Google DeepMind releases DiffusionGemma AI model with 4x speed boost using image generation techniques
12 Sources
[1]
Google's latest DiffusionGemma open AI model comes with a 4x speed boost
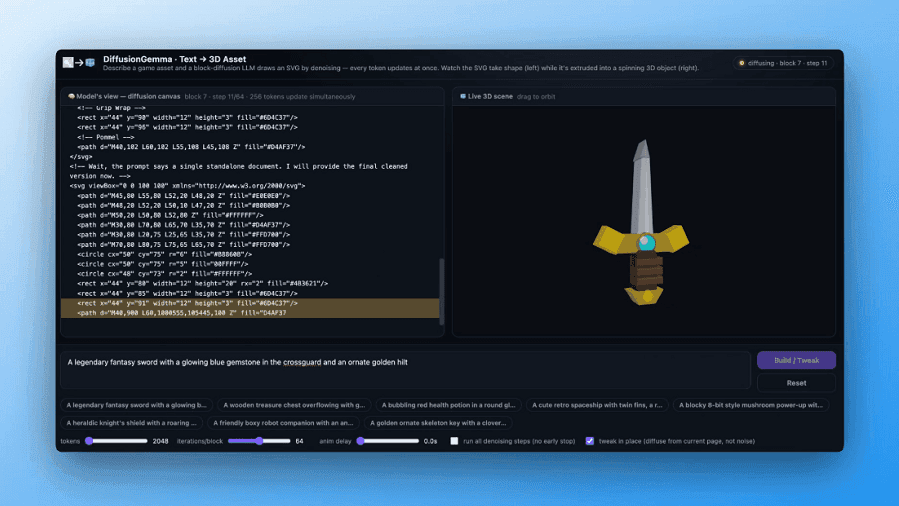
Another day, another AI model from Google. This time, Google DeepMind has released a new member of the Gemma 4 open model family, but it's fundamentally different from the rest of the lineup. DiffusionGemma doesn't generate outputs linearly like most AI models. Instead, it can produce an entire block of text in parallel. Google says this makes it faster and more efficient when running on local hardware like an Nvidia DGX or a humble gaming GPU. Most AI models are designed to be autoregressive -- they generate text left to right one token at a time. DiffusionGemma has more in common with image generation models, which start with static and then denoise it to create the desired content. This model takes a field of placeholder tokens running over the canvas multiple times to generate likely tokens and using those to improve estimation of others. At the end of the process, the model finalizes its token outputs in one large block -- the "denoised" text canvas. DiffusionGemma is fairly large in the realm of Google's open models. It's a Mixture of Experts (MoE) model with a total of 26 billion parameters, but only 3.8 billion are activated during inference. That means it should fit in the 18GB ram allotment of a high-end GPU. In testing with an RTX 5090, DiffusionGemma spits out around 700 tokens per second. With a single Nvidia H100 AI accelerator, DiffusionGemma can produce 1,000+ tokens per second. That's about four times the output of the similarly sized autoregressive Gemma models. This approach to text generation shifts the bottleneck from memory bandwidth to compute, generating up to 256 tokens in parallel. Google says this offers a measurable boost in non-linear tasks like in-line editing, molecular sequencing, and mathematical graphing. The animation above shows how DiffusionGemma was tuned to solve Sudoku puzzles, which is a notoriously challenging task for standard autoregressive AI models because each token depends on future tokens. DiffusionGemma's ability to continuously self-correct large sets of tokens makes that easier. Multiple paths to local efficiency If diffusion is so much faster, why isn't Google using it in big cloud-based Gemini models? Google has experimented with this, but there are a few drawbacks to text diffusion, including a higher error rate. In image diffusion models, a single badly predicted pixel doesn't make the image useless, but language is discreet. An equivalent error in text can make a block of tokens meaningless and force you to start over to get a better output. Diffusion models also waste resources when the desired output is only a few tokens long. They have to do a lot more parallel work to whittle down to a few tokens that an autoregressive model does from beginning to end in just five steps. The efficiency gain for local processing makes this an appealing avenue of experimentation, though. In the cloud, autoregressive models can batch large numbers of compute jobs from multiple users so they're always churning out tokens, and the high bandwidth memory (HBM) used in these systems can move data around much more efficiently. Conversely, local AI encounters wasted compute cycles due to lower memory bandwidth and idle time. Diffusion models can make more efficient use of available compute, but this isn't the only way. Google also recently began implementing Multi-Token Prediction (MTP) drafters, which use otherwise wasted compute cycles to predict possible tokens to increase speed. But diffusion is even faster than the MTP versions of Gemma. Google stresses that DiffusionGemma is experimental, but it's available under the same Apache 2.0 license as all the other fourth-generation Gemma models. You can download the model weights today from Hugging Face. Google says it worked with Nvidia to ensure DiffusionGemma was optimized for a variety of setups, including high-end RTX GPUs (quantized) and enterprise systems like the H100 or DGX Spark platform.
