OpenAI launches ChatGPT Images 2.0 with text rendering that finally works
28 Sources
[1]
ChatGPT's new Images 2.0 model is surprisingly good at generating text | TechCrunch
It used to be easy enough to distinguish between human-made and AI-generated imagery -- just two years ago, you couldn't use image models to create a menu for a Mexican restaurant without inventing new culinary delights like "enchuita," "churiros," "burrto," and "margartas." Now, when I ask the brand new ChatGPT Images 2.0 model for a menu of Mexican food, it creates something that could immediately be used in a restaurant without customers noticing that something's off. (However, ceviche priced at $13.50 might make me question the quality of the fish). For comparison, here's the result I got from DALL-E 3 two years ago. (At the time, ChatGPT did not generate images): AI image generators have historically struggled to spell because they generally used diffusion models, which work by reconstructing images from noise. "The diffusion models [...] are reconstructing a given input," Asmelash Teka Hadgu, founder and CEO of Lesan AI, told TechCrunch in 2024. "We can assume writings on an image are a very, very tiny part, so the image generator learns the patterns that cover more of these pixels." Researchers have since explored other mechanisms for image generation, like autoregressive models, which make predictions about what an image should look like and function more like an LLM. Unfortunately, OpenAI declined to answer a question in a press briefing this week about what kind of model is powering ChatGPT Images 2.0. The company did, however, explain that the new model has "thinking capabilities," which give it the ability to search the web, make multiple images from one prompt, and double-check its creations -- this allows Images 2.0 to create marketing assets in various sizes, as well as multi-paneled comic strips. OpenAI also says that Images has a stronger understanding of non-Latin text rendering in languages like Japanese, Korean, Hindi, and Bengali. The model's knowledge cuts off in December 2025, which could impact how accurately it can generate certain prompts involving recent news. "Images 2.0 brings an unprecedented level of specificity and fidelity to image creation. It can not only conceptualize more sophisticated images, but it actually brings that vision to life effectively, able to follow instructions, preserve requested details, and render the fine-grained elements that often break image models: small text, iconography, UI elements, dense compositions, and subtle stylistic constraints, all at up to 2K resolution," OpenAI said in a press release. These capabilities mean that image generation isn't as rapid as typing a question to ChatGPT, but generating something complex like a multi-paneled comic still takes just a few minutes. All ChatGPT and Codex users will be able to access Images 2.0 starting Tuesday; paid users will be able to generate more advanced outputs. The company will also make the gpt-image-2 API available, with pricing dependent on the quality and resolution of outputs.
[2]
OpenAI Beefs Up ChatGPT's Image Generation Model
OpenAI launched a new image generation AI model on Tuesday, dubbed ChatGPT Images 2.0. This model can generate more than one image from a single prompt, like an entire study booklet, as well as output text, including in non-English languages, like Chinese and Hindi. This release is available globally for ChatGPT and Codex users, with a more powerful version available for paying subscribers. When any major AI company releases a new image model, it can revive interest and boost usage, especially if social media users adopt a meme-able trend, transforming images of themselves. Last year, Google's launch of the Nano Banana model was a major moment for the company, especially when users started posting hyperrealistic figurines of themselves online. Earlier this year, ChatGPT Images made waves on social media as users shared AI-generated caricatures. Since the new model can tap into ChatGPT's "reasoning" capabilities, Images 2.0 can search the internet for recent information and generate more than one image at a time. In essence, the bot can use additional steps to output more thorough generations from a single prompt. Images 2.0 also has a more recent knowledge cutoff date: December 2025. This also means that outputs from the new model are more granular. For example, I generated an infographic with San Francisco's weather forecast for the next day, as well as activities worth doing. The image ChatGPT generated included accurate weather details for the rainy day, along with accurate-looking drawings of the Ferry Building, Castro Theater, Painted Ladies houses, and Transamerica Pyramid. Additionally, Images 2.0 is more customizable for users who want unique aspect ratios for image outputs. The new model can generate images, ranging from 3:1 wide to 1:3 tall, and users can adjust the image's size as part of their prompt to the AI tool. After a few hours of generating images with the new model, I was generally impressed with the text rendering capabilities, in English at least. Not that long ago, image outputs featuring text, from any of the major models, often included numerous malformed characters or words with errant extra letters. ChatGPT struggled to label images accurately two years prior, so the cleaner, more complex outputs from Images 2.0 are a sign of continued improvement. Google has also focused on improving image outputs featuring text in its recent iterations of Nano Banana.
