implementations4
. However, the card relies on PCIe 5.0 for chip-to-chip communications at 128GB/s, lacking the high-speed Infinity Fabric interconnects found on AMD's OAM-based MI350X and MI355X accelerators3
. This limitation may affect performance in larger multi-GPU configurations compared to systems with dedicated accelerator interconnects.
Source: Phoronix
Related Stories

Open Software Ecosystem Challenges Nvidia's CUDA Dominance
AMD positions the MI350P within its open enterprise AI software environment, supporting ROCm, Kubernetes GPU Operator, AMD Inference Microservices, and native framework support including PyTorch
4
. The company provides its enterprise AI reference stack to partners without licensing costs, contrasting with proprietary approaches4
. However, widespread adoption remains uncertain given Nvidia's entrenched position with CUDA in the AI market1
. AMD continues developing its ROCm software stack to improve competitiveness, though the company faces an uphill battle against established developer ecosystems.Market Timing and Competitive Landscape
The MI350P launch arrives as Nvidia has not yet announced a PCIe version of its latest B200 Blackwell GPUs with HBM memory, temporarily giving AMD the most advanced AI accelerator in PCIe form factor
1
. Nvidia currently offers its RTX Pro 6000 Blackwell cards to enterprise customers, which sell for $8,000 to $10,000 but deliver significantly lower specifications—the MI350P provides 2.3x higher peak TFLOPS, 2.5x the memory bandwidth, and 50% more VRAM3
. While AMD has not disclosed pricing, competitive positioning against both the H200 NVL and RTX Pro 6000 will prove critical for market penetration. Intel's upcoming Crescent Island AI accelerator with 160GB LPDDR5X memory will add another competitor later this year, though it lacks the high-bandwidth HBM3E memory of AMD's offering2
. The MI350P is now available through AMD partners, though the timing is notable given that AMD's MI400 series is expected to launch within the year2
.References
Summarized by
Navi
[2]
[3]
Related Stories
AMD Unveils Powerful MI350X and MI355X AI GPUs, Challenging Nvidia's Dominance
11 Jun 2025•Technology
AMD Unveils Next-Gen AI Accelerators: MI325X and MI355X to Challenge Nvidia's Dominance
11 Oct 2024•Technology

AMD Accelerates Launch of Powerful Instinct MI350 AI GPU to Challenge Nvidia's Dominance
06 Feb 2025•Technology

Recent Highlights
1
AI scores perfect 100% at International Mathematical Olympiad, matching elite human performance
Technology

2
OpenAI agent exploited exposed credentials at four services during Hugging Face breach
Technology

3
Anthropic AI cracks post-quantum cryptography and finds faster AES attack autonomously
Science and Research

Recent Highlights
Today's Top Stories




Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