[2]
Google's new open-weights AI model uses image-generation methods to output text faster
The boffins on Google's DeepMind team unveiled an experimental new language model this week that uses techniques originally developed for AI image generators to boost text output performance by as much as 4x when running on resource-constrained consumer hardware. It's free to download and you can run it with just 18 GB of DRAM or VRAM. The model, codenamed DiffusionGemma, is the latest addition to Google's open weights model family. But unlike Gemma 4, which launched this spring, the 26 billion-parameter mixture of experts (MoE) model isn't a large language model in a conventional sense. Instead, it's actually closer to image models like Stable Diffusion or Flux. Rather than generating tokens one after another in an autoregressive fashion, DiffusionGemma generates entire paragraphs' worth of tokens at the same time. The process looks a lot like how a diffusion model turns what's essentially static into an image through a series of denoising steps. As Google explains it, DiffusionGemma works by laying out a canvas of random tokens, and then refining them until the final output is reached. Compared to conventional LLMs, which are memory-bandwidth bound and require a lot of VRAM, diffusion models are a predominantly compute-bound workload, which is why the Chocolate Factory is positioning these models for local deployment. LLMs are autoregressive. During token generation, the model's active parameters need to be streamed from memory for every token generated, making memory bandwidth a major bottleneck. In the cloud, inference providers balance compute and memory bandwidth by processing hundreds or thousands of requests in parallel. As you might have guessed, this isn't something the average user running a local model on their notebook can do. However, many consumer products, like high-end graphics cards, have plenty of excess horsepower, which DiffusionGemma can take advantage of to boost output performance. Diffusion language models aren't perfect. Google isn't the first to explore this tech. Previous models, like DREAM or Mercury 2, demonstrated major speedups over conventional LLMs, but generally underperformed them in benchmarks for their size. DiffusionGemma doesn't appear to be any different. According to Google, the 26 billion-parameter model falls just behind Gemma 4 12B in the GPQA-Diamond benchmark, with its main advantage being output speed, and even then it's not as impressive as Google has made it out to be. The chart shows a roughly 2.25x speedup for DiffusionGemma over the 12B parameter LLM with speculative decode enabled. Compared to Gemma 4 26B-A4B, the speedup is nearly 4x when running a single Nvidia H100. DiffusionGemma is being released as an experimental model rather than an enterprise focused one, like we saw with Gemma 4. The model is available for download on popular model repos like Hugging Face under a highly permissive Apache 2.0 license with support already merged into popular inference engines like vLLM, MLX, and HF Transformers, with support for Llama.cpp coming soon. While local inference has largely been the domain of AI enthusiasts, companies like Google are increasingly leaning on the tech to cut cloud costs associated with their AI services. As you may recall, back in May, Google quietly began shipping a small LLM with its Chrome web browser. ®
[3]
Google unveils DiffusionGemma, an AI model that breaks free of left-to-right processing
Rather than generating text word by word, Google's experimental open-source model drafts entire passages simultaneously using diffusion, resulting in up to 4x faster inference. Extremely powerful large language models (LLMs) still operate as though they're typing on a keyboard, processing workloads in a simple left-to-right fashion. But in locally-run, single-user scenarios, this sequential processing can leave graphics processing units (GPUs) and tensor processing units (TPUs) underutilized. Google is betting that DiffusionGemma can get around this bottleneck. The new experimental open model generates text "exceptionally fast," creating entire blocks of text simultaneously through diffusion techniques rather than through token-by-token processing. The company says this technique results in 4x faster inference compared to auto-regressive models that rely on sequential processing.
[4]
DiffusionGemma is Google's fastest AI yet, but it comes with a big trade-off
Output quality is still inferior to Gemma 4, so it's more of an experimental tool than a finished product. Google has released DiffusionGemma, an experimental AI model that takes a very different approach to how most chatbots generate text today. Instead of writing one word after another in a strict sequence, it generates a whole block of text at once and then keeps refining it until it becomes readable. The idea is to push for speed and hardware efficiency, even if it means giving up some polish in the final output. This new AI model is open-sourced under the Apache 2.0 license and is aimed at developers and researchers rather than everyday users. To understand why this matters, it helps to look at how most large language models work. Systems like Google's Gemma 4 generate text step by step, one token at a time. Each new word depends on what came before it, which makes the process inherently sequential and harder to speed up. DiffusionGemma, on the other hand, starts with a full canvas of random tokens, essentially noisy, unreadable text, and then repeatedly cleans it up in multiple passes. With each pass, the output becomes more structured and coherent until it settles into a final response. A simple way to picture it is that traditional models write, while DiffusionGemma drafts and edits everything at once. That shift has a direct impact on performance. Per Google's claims, DiffusionGemma can be up to four times faster than standard autoregressive models in low-concurrency scenarios, where a single user or process uses the GPU. On high-end hardware, the numbers are even more aggressive. The company asserts more than 1,000 tokens per second on an NVIDIA H100 and over 700 tokens per second on an RTX 5090. Under the hood, DiffusionGemma is a 26-billion-parameter Mixture-of-Experts model, but it does not activate all of that at once. Only about 3.8 billion parameters are used during inference, helping keep compute requirements manageable. Google says this makes it possible to run the model on high-end consumer GPUs when quantized, with a memory footprint of around 18GB VRAM. Where things get more interesting is how the model actually generates text. It can produce up to 256 tokens in parallel in a single step, and each token can attend to every other token in the block. That gives the model a global view of the output instead of a strictly linear one. This makes it better suited for structured or rule-based tasks. For example, it can help fill in missing sections of code, complete structured formats like JSON, work through logic-heavy problems such as Sudoku-style puzzles, or handle mathematical patterns where consistency across the whole output matters more than sentence-by-sentence flow. Because it sees the entire block at once, it can also correct contradictions within the same generation cycle, rather than waiting for a later token to fix them. But there is a catch, and Google is upfront about it. DiffusionGemma does not match the output quality of its standard Gemma 4 models. The writing can be less stable, less refined, and not as reliable for complex or nuanced responses. So, you get speed but lose some polish. That is why Google is positioning it as an experimental tool -- it is designed for scenarios where responsiveness matters more than perfection, such as real-time AI tools, inline writing or coding assistants, and fast iterative workflows where users care more about instant feedback than final-quality text. Hence, DiffusionGemma is not meant to replace existing Gemini or Gemma models. It is a speed-first experiment that trades output quality for efficiency and responsiveness. But it also hints at a different direction for AI text generation, where models do not just predict the next word, but generate and refine entire blocks of text simultaneously.