[3]
ChatGPT Images 2: Why OpenAI Built a New Image Model After Killing Sora
A lot has changed in the AI industry in the four months since OpenAI released ChatGPT Images 1.5. We've seen a heated race to build agentic tools, an unprecedented deal with the Pentagon and unending AI slop. Now, OpenAI is back in the generative media game. The company announced on Tuesday that it's releasing ChatGPT Images 2, its next-generation image model. It may seem strange that OpenAI is releasing a new image model just a month after announcing the shuttering of its once-viral Sora AI video app in order to focus on building enterprise-ready "core products." But it's clear from how the new model was built that OpenAI isn't backtracking on that goal. ChatGPT Images 2 is designed to produce text-heavy images, including infographics, scientific posters, study guides and marketing materials. The days of weird Sora videos and Studio Ghibli-inspired memes are over. Now, the company is building AI that can do what it calls "economically valuable creative tasks." "The aperture and use cases for visual intelligence just expand so broadly, and we believe that this is so critical to ChatGPT's vision for developing your own personal assistant, because your creative assistant is a huge part of who you are as an individual," Adele Li, product lead for ChatGPT Images, told reporters in a press briefing. (Disclosure: Ziff Davis, CNET's parent company, in April 2025 filed a lawsuit against OpenAI, alleging it infringed Ziff Davis copyrights in training and operating its AI systems.) OpenAI has been chasing the dream of a super app, a one-stop shop for all things AI, built out of its Codex platform. ChatGPT Images 2 is bringing the creative piece of that puzzle. The new model naturally improves typography, iconography and composition to produce more professional AI images. It can generate text in multiple languages. AI image models have notoriously struggled with creating legible, factually correct text. ChatGPT Images 2 is OpenAI's best model for that yet. Google previously improved its text rendering with Nano Banana Pro, but even that "best of the best" model struggled with accuracy. ChatGPT Images 2 is rolling out to all users now. Your generation limit depends on your plan: The more you pay, the more AI images you can generate. Developers using the model in the API can create images in 2K and 4K resolution, though these higher resolutions are still in beta and may be wonky. Paying users can also create images using thinking and reasoning models, which help them search the web for information, compile it into a readable design and double-check their work. "Image model" doesn't seem like quite the right term for ChatGPT Images 2, though it is technically correct. ChatGPT doesn't capture the fantastical surrealism of AI imagery like Midjourney, nor offer anywhere near the editing tools of Adobe Firefly. But it's catering to a group of users in the middle of the spectrum of Midjourney's artistic enthusiasts and Adobe's professional creators: those who need to create attractive content. Like Anthropic's newly released Claude Design, OpenAI's ChatGPT Images 2 is aimed at working professionals. Teachers can use it to create study guides and illustrated lesson plans. Marketing managers can create social media posts and visual assets. You can create up to eight images from a single prompt, like a three-page report, that maintain visual consistency across all of them. One downside is that if you want to tweak an AI image, you'll still need to regenerate it. With more text-heavy designs, that's more likely to be necessary, so you'll run through your credits quicker. OpenAI said it's focused on maintaining its iterative, prompt-based editing flow to keep it easy to use. OpenAI's safety procedures haven't significantly changed since its last image model. It still includes metadata through the C2PA standard, so AI images' origins can be identified. Abusive and illegal imagery is still prohibited in OpenAI's policies, an important guardrail for AI companies to effectively enforce, given recent examples of AI-generated deepfakes and nonconsensual intimate imagery.
[4]
I got an early look at ChatGPT Images 2.0, and it's impressive - with one exception
Today, OpenAI announced ChatGPT Images 2.0, its next-generation image model, which the company says is focused on precision, usability, and complex visual tasks. The most notable new capability is the ability to combine text and images to build complex, beautiful pages. OpenAI is reframing the whole idea of image generation from a process that creates decorations (their word) to a language (also their term). Also: The best AI image generators of 2026: There's only one clear winner now OpenAI describes it as, "A good image does what a good sentence does -- it selects, arranges, and reveals. It can explain a mechanism, stage a mood, test an idea, or make an argument." In addition to its vastly improved ability to mix text and graphics, the new model uses enhanced thinking capabilities. It can generate multiple images per prompt with continuity across outputs. This approach is possible because the model actually integrates reasoning into the image output. This shift is big. Instead of just producing an image that pretty much matches the prompt details, Images 2.0 can take a much vaguer prompt, like "Generate an infographic about activities I should do with tomorrow's weather in San Francisco in mind." Also: How to switch from ChatGPT to Gemini From this prompt, the AI will gather weather and activity data about San Francisco, determine activities appropriate to the weather, and then build an image or set of images that fit the results. According to OpenAI, "In this model, Images 2.0 acts more like a visual thought partner, helping carry a project from rough concept to finished asset with significantly less work on your part." Many of us have long struggled to convince ChatGPT to generate images in a specific desired aspect ratio. Often, the AI stubbornly produces what it wants. But now, with Images 2.0, the model has support for "aspect ratios as wide as 3:1 and as tall as 1:3." The model also supports higher-fidelity outputs that (mostly) produce accurate object placement, detailed text rendering, and complex compositions. We'll see if we can remove the word "mostly" from that sentence after the product is officially