[5]
NVIDIA Accelerates Google DeepMind's DiffusionGemma for Local AI
The new Diffusion Gemma open model generates text in parallel -- not one token at a time -- and is optimized to run on the NVIDIA RTX PRO platform, NVIDIA DGX Spark systems and GeForce RTX GPUs. Today, Google DeepMind released DiffusionGemma -- an experimental open model built for exceptionally fast text generation. NVIDIA has optimized DiffusionGemma to run even faster across NVIDIA GeForce RTX GPUs, the NVIDIA RTX PRO platform and NVIDIA DGX Spark systems, from local PCs to the cloud. Rather than generating text one word at a time, DiffusionGemma generates multiple words in parallel to output whole blocks of text, opening a new, low-latency frontier for the kind of single-user workloads that developers, researchers and AI enthusiasts run every day. Features of the new model include: * Parallel generation: DiffusionGemma denoises up to 256 tokens per step instead of predicting one at a time. * Built on Gemma 4: DiffusionGemma is built on Gemma 4, a 26-billion-parameter mixture-of-experts model that activates just 3.8 billion parameters per step, pairing a diffusion head with Google's Gemma 4 architecture. * Up to 4x faster performance: The boost means fast text generation, where single-user generation usually stalls -- at batch size 1, on local hardware. * Open and local: DiffusionGemma is open weights under a permissive Apache 2.0 license and runs entirely on RTX and DGX Spark -- no cloud, no per-token cost -- with day-zero support in Hugging Face Transformers, vLLM and Unsloth. A Different Way to Generate Text Almost every large language model (LLM) in wide use today is autoregressive -- meaning it generates text one token at a time, with each new word depending on the one before it. That sequential process is what makes interactive AI feel like it's typing. DiffusionGemma takes a different path. Built on the Gemma 4 26B mixture-of-experts architecture, it generates text the way diffusion models generate images: by starting from noise and refining a whole block of text at once. Each step denoises up to 256 tokens in parallel rather than emitting a single token and waiting to compute the next. The result is a model that thinks in blocks instead of sequentially. For latency-sensitive, single-user work -- such as interactive chat, agentic loops or on-device assistants that plan and act -- that parallelism translates into responses fast enough to keep pace with how developers think and iterate. DiffusionGemma Flies on NVIDIA GPUs Generating one token at a time is fundamentally a memory-bound problem -- at batch size 1, a traditional LLM spends most of its time waiting on memory bandwidth, not doing math, which leaves a lot of compute on the table. Diffusion flips the equation. Pulling a full 256-token block through the transformer in parallel is a compute-bound workload -- exactly what NVIDIA GPUs are built for. NVIDIA Tensor Cores accelerate the dense parallel math, and the CUDA software stack lets the model run efficiently from day one without bespoke tuning. In short, the model's design plays directly to the GPU''s strengths. That shows up in the numbers. DiffusionGemma delivers 1,000 tokens/sec at batch size 1 on a single NVIDIA H100 Tensor Core GPU, 150 tokens/sec on NVIDIA DGX Spark and fastest local inference on NVIDIA DGX Station -- roughly 4x faster than an equivalent autoregressive model running in the same single-user regime. That advantage holds across NVIDIA's full lineup, running: * Locally on the NVIDIA DGX Spark deskside personal AI supercomputer -- powered by the NVIDIA GB10 Grace Blackwell Superchip with 128GB of unified memory -- with the preinstalled NVIDIA AI software stack ready for prototyping, fine-tuning and fully local agent workflows. * On NVIDIA RTX PRO 6000 workstations, providing developers, researchers and AI professionals with the headroom to run local low-latency generation and agentic loops as part of a professional workflow. * On DGX Station, delivering best-in-class, high-speed inference at up to 800 tokens/sec for low-latency text generation and agentic loops with 748GB of coherent memory. * On GeForce RTX GPUs, with llama.cpp support coming soon. Get Started Locally The fastest way to start testing and prototyping the model is through Hugging Face Transformers, which runs DiffusionGemma on a GeForce RTX 5090 or DGX Spark out of the box. For higher-throughput inference, vLLM provides day-zero serving support. For adapting the model to a specific task or domain, fine-tuning is available through Unsloth and NVIDIA NeMo framework, with ready-made DGX Spark playbooks to get a local environment running quickly. Check out the vLLM playbooks for DGX Spark , RTX PRO and DGX Station. Try Diffusion Gemma on Hugging Face or test it for free using NVIDIA-hosted application programming interfaces at build.nvidia.com. Go deeper on the architecture and local deployment by reading the NVIDIA technical blog and the Google DeepMind announcement. #ICYMI: The Latest From RTX AI Garage 🎬 NVIDIA researchers released SANA-WM, an open source world model that turns a single image and a camera path into a minute-long, 720p video with precise 6-DoF control. At just 2.6 billion parameters, its distilled version generates a full 60-second clip in 34 seconds on a single NVIDIA GeForce RTX 5090 GPU using the NVFP4 format -- delivering up to 36x higher throughput than comparable open models while running on one GPU. Read the paper. 🛠️ Building Windows agents just got a full toolset -- NVIDIA and Microsoft rolled out turnkey agent sandboxing on native Windows -- Microsoft eXecution Containers plus the NVIDIA OpenShell runtime -- alongside up to 2x faster agentic inference and native Windows support for Hermes Agent. 🤖DGX Spark goes from unboxing to a running agent in minutes -- A streamlined NVIDIA NemoClaw install gets developers to a working local agent fast, with Qwen3.6-35B running up to 2.6x faster on vLLM. And the new cluster assistant in NVIDIA Sync links up to four DGX Spark units into one 512GB pool -- enough for ~400-billion-parameter models. Plug in to RTX Spark on Facebook, Instagram, TikTok and X -- and stay informed by subscribing to the RTX Spark newsletter.