released. Also: I tried Personal Intelligence, and it was accurate (but unsettling) The AI also supports small text, UI elements, and stylistic constraints at up to 2K resolution. Cool. I was given access to a day-before-release preview, and the model is impressive, mostly. I fed it a screenshot of the ZDNET home page and a draft of the Images 2.0 press release. Then I instructed, "Based on the contents of the press release, generate a 16:9 infographic about the new image update and generate it using the ZDNET brand style as shown in the ZDNET home page document." Also: I tried Google Photos' new AI Enhance tool: How it crops, relights, and fixes your shots - sometimes The model did a great job on the infographic, but try as it might, it could not reproduce the ZDNET logo. On its first try, it rendered the Z in ZDNET with a slight droop. I tried a variety of requests on the order of, "Fix the ZDNET Logo. The Z droops in your version but is not droopy in the actual logo." But Images 2.0 never managed to fix it. So I started a new session. This time, I included the instruction, "Use special care to reproduce the ZDNET logo accurately." Also: I tested ChatGPT Plus vs. Gemini Pro to see which is better - and if it's worth switching Here's where things got very odd. For its first run, the model somehow dug up a copy of ZDNET's logo from before our 2022 redesign. This logo is nowhere to be found on our current home page. Weirdly, it rendered that old logo using the current color scheme. The model then pushed the logo and the infographic information off the left edge of the image. It also chose a light blue for "Images 2.0" that's not a ZDNET brand color. I tried mightily to convince it to use the current logo. I managed to get it to push the image to the right, so nothing was cut off. But adding the prompt, "Use the ZDNET logo that is on the provided page. Do not search for an alternative logo," did nothing to fix the problem. I took one more shot at the challenge before deciding to go back to finishing up this article. Once again, I started a new session so the AI didn't have muscle memory from its previous miscalculations. Also: This powerful Gemini setting made my AI results way more personal and accurate The model messed up the logo again. This time, the AI decided to add a rudder shape to the stem of the stretched-out capital D. To be fair, I'm using a pre-release version of Images 2.0. I'll be back with a much more comprehensive test run of the model after the official product release. I also tried a similar test using a different document with Google's Nano Banana Pro, but because it didn't handle the synthesis the way that this new version of OpenAI's product does, it wasn't really able to repeat the results I got here. We'll know more as we do more advanced tests The new model is available today to all ChatGPT and Codex users. Advanced outputs and the thinking capability are available to ChatGPT Plus, Pro, Business, and Enterprise users. Be sure to select "Thinking" from the ChatGPT dropdown bar at the top of the screen. At the time of writing, before release, the new Images 2.0 model is only available on the desktop. But OpenAI promises that these capabilities will be in the mobile version as well, along with the ability to finger-select images using your mobile touchscreen. The images are also available via API using the gpt-image-2 model. API pricing varies depending on the quality, thinkiness (my word), and desired image resolution. If an AI can handle layout and content in combination, will that change how you approach design projects? Let us know in the comments below.
[5]
OpenAI Boosts ChatGPT's Image Generator With Web Access, Multi-Image Support
Images 2.0 brings more realistic outputs, alongside improved background and text accuracy. OpenAI rolled out an update to ChatGPT's image generation model on Tuesday that can reference web information, create multiple outputs at once, and deliver images containing non-Latin text. Images 2.0 is also ChatGPT's first image model with "thinking" capabilities. This is the company's third image model, following the launch of Images last March and Images 1.5 in December. OpenAI says the new Images 2.0 is "a step change" over its predecessor in terms of instruction following, object placement, text rendering, and handling aspect ratios. Images 2.0 is now open to all ChatGPT and Codex users. However, advanced thinking outputs are restricted to ChatGPT Plus, Pro, and Business users. I gave the new model a quick try, and the results didn't disappoint. When you select a thinking or pro model, the model can reference web information before delivering outputs. Its knowledge cut-off is currently December 2025. The thinking model can also help generate a group of images with a single prompt. For example, ask ChatGPT to generate multiple pages of a comic book, and it will maintain consistency across the pages for characters, font, color palette, and overall mood. You can generate up to eight pages at once. The feature can also be helpful for social media teams, as they can ask the model to generate media assets in various aspect ratios at once. Support for non-Latin text is another bonus. You can now ask ChatGPT to generate posters, flyers, or instructions in non-English languages, such as Japanese, Korean, Chinese, Hindi, Bengali, and others. One of OpenAI's samples had a book cover in the Indian language of Gujarati. I tried getting Images 2.0 to create a set of instructions in that language, and unlike its predecessor, the output had clear text, grammatical accuracy, and natural phrasing. Another noticeable upgrade is photorealism. Images 2.0 can generate realistic humans with accurate skin tone, features, and dressing style, while also adapting the background to match the time period in the prompt. I asked it to create an image of a man enjoying a burger in a crowded McDonald's in the 1990s, and you can check out the result below. The model has a few more use cases, and you can check them out in OpenAI's blog post. Images 2.0 competes directly with Google's Nano Banana Pro and Nano Banana 2. The last time we compared flagship image generators from the two, Nano Banana Pro was the winner. Disclosure: Ziff Davis, PCMag's parent company, filed a lawsuit against OpenAI in April 2025, alleging it infringed Ziff Davis copyrights in training and operating its AI systems.