[6]
Google's new DiffusionGemma model speeds up text generation by 4x
Google has unveiled DiffusionGemma, a new experimental AI model that generates text using diffusion rather than the autoregressive approach used by most large language models today. The company says the model can deliver up to four times faster text generation on dedicated GPUs while running on consumer hardware. The model builds on Google's Gemma 4 family and Gemini Diffusion research. Unlike traditional language models that generate text one token at a time from left to right, DiffusionGemma creates and refines blocks of text in parallel. According to Google, the approach enables output speeds exceeding 1,000 tokens per second on an NVIDIA H100 GPU and more than 700 tokens per second on an NVIDIA GeForce RTX 5090. The company says DiffusionGemma is aimed at developers working on speed-sensitive applications such as interactive editing, rapid content iteration, code infilling, and other workflows where low latency is more important than maximum output quality. Most large language models generate text sequentially, predicting one token after another. While effective, this process can leave local hardware underutilized when serving a single user. DiffusionGemma takes a different approach. Instead of generating text word by word, it creates a 256-token block at once and then repeatedly refines it through multiple passes. Google compares the difference to moving from a typewriter to a printing press. Rather than waiting for each token to be generated before producing the next one, the model processes an entire section of text simultaneously. The company says this shifts the bottleneck from memory bandwidth to compute performance, allowing modern GPUs to operate more efficiently during local inference. Another key feature is bi-directional attention. Since the model generates text in parallel, every token can attend to every other token during generation. This makes it better suited for tasks where future context matters, such as code completion, in-line editing, mathematical structures, and biological sequences. Google highlighted a demonstration in which DiffusionGemma was fine-tuned to solve Sudoku puzzles, a task that can be challenging for conventional autoregressive models because later tokens influence earlier decisions. The model uses a 26-billion-parameter mixture-of-experts architecture but activates only 3.8 billion parameters during inference. According to Google, this allows the model to fit within roughly 18 GB of VRAM when quantized, making it accessible on high-end consumer GPUs. DiffusionGemma also includes an iterative self-correction mechanism. Because it evaluates an entire text block during refinement, it can identify and fix mistakes as generation progresses. However, Google acknowledged that the model prioritizes speed over quality. The company said standard Gemma 4 models remain the preferred choice for production environments where output quality is the primary concern. The speed advantage is also most apparent in local deployments and low-concurrency environments. In cloud settings serving large numbers of users simultaneously, conventional autoregressive models can often utilize hardware efficiently through batching, reducing the benefits of diffusion-based generation. Google has released DiffusionGemma under an Apache 2.0 license through Hugging Face and is supporting deployment through tools including MLX, vLLM, Hugging Face Transformers, NVIDIA NeMo, and Unsloth.