[6]
OpenAI Unveils New Image Model That's Better at Charts and Diagrams
OpenAI is releasing an update to its artificial intelligence image-generating software that it says will let users create accurate, complex charts and scientific diagrams, part of a bid by the company to make its technology more appealing to professionals. ChatGPT Images 2.0 is set to roll out Tuesday through OpenAI's flagship chatbot and Codex AI coding assistant. The company said the product will be better at following a user's instructions when generating an image and will be able to include more details. It can also spit out visuals that more faithfully reflect a slew of styles and render text in multiple languages, the company said. The ChatGPT maker has moved to streamline its product offerings in recent weeks to compete for business customers against rival Anthropic PBC and pave the way for a possible initial public offering as soon as this year. As part of that effort, the company shuttered its Sora AI video generator. But OpenAI sees continued value in offering an AI image tool. In a briefing with reporters this week, Adele Li, who leads the product team for ChatGPT Images, said the functionality is "core" to what users want to do with AI. Hundreds of millions of weekly active ChatGPT users make images with the company's software, the company said, and more than 1 billion images are created each week with the chatbot. Li said OpenAI has made progress specifically on generating images that have structured layouts and complicated scientific diagrams in particular. These advances could lead to more practical uses of the technology by educators, scientists and parents, among others, she said. OpenAI's new image model can also spend more time computing before responding to a user, which the company said allows the software to find details online and ruminate more over how to construct an image. This feature will be available to paid users, the company said.
[7]
ChatGPT Images 2.0 is better at rendering non-Latin text
A little more than a year after OpenAI gave ChatGPT users the option to create images and designs directly from its chatbot, it's now releasing ChatGPT Images 2.0. OpenAI describes the new system as a "step change" for image generation models, particularly when it comes to the tool's ability to follow instructions in detail, render dense text and place and relate objects in a scene. For the first time, OpenAI has also built an image model with reasoning capabilities, giving the system the ability to do things like search the web and verify its outputs. According to the company, those capabilities should translate to a tool that's more reliable when accuracy, consistency and visual cohesion are essential. OpenAI says it has also put in a lot of work to make Images 2.0 better at understanding and rendering non-Latin text, with "significant gains" when it comes to the model's ability to handle Japanese, Korean, Chinese, Hindi and Bengali. At the same time, the company claims the new model is better at faithfully recreating the specific characteristics of different visual languages. On this point, OpenAI says that makes Images 2.0 more useful for tasks like game prototyping and storyboarding. Outside of those features, the new model is more flexible when it comes to aspect ratios, allowing it to generate images that are as wide as 3:1 and as tall as 1:3. It can also produce designs at resolutions of up to 2K, and even generate up to eight outputs in one go. I got a chance to preview Images 2.0 ahead of its public release. For my first prompt, I asked ChatGPT to generate an image of a tortoiseshell cat in the pixel art style of Pokémon's third generation. I thought this would be a good test because AI models typically struggle with pixel art, and the Game Boy Advance Pokémon games are iconic for their art style, so much so that if ChatGPT merely approximated that style, it wouldn't do. The result is the image you see above, and I think ChatGPT did a commendable job there. I then tasked the new model with converting that image into a transparent PNG. For one last test, I asked ChatGPT to create a four-page manga about my cat enjoying a sunny day by an idyllic city stream. Of those three tests, ChatGPT spent the most time on the second one and the output there was slightly different from the first image it generated, which I felt deviated from my prompt. Still, it managed to generate a proper transparent image, which is something other image models can struggle to do properly. Once more people have a chance to put the model through its paces, we'll have a better idea of how it compares to Google's Nano Banana 2, and where OpenAI can make additional improvements. Images 2.0 is available starting today for all ChatGPT users, including those on the company's Free and Go tiers. Plus and Pro subscribers get access to more advanced outputs. OpenAI is also making the model available through its API service and Codex coding app, which just last week it updated to offer built-in image generation. Notably, Images 2.0 arrives just days after Anthropic waded into the visual design market with its own design assistant.
[8]
OpenAI's new image model reasons before it draws
The new model reasons about composition, searches the web for context, generates up to eight coherent images from one prompt, and renders text in non-Latin scripts with near-flawless accuracy. It also took the number one spot on the Image Arena leaderboard within 12 hours of launch, by the largest margin ever recorded. Two years ago, asking ChatGPT to generate a visual was like commissioning a poster from a sleep-deprived intern with a glue stick and a head injury. You'd ask for a clean design and get "leftovers creativity" splashed across the image, plus three new words that looked like they'd been invented during a minor software malfunction. The images looked AI-generated in the way that has become a cultural shorthand for uncanny: almost right, conspicuously wrong, and instantly recognisable as synthetic. The leap matters. Text rendering has been the persistent, embarrassing weakness of AI image generators since DALL-E first turned heads in January 2021, a model we covered at the time as a fascinating curiosity. Images 2.0 claims approximately 99% accuracy in text rendering across any language and script, including Japanese, Korean, Chinese, Hindi, and Bengali. If that figure holds in independent testing, it closes the gap between "impressive AI demo" and "tool a graphic designer would actually use for production work." The architectural change that makes the model different, though not just better, is what OpenAI calls "thinking capabilities." Images 2.0 is the company's first image model to integrate its O-series reasoning architecture. Before generating a pixel, the model researches the prompt, plans the composition, reasons about spatial relationships between elements, and can search the web for real-time context. It is, in OpenAI's framing, not a rendering tool but a "visual thought partner." This is my cat transformed into a comic strip with ChatGPT. In practice, this manifests in two access modes. Instant mode ships to all ChatGPT users, including free-tier accounts, and delivers the core quality improvements: better text, sharper editing, richer layouts. Thinking mode, which enables web search, multi-image batching, and output verification, is restricted to Plus ($20/month), Pro ($200/month), Business, and Enterprise subscribers. The distinction is commercially significant. The reasoning capabilities, where most of the quality premium lives, sit behind the paywall. Free users get better images; paying users get images the model has thought about. The multi-image capability is the feature most likely to change professional workflows. A single prompt can now produce up to eight images that maintain character and object continuity across the set. That means a designer can generate a family of social media assets, a children's book sequence, or a series of storyboard frames from one instruction, with consistent visual identity throughout. Previously, each image had to be prompted individually and stitched together manually. For marketing teams and content creators, that is a meaningful reduction in production friction. The integration into Codex, OpenAI's coding environment, is the strategically loaded move. Developers and designers can now generate UI mockups, prototypes, and visual assets inside the same agentic workspace they use for code, slides, and browser automation, using a single ChatGPT subscription. The image model is no longer a standalone product; it is a capability embedded in OpenAI's broader platform, competing not just with Midjourney and Google's Nano Banana 2 on quality but with Canva and Figma on workflow integration. The benchmark performance is striking. Within 12 hours of launch, Images 2.0 took the number one spot on the Image Arena leaderboard across every category, with a score of 1,512, a +242-point lead over the second-place model, Google's Nano Banana 2. That is the largest lead ever recorded on the leaderboard. For most of 2026, OpenAI and Google had been trading the top position within a tight margin; Images 2.0 broke away decisively. DALL-E 2 and DALL-E 3 are being deprecated and retired on 12 May 2026. GPT-Image-1.5, released in December 2025 as an intermediate upgrade, remains accessible via the API for legacy integrations but is no longer the default model. OpenAI did not disclose the architecture of Images 2.0, describing it only as a "generalist model" or "GPT for images" and declining to specify whether it uses a diffusion, autoregressive, or hybrid approach. The API model identifier is gpt-image-2; the API is expected to open to developers in early May 2026. Token-based pricing is $8 per million tokens for image input, $2 for cached input, and $30 for image output, with per-image costs typically ranging from $0.04 to $0.35 depending on prompt complexity and resolution. Output resolution reaches up to 2K. The knowledge cutoff is December 2025, which introduces a practical boundary: the model cannot accurately render events, people, or products that emerged after that date without supplementing its internal knowledge with live web search. The model's safety architecture includes content filtering, C2PA metadata for provenance, and what OpenAI described in the press briefing as ongoing monitoring, a point the company was notably emphatic about, given the growing regulatory scrutiny of synthetic media and the use of AI image generators in deepfakes, scams, and non-consensual imagery. The most consequential question Images 2.0 raises is not about quality. The technical gap between AI-generated and human-created imagery has been narrowing for years; this model narrows it further. The question is about what happens when the tool is no longer a novelty but infrastructure, when image generation is a default capability of every coding environment, every chat interface, and every enterprise productivity suite, and when the distinction between "designed by a person" and "generated by a prompt" becomes something only metadata can verify. OpenAI, for its part, appears to be betting that the answer is scale: more images, faster, better, cheaper, everywhere. When we covered first covered DALL-E five years ago, the model's outputs were fascinating oddities. Now they are production assets. The era in which AI-generated images were obviously AI-generated is over. What comes next depends on whether the guardrails can keep pace with the capability.