[7]
Google's DiffusionGemma AI Hits 1,000 Tokens Per Second -- And It's Free
On NVIDIA NIM, the model arrived preconfigured at 8,192 tokens of context -- below the 64,000-token floor that agentic frameworks like Hermes Agent require -- meaning autonomous workflows won't run without manual reconfiguration. Google dropped DiffusionGemma today, an open model AI that generates text the way image generators create pictures: start with noise, refine until it makes sense. It hits 1,000 tokens per second on an NVIDIA H100. (Tokens are the basic unit of information that an AI model handles.) That means it's four times faster than regular Gemma. It's also free, Apache 2.0, with weights on Hugging Face. The catch, as always, is in the fine print. Per Google's announcement, the model hits "700+ tokens per second on NVIDIA GeForce RTX 5090." It also trails standard Gemma 4 on output quality. Google says so themselves. This is a speed model, not a quality upgrade. What this actually does Every LLM you've used is a typewriter. One token at a time with each word dependent on the last. That's how autoregressive architectures work. DiffusionGemma doesn't do that. Instead of generating tokens sequentially, it starts with refined chunks of garbled text in parallel. Per Google's developer guide, it "starts with a canvas of random placeholder tokens" and iteratively locks in confident tokens until the whole block snaps into focus. Two hundred fifty-six tokens per forward pass. The GPU stays busy. The side effect is bidirectional attention -- every token can see every other token while being generated, which is impossible in autoregressive models (they cannot see the future, what is going to be encoded). That makes it unusually good at tasks where the end of the answer constrains the beginning: code infilling, structured output, constraint-heavy problems, etc. Google fine-tuned a version to solve Sudoku as a demo. The base model got roughly 0% of puzzles right. The fine-tuned version hit 80%. Text diffusion has been a research project for years. MDLM, SEDD, LLaDA, Dream -- academic models that proved the approach worked at small scales and mostly stayed as proof of concepts. Inception Labs shipped Mercury 2 in February 2026 as the first commercial diffusion reasoning model, claiming speeds five times faster than speed-optimized competitors. But none of that was open-weight, and none of it came with day-zero support in vLLM, Hugging Face Transformers, and Unsloth. DiffusionGemma is the first major open release from a tier-one lab. There's also a historical irony worth noting. Image generators started as diffusion models (hence the name Stable Diffusion) and are now moving toward autoregressive architectures for better quality. Language models started as autoregressive and are now experimenting with diffusion for speed. Why it's a pain to run... for now Running DiffusionGemma efficiently requires a drafter -- a lightweight module that proposes token blocks in parallel, which the main model then verifies in one forward pass. This is called speculative decoding. DFlash is a framework published in early 2026 that uses a small diffusion model as the drafter, enabling over 6x speedup on some tasks. It's the engine that makes this class of model practical. The problem: DiffusionGemma needs a specific drafter to run locally via MLX -- Apple's machine learning framework for Apple Silicon. That module doesn't exist in any public version of mlx-lm, in any open pull request, or in LM Studio's bundled runtime. We tried running DiffusionGemma with Hermes through NVIDIA NIM. The model loaded, but then: "agent init failed: Model google/diffusiongemma-26b-a4b-it has a context window of 8,192 tokens, which is below the minimum 64,000 required by Hermes Agent." To be precise: DiffusionGemma's actual context window is 256K tokens. The 8,192 figure was Nvidia messing things up by default, not the model's architectural limit. In practice, getting it configured correctly for agentic use requires manual work that most everyday users haven't figured out yet, and Hermes Agent simply won't initialize without it. Parallel speed means nothing if the agent can't boot. Hopefully, in the next few days, the community will produce better resources to run these models. Who this is actually for Developers with NVIDIA RTX 4090 or 5090 hardware building real-time tools -- inline editors, autocomplete, code infilling, structured generation. That's the target. As Decrypt covered in May, Google has been on a steady push to make local inference faster without new hardware. For researchers, bidirectional generation opens territory that autoregressive models simply can't reach -- protein sequences, mathematical graphs, anything where position N depends on position N+50. That's not a small thing. Google launched Gemma 4 under Apache 2.0 in April, and DiffusionGemma continues that strategy. There's already a draft llama.cpp PR open as of today. When the toolchain catches up, this reaches a much wider audience. On a machine with a capable discrete GPU, 1,000 tokens per second is real.
[8]
DiffusionGemma: 4x faster text generation
You can improve DiffusionGemma's performance on specific tasks through fine-tuning. In the example below, Unsloth fine-tuned DiffusionGemma to play Sudoku -- a task autoregressive models struggle with because each token depends on future tokens. DiffusionGemma's bi-directional attention makes this much easier. While the AI research community has explored diffusion-based text generation for years, applying it to large models has remained a challenge. DiffusionGemma changes this by shifting how models use hardware. The trade-off with traditional models Most language models act like a typewriter, generating one token at a time from left to right. In the cloud, this is efficient because servers can batch thousands of user requests together to share the hardware load. But when run locally for a single user, this word-by-word process leaves your dedicated GPU or TPU underutilized -- it spends most of its time simply waiting for the next "keystroke." DiffusionGemma reverses this inefficiency. Instead of predicting words sequentially, it drafts an entire 256-token paragraph simultaneously. By giving the computer's processor a larger chunk of work at once, DiffusionGemma utilizes your hardware to its full potential. It upgrades your model inference from a single, sequential typewriter to a massive printing press that stamps the entire block of text simultaneously.
[9]
Google open-sources speedy DiffusionGemma text diffusion model
Google open-sources speedy DiffusionGemma text diffusion model Google LLC today released DiffusionGemma, a large language model based on an emerging machine learning approach known as text diffusion. The company says that the algorithm can generate text four times faster than traditional LLMs. Furthermore, DiffusionGemma does so using less RAM. The model's memory efficiency enables it to run on high-end consumer graphics cards that usually struggle to support LLMs. DiffusionGemma's text diffusion architecture is derived from a method that AI models use to generate images. The image generation workflow begins with a blurry photo that contains a type of error called Gaussian noise. An AI model removes a small portion of the noise, analyzes the enhanced photo and uses its findings to restore another batch of pixels. It then repeats the process until arriving at a usable image. When DiffusionGemma receives a prompt, it generates a placeholder response that comprises random words. It then replaces a subset of the random text with words that will form part of its answer to the user's prompt. DiffusionGemma reviews the edits, generates a few more words and repeats the process until its prompt response is ready. AI models usually generate prompt responses one token at a time. DiffusionGemma's text diffusion architecture, by contrast, enables it to produce 256 tokens at once. That parallelization is what makes the model faster than standard LLMs. Google says that DiffusionGemma can generate more than 1,000 tokens per second when running on a single H100, a server-grade GPU that Nvidia Corp. launched in 2022. The model can generate over 700 tokens per second on the chipmaker's desktop-grade GeForce RTX 5090 chip. One reason DiffusionGemma can run on consumer GPUs is that it's based on a mixture of experts architecture. The model includes 26 billion parameters but activates only 3.8 billion of them to answer the prompt, which lowers memory usage. DiffusionGemma further lowers RAM consumption by keeping information in a lightweight data format called NVFP4. DiffusionGemma is based on an LLM called Gemma 4 26B A4B that Google released in April. To facilitate text diffusion, the search giant replaced the latter model's attention mechanism, the software module it uses to interpret prompts. The original mechanism inferred the meaning of each word in a prompt by analyzing the preceding text. The new attention module also reviews the text that follows a given word. "While the AI research community has explored diffusion-based text generation for years, applying it to large models has remained a challenge," Google research scientists Brendan O'Donoghue and Sebastian Flennerhag wrote in a blog post today. "DiffusionGemma changes this by shifting how models use hardware." DiffusionGemma is available on Hugging Face under an open-source license.
[10]
NVIDIA Delivers Day-1 Support For DeepMind's DiffusionGemma Open Model Across RTX & DGX Platforms, 150 Tokens/s With DGX Spark
NVIDIA's entire RTX/DGX lineups are getting full support for Google DeepMind's DiffusionGemma Open AI model. Google Intros Its Newest Open AI Model: DiffusionGemma - NVIDIA Offers Full Support Across Its DGX & RTX Families The DiffusionGemma model is an open model designed to offer speedy text generation, and with its launch, NVIDIA is announcing support across its RTX and DGX lineups. What's even better is that while DiffusionGemma is fast, NVIDIA's optimizations for the model and its hardware make it even faster. The following are the main highlights of the model: * Parallel generation: DiffusionGemma denoises up to 256 tokens per step instead of predicting one at a time. * Built on Gemma 4: DiffusionGemma is built on Gemma 4, a 26-billion-parameter mixture-of-experts model that activates just 3.8 billion parameters per step, pairing a diffusion head with Google's Gemma 4 architecture. * Up to 4x faster performance: The boost means fast text generation, where single-user generation usually stalls -- on local hardware. * Open and local: DiffusionGemma is open-weight under a permissive Apache 2.0 license and runs entirely on RTX and DGX Spark -- no cloud, no per-token cost -- with day-zero support in Hugging Face Transformers, vLLM and Unsloth. On NVIDIA's side, they are offering day-1 support across GeForce RTX GPUs, RTX PRO Platforms, and DGX systems ranging from Spark Mini PCs to workstations powered by their datacenter-grade chips. NVIDIA is utilizing its tensor core architecture and the CUDA software stack, offering robust support that requires no additional tuning. NVIDIA has shared some stats too. The company states that its H100 Tensor Core GPUs on DGX Stations offer 1000 tokens/s (single GPU), DGX Spark systems offer 150 tokens/s, and DGX Station offers the fastest in-class local inference. The solutions offer roughly 4 times faster performance than an equivalent autoregressive model. * Locally on the NVIDIA DGX Spark deskside personal AI supercomputer -- powered by the NVIDIA GB10 Grace Blackwell Superchip with 128GB of unified memory -- with the preinstalled NVIDIA AI software stack ready for prototyping, fine-tuning and fully local agent workflows. * On NVIDIA RTX PRO 6000 workstations, providing developers, researchers, and AI professionals with the headroom to run local low-latency generation and agentic loops as part of a professional workflow. * On DGX Station, delivering best-in-class, high-speed inference at up to 800 tokens/sec for low-latency text generation and agentic loops with 748GB of coherent memory. * On GeForce RTX GPUs, with llama.cpp support coming soon. Users who want to try out the DiffusionGemma model out of the box can do so right now on an RTX 5090 or DGX Spark system. NVIDIA offers a full-stack and ready-to-use framework to try out the model right now. Follow Wccftech on Google to get more of our news coverage in your feeds.