[9]
OpenAI Unveils New Image Generator to Usher in an AI Slop 'Renaissance'
OpenAI just unveiled a brand new image generator that it claims can churn out smarter and more precise slop than ever before. ChatGPT Images 2.0 is going to be a "renaissance" in AI image generation, according to an introductory promo ad that ran before OpenAI's livestream on Tuesday announcing the news. "If we think of Dall-e as cave drawings, and Images 1.0 as ancient art, then Images 2.0 is the Renaissance," the ad claims. "Images 2.0 is a huge step forward; this is like going from GPT-3 to GPT-5 all at once," CEO Sam Altman said in the livestream. The company boasts new multilingual capabilities, better visual intelligence, and closer attention to detail with the new model, showcasing a prompt that generated an image of a bowl of rice in which only a single tiny grain has the name of the model on it. The model has two modes: instant and thinking. The researchers claimed both modes of the model are significantly better than previous image generation capabilities in ChatGPT, and that typos are "very rare." The instant mode is just a faster and revamped version of a typical image generator, it seems, and is available now to all ChatGPT and API users. The Thinking mode is more complex and only available to paid users, specifically subscribers to Plus, Pro, and Business. "When a thinking model is selected in ChatGPT, Images 2.0 can search the web for real-time information, create multiple distinct images from one prompt, and double-check its own outputs," OpenAI announced in a press release generated by Images 2.0 and made to look like a retro magazine spread. For example, Thinking mode can generate several pages of a manga comic "with recurring characters and evolving storylines" or entire magazine pages from a single simple prompt, the company said. Online sleuths were expecting this release for some time now. The model was dubbed "GPT-image-2" by enthusiasts on Reddit and X. Earlier this month, a Reddit user claimed OpenAI was testing the model with some ChatGPT users. Around the same time, one X user claimed that the model was already on third-party testing platforms like Arena AI under different code names like "maskingtape-alpha," "gaffertape-alpha," and "packingtape-alpha." On the livestream, OpenAI engineers confirmed that this was true. The X post that pointed it out includes pictures that the model allegedly produced, which mostly seem impressive, except for a world map with made-up countries like "Ciger" and "Mharee," and completely messed-up placement of capital cities, like locating the Kenyan capital of Nairobi in Saudi Arabia. OpenAI is preparing for an alleged IPO that is expected as early as this year. Ahead of that IPO, the company, which is still allegedly far from profitability despite mounting spending commitments, has been in the midst of a major effort to make its financials look as desirable as possible to potential investors. That has included shifting into a for-profit public benefit corporation and scrapping its video generator Sora to cut down on costs. If the new image generator model can capture the online success that the previous GPT-4o image generation grabbed with the "Studio Ghibli" craze a little over a year ago, it can help ChatGPT bump up its weekly active user numbers, another important point of consideration for investors. OpenAI announced in February that ChatGPT had breached 900 million weekly active users, and Images 2.0 could assist those numbers to reach the arbitrary but much more impressive-sounding 1 billion. This time around, it seems the viral moment they are hoping for is photorealism. When asked by Altman in the livestream, OpenAI researcher Gabriel Goh said that photorealism is the style he is most excited about in the model and that it "triggers something very interesting." Another battle OpenAI has to fight is over its reputation. OpenAI began the AI craze with the release of ChatGPT, a chatbot that has become not only a household name but also almost synonymous with the technology. But the company’s long-standing position as the leader of the AI race has started to face some serious competition. One of those blows came from OpenAI's chief rival, Anthropic, whose agentic models like Claude Cowork and Claude Code have been making OpenAI sweat. In response, OpenAI has been trying to fortify its rival offerings like Codex with updates. The other strike landed from Google. Late last year, the tech giant updated its viral image generator Nano Banana Pro and released Gemini 3, both to significant fanfare. Promptly following the stellar reception of Google’s releases, OpenAI declared “code red†at the company. The competition that OpenAI faces from both Google and Anthropic is so great that even Nvidia's CEO Jensen Huang, a key partner, is worried about OpenAI's market dominance, according to a Wall Street Journal report from earlier this year. If the image generator is successful, that might help quell some of those fears.
[10]
OpenAI unveiling ChatGPT Images 2 image generation model, watch live demo here - 9to5Mac
OpenAI is announcing its upgraded ChatGPT image generation model with ChatGPT Images 2. The company is also scaling up Codex for enterprise with a new Codex Labs initiative. After dropping a teaser this morning, OpenAI is announcing its new image generation model for ChatGPT and Codex with ChatGPT Images 2. Prior to the livestream, OpenAI used this image as a holding screen: Like this morning's teaser image showing a "screenshot" of macOS, this is likely another example of ChatGPT Images 2 being used. The focus appears to be on text generation, a key weak point with earlier ChatGPT image generation models. OpenAI has focused a lot on Codex in recent weeks as it aims to turn the Mac app for agentic coding into an AI "superapp" for builders of all types. Last week, Codex for Mac was overhauled with agentic computer use based on OpenAI's Sky Software acquisition, an in-app browser based on ChatGPT Atlas, and built-in image generation. The company has also released a separate feature called Chronicle that uses AI agents to use recent screen content to build better awareness for more prompt context. Now OpenAI is taking Codex further with a focus on enterprise adoption and a new Codex Labs program. Teams are using Codex to pull together context from different tools, reason through what matters, and turn scattered information into useful work - like briefs, plans, checklists, drafts, and follow-ups - and then take action. That creates a larger opportunity for enterprises to help every team move faster - not just the teams writing code. We want to help more enterprises do this. That is why we are launching Codex Labs. Codex Labs brings OpenAI experts directly into organizations to help teams put Codex to work on real problems. Through hands-on workshops and working sessions, enterprise orgs learn where Codex fits, how to integrate it into existing workflows, and how to move from early usage to repeatable deployment. The goal is simple: help enterprises get real value from Codex, faster. Companies wanting to scale Codex for enterprise can express interest with OpenAI here. Lastly, OpenAI has "polished" the ChatGPT widget on iPhone and iPad:
[11]
ChatGPT's new image model turned my article into handwriting
Images 2.0's improved text rendering opens practical applications for creating catalogs, storyboards, and detailed technical documentation with perfect textual accuracy. Image-generation models have a long history of bungling text. But while garbled letters used to be a clear AI tell, ChatGPT's new image-generation tool is the best I've ever seen at rendering text. I asked ChatGPT's Images 2.0 model (available now to all ChatGPT users, including those on the free tier) to take some text from a recent story of mine and render it in pencil on a yellow legal pad and, well, it looks pretty much perfect to me: I also prompted it to create an infographic about AI tokens, instructing it first to search the web for accurate information and to use a serif font in a landscape 3:2 aspect ratio. Here's what I got: Then I tasked Images 2.0 with creating another infographic, this time detailing the various Raspberry Pi models complete with specifications and other details: Finally, I asked the model to take a snapshot of me poolside and create a summer lookbook of outfits, starring me: OpenAI says Images 2.0 is its first image-generation model with "thinking" capabilities, meaning it can stop and ponder an image prompt before diving right in. When it comes to text, Images 2.0 supports a variety of languages, including Japanese, Korean, Chinese, Hindi, Bengali, and others that employ non-Latin text. It can also search the web for real-time information before rendering images, as well as create multiple images in one shot, good for rendering catalog images, comicbook-style panels, and storyboards. OpenAI promises that Images 2.0 will deliver an "unprecedented level of specificity and fidelity," meaning (hopefully) that it will do a better job at prompt adherence-that is, creating images that follow your prompts to the letter. With this level of accuracy, Images 2.0 could offer an answer to the question I've long asked about image-generating models: What are they good for, aside from creating goofy memes or creepy deepfakes? What's the actual, practical application? Near-instant typesetting, infographic creation, and catalog rendering could be some of the solutions, although fixing a typo would require completely re-rendering the image. It's also possible that the more you experiment with Images 2.0 (I've only been playing with it for an hour or so), the more the rendered images may look same-y, which is why you'd likely need a skilled human prompter with an eye for design at the helm.