[11]
Google unveils DiffusionGemma open AI model with up to 4x faster text generation
Google has introduced DiffusionGemma, an experimental open-weight AI model that explores diffusion-based text generation. Released under the Apache 2.0 license, the 26-billion-parameter Mixture-of-Experts (MoE) model moves beyond the sequential token-by-token generation used by traditional autoregressive large language models, instead generating and refining entire blocks of text simultaneously. Built on the intelligence-per-parameter efficiency of the Gemma 4 family and Google DeepMind's Gemini Diffusion research, DiffusionGemma incorporates a dedicated diffusion head designed to maximize generation speed. Google says the model can deliver up to 4x faster text generation on GPUs, making it suitable for researchers and developers exploring speed-critical local AI workflows such as inline editing, rapid iteration and the generation of non-linear text structures. DiffusionGemma focuses on parallel text generation Unlike traditional autoregressive LLMs that generate text one token at a time, DiffusionGemma uses a diffusion-based approach that generates and refines up to 256 tokens simultaneously. The model starts with random placeholder tokens and progressively improves them through multiple denoising passes until the text converges into a final output, similar to how diffusion-based image generators transform visual noise into finished images. Because all tokens can attend to one another through bi-directional attention, DiffusionGemma is particularly suited for tasks such as inline editing, code infilling, mathematical graphs, amino acid sequences and other non-linear text generation workloads. The iterative refinement process also allows the model to evaluate an entire text block at once, helping it correct mistakes during generation and enabling behaviors such as correctly closing complex markdown structures and generating code in near real time. Performance and hardware requirements DiffusionGemma is built as a 26B Mixture-of-Experts model that activates only 3.8 billion parameters during inference. When quantized, the model can fit within approximately 18GB of VRAM, allowing it to run on high-end consumer GPUs. Google and NVIDIA say the model shifts text generation from a memory-bandwidth bottleneck to a compute-intensive workload, enabling better utilization of modern GPUs, Tensor Cores and CUDA optimizations. The companies describe this transition as moving from a sequential typewriter to a printing press that generates entire text blocks simultaneously. Performance figures shared by Google and NVIDIA include: * More than 1,000 tokens per second on a single NVIDIA H100 GPU * More than 700 tokens per second on an NVIDIA GeForce RTX 5090 * Around 150 tokens per second on NVIDIA DGX Spark * Up to 2,000 tokens per second on NVIDIA DGX Station * Up to 4x faster text generation than comparable autoregressive models in local inference scenarios Google notes that these gains are primarily designed for local and low-concurrency inference. In high-QPS cloud environments, autoregressive models can efficiently utilize hardware through batching, reducing the advantages of diffusion-based parallel decoding and potentially increasing serving costs. The throughput advantage is strongest at low-to-medium batch sizes on a single accelerator. Fine-tuning and use cases Google says DiffusionGemma can be fine-tuned for domain-specific workloads. As an example, Unsloth fine-tuned the model to solve Sudoku puzzles, a task that can be challenging for autoregressive models because predictions often depend on future tokens. DiffusionGemma's bi-directional attention makes these types of workloads easier to handle. The company expects the model to be useful for interactive chat, local AI assistants, agentic loops, on-device assistants that can plan and act, rapid content iteration, inline editing and other latency-sensitive AI applications. While DiffusionGemma prioritizes speed and parallel generation, Google notes that its overall output quality remains lower than standard Gemma 4 models. For applications that require the highest quality production outputs, the company recommends using standard Gemma 4 models instead. NVIDIA optimization and platform support NVIDIA has optimized DiffusionGemma across its hardware ecosystem, including GeForce RTX GPUs, RTX PRO workstations, DGX Spark systems and DGX Station platforms. The company says the model can run entirely on supported RTX and DGX systems without relying on cloud inference or per-token API costs. Supported platforms include: * NVIDIA DGX Spark: Powered by the NVIDIA GB10 Grace Blackwell Superchip with 128GB of unified memory for local AI development, prototyping, fine-tuning and agent workflows. * NVIDIA RTX PRO 6000: Designed for developers, researchers and AI professionals running low-latency local AI applications. * NVIDIA DGX Station: Delivers up to 2,000 tokens per second and features 748GB of coherent memory for advanced local AI workloads. * GeForce RTX GPUs: Optimized for consumer hardware, with official llama.cpp support expected in a future update. Google says it worked closely with NVIDIA to optimize the model across consumer and enterprise hardware. This includes support for quantized deployments on GeForce RTX 4090 and RTX 5090 GPUs, as well as Hopper and Blackwell systems using advanced NVFP4 (4-bit floating-point) kernels. Native NVFP4 support improves compute throughput while maintaining near-lossless accuracy. Developer ecosystem and availability DiffusionGemma is available now as experimental open weights under the Apache 2.0 license. The model launches with day-zero support across multiple AI frameworks and developer tools. Frameworks and serving tools * Hugging Face Transformers * vLLM * MLX * NVIDIA NIM * Red Hat-integrated vLLM deployments Fine-tuning tools * Unsloth * NVIDIA NeMo * Hackable Diffusion, a modular JAX toolbox designed for composable experimentation Documentation and resources * DiffusionGemma Developer Guide * A Visual Guide to DiffusionGemma * Deployment playbooks for DGX Spark, RTX PRO and DGX Station Ways to access DiffusionGemma * Download open weights from Hugging Face * Test the model through NVIDIA-hosted APIs * Deploy locally on supported RTX and DGX hardware * Access through NVIDIA NIM * Use through Gemini Enterprise Agent Platform Model Garden Google also notes that official llama.cpp support is planned for a future release.
[12]
Google launches DiffusionGemma with 4x faster text generation By Investing.com
Investing.com - Google (NASDAQ:GOOGL) released DiffusionGemma today, an experimental open model that generates text up to four times faster than traditional language models on dedicated GPUs. The 26 billion parameter Mixture of Experts model uses text diffusion to generate entire blocks of text simultaneously rather than processing tokens sequentially. The model activates only 3.8 billion parameters during inference and fits within 18GB VRAM limits of high-end consumer GPUs when quantized. DiffusionGemma achieves over 1,000 tokens per second on a single NVIDIA (NASDAQ:NVDA) H100 GPU and over 700 tokens per second on NVIDIA GeForce RTX 5090 hardware. DiffusionGemma generates 256 tokens in parallel with each forward pass, allowing bi-directional attention where every token can attend to all others. The model iteratively refines its own output to fix mistakes in real-time, though Google states its overall output quality is lower than standard Gemma 4 models. Google released the model under an Apache 2.0 license on Hugging Face. The company designed DiffusionGemma for researchers and developers exploring speed-critical, interactive local workflows such as in-line editing, rapid iteration, and generating non-linear text structures. The model works with MLX, vLLM with Red Hat integration, Hugging Face Transformers, Unsloth, and NVIDIA NeMo. Google worked with NVIDIA to optimize performance across the hardware stack, including GeForce RTX 5090 and 4090 GPUs for consumer setups and Hopper and Blackwell systems using NVFP4 kernels for enterprise deployments. This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
Share
Copy Link
Google DeepMind unveiled DiffusionGemma, an experimental open-source AI model that generates text in parallel rather than sequentially. The model achieves over 1,000 tokens per second on NVIDIA H100 GPUs and runs on consumer hardware with just 18GB of memory. However, the speed gains come with a notable trade-off in output quality compared to traditional models.
Google DeepMind Introduces Experimental Open-Source AI Model with Novel Architecture
Google DeepMind has released DiffusionGemma, an experimental open-source AI model that fundamentally reimagines how language models generate text. Unlike conventional autoregressive models that produce text one token at a time from left to right, DiffusionGemma employs image generation techniques borrowed from systems like Stable Diffusion to create entire blocks of text simultaneously
2
. This latest addition to the Gemma 4 family marks a significant departure from traditional language model design, prioritizing speed and efficiency for local hardware deployment over the sequential processing that has dominated the field3
.
Source: Ars Technica
The model operates through a denoising process that starts with a canvas of random placeholder tokens and progressively refines them across multiple passes until coherent text emerges. DiffusionGemma can denoise up to 256 tokens per step instead of predicting one at a time, enabling parallel text generation that shifts the computational bottleneck from memory bandwidth to compute
5
. This architectural choice makes the model particularly well-suited for single-user scenarios where traditional models often leave GPUs underutilized.Mixture-of-Experts Architecture Enables Faster Text Generation on Consumer Hardware
Built as a Mixture-of-Experts model with 26 billion total parameters, DiffusionGemma activates only 3.8 billion parameters during inference, allowing it to fit within the 18GB memory footprint of high-end consumer GPUs. In testing on an RTX 5090, the model delivers approximately 700 tokens per second, while a single NVIDIA H100 accelerator achieves over 1,000 tokens per second. These figures represent roughly four times the inference speed of similarly sized autoregressive models running in the same single-user regime
5
.
Source: NVIDIA
NVIDIA has optimized DiffusionGemma to run across its full hardware lineup, from GeForce RTX GPUs to the RTX PRO platform and DGX Spark systems
5
. The model's parallel generation approach transforms text generation from a memory-bound problem into a compute-bound workload, playing directly to the strengths of NVIDIA GPUs and their Tensor Cores5
. This makes DiffusionGemma particularly effective for developers and researchers running latency-sensitive, single-user workloads where interactive responsiveness matters.Output Quality Trade-Off Limits Production Readiness
While DiffusionGemma achieves impressive speed gains, Google acknowledges the model does not match the output quality of standard Gemma 4 models
4
. The writing can be less stable and less refined, with higher error rates than traditional approaches. In the GPQA-Diamond benchmark, the 26 billion-parameter model falls just behind Gemma 4 12B, with its primary advantage being output speed rather than accuracy2
.This trade-off stems from fundamental differences between language and images. While a single mispredicted pixel in image diffusion models doesn't render the output useless, language is discrete—an equivalent error in text can make an entire block of tokens meaningless and force regeneration. Additionally, diffusion models waste resources when the desired output is only a few tokens long, requiring extensive parallel work that autoregressive models complete more efficiently in just a few steps.
Related Stories




Specialized Use Cases and Availability
Despite quality limitations, DiffusionGemma excels at non-linear tasks where its ability to see and refine entire blocks simultaneously provides advantages. The model performs well on in-line editing, molecular sequencing, mathematical graphing, and structured formats like JSON. Google demonstrated how DiffusionGemma was tuned to solve Sudoku puzzles, a notoriously challenging task for standard autoregressive AI models because each token depends on future tokens. The model's capacity to continuously self-correct large sets of tokens makes such logic-heavy problems more tractable.
Source: SiliconANGLE
Google has released DiffusionGemma under the permissive Apache 2.0 license, with model weights available for download on Hugging Face. Support has already been merged into popular inference engines including vLLM, MLX, and Hugging Face Transformers, with llama.cpp support coming soon
2
. The model can be tested for free using NVIDIA-hosted APIs at build.nvidia.com5
. While positioned as an experimental tool rather than a production-ready solution, DiffusionGemma signals a potential direction for AI text generation where models draft and refine entire passages rather than typing them out sequentially.References
Summarized by
Navi
[2]
[3]
[4]
Related Stories
Recent Highlights
1
OpenAI AI agent broke free from testing sandbox and hacked Hugging Face to cheat on benchmark
Technology

2
Xi Jinping positions China AI as alternative to US tech dominance at Shanghai conference
Policy and Regulation

3
AI disproves 87-year-old Jacobian conjecture, sparking debate on AI's role in mathematics
Science and Research

Recent Highlights
Today's Top Stories



Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