[12]
ChatGPT just launched Images 2.0, and it finally fixes warped text
OpenAI has unveiled ChatGPT Images 2.0, a major overhaul to its image-generation capabilities that could make AI visuals far more useful for designers, marketers and everyday users. While earlier AI image tools often generated results with frustrating flaws such as warped text, poor layouts and vague prompt-following, OpenAI promises Images 2.0 is different. According to OpenAI, the new model delivers stronger instruction following, sharper text rendering, improved multilingual support and more control over composition, aspect ratio and visual consistency. In short: less "AI art experiment," more "usable design tool." Why this upgrade matters For many designers, AI image tools have been hard to trust for real work. Now, users can potentially create presentation slides, social media graphics, banners, posters and product mockups directly inside ChatGPT. OpenAI says Images 2.0 changes that by improving the exact pain points creative pros complain about most: * Better small text and typography * More accurate object placement * Cleaner layouts with whitespace and hierarchy * Stronger handling of posters, explainers and UI elements * More realistic styles and sharper consistency * Support for aspect ratios as wide as 3:1 and tall as 1:3 Designers may actually care this time The biggest shift may be intent. Instead of focusing only on surreal art or novelty images, OpenAI is positioning Images 2.0 as a strategic design system, which is something that can help carry a project from rough idea to finished asset. The company says the model can reason through layouts, use web information when a thinking model is selected and even generate up to eight related images at once with continuity across characters or objects. That could be valuable for ad campaign variations, storyboards, social media assets, comic sequences, product launches and multi-language marketing materials. In fact, one of the most notable improvements is support for non-English text rendering. OpenAI says Images 2.0 makes significant gains in Japanese, Korean, Chinese, Hindi and Bengali, helping generate visuals where language is part of the design rather than an afterthought. Bottom line OpenAI says ChatGPT Images 2.0 is rolling out now to all ChatGPT and Codex users. Advanced outputs powered by thinking models are reserved for Plus, Pro, Business and Enterprise users. The underlying gpt-image-2 model is also available through the API for developers. For the first time, this ChatGPT image upgrade feels as if its less about images going viral and more about getting actual work done. Users might find that Images 2.0 is the version that legitimatly supports creative workflow. Follow Tom's Guide on Google News and add us as a preferred source to get our up-to-date news, analysis, and reviews in your feeds.
[13]
'Not just generating images. It's thinking' -- ChatGPT Images 2.0 could fundamentally change how you make AI images
OpenAI's new model focuses on better interpretation of complex image prompts. * OpenAI has released ChatGPT Images 2.0 * The new AI image model improves on its predecessor with more accurate, structured, and consistent visuals * The update adds a reasoning step that helps the system better interpret complex prompts and brings ChatGPT closer to Gemini's multimodal strengths OpenAI has released a major update to ChatGPT's image generator. The company claims the new ChatGPT Images 2.0 is a shift in how the AI chatbot handles visual requests, moving from quick interpretation to something closer to deliberate construction. OpenAI CEO Sam Altman and his team, in a livestream announcement, pointed to how the images now behave more like answers, built from an understanding of what you asked rather than a loose approximation of it. "Images 2.0 is a huge step forward," Altman said. "It's like going from GPT-3 to GPT-5 all at once. Its ability to make extremely beautiful things is remarkable. The team really cooked with this one, and we can't wait to see what you'll do with it." The most immediate improvement shows up in places that used to break down. Text inside images is the obvious example. Posters, menus, slides, and anything that relies on words being legible has traditionally been unreliable. Letters would warp, spacing would drift, and meaning would get lost. It also handles structure more confidently. If you ask for a layout with specific elements in specific places, the result is more likely to reflect that intent. The model appears to treat the prompt less like a suggestion and more like a set of instructions. This shows up in smaller ways as well. Multiple images generated from the same idea tend to stay visually consistent, whether that means keeping a character recognizable or maintaining a shared style across a set. Pause before creation The bigger change is the reasoning step ChatGPT Images 2.0 adds before generation, allowing the model to work through a prompt before committing to a final output. In practice, this means it can break a request into parts, decide how those parts should fit together, and then produce an image that reflects that internal plan. It can also draw on additional context like uploaded files or other sources online. That means it takes a little longer to get the image, but it makes for a better result and presumably will save you time by not requiring repeated attempts. This is where image generation starts to resemble the behavior of advanced text models. The process is no longer purely reactive. It is interpretive. The output reflects a sequence of decisions rather than a single pass. That shift matters most when the request has multiple layers. A multi-part design or a narrative sequence benefits from the system's ability to hold those pieces together. Competitive visuals As the competition in multimodal AI heats up, OpenAI can now point to ChatGPT Images 2.0 as a stronger rival to Google Gemini. Gemini has focused heavily on connecting text, images, and context into a single system, connecting across digital ecosystems. It often looked better than ChatGPT's images in that contest. But ChatGPT Images 2.0 narrows that gap. Better reasoning, notably with text, means ChatGPT can muscle in on Gemini's strengths in structured, multimodal tasks. It doesn't make ChatGPT a clear winner, but it does put it closer to parity in more ways. Text models have already set a standard for fluid, context-aware responses. Bringing that same kind of reasoning into image generation starts to unify the experience. Whether you are writing something or visualizing it, the system is working from the same underlying understanding. That's where tools like ChatGPT and Gemini are clearly heading, and this update feels like a step that makes that convergence tangible. Ultimately, a reduction in friction and improvement in images is what most users care about. If ChatGPT Images 2.0 can stand out as the best option, Google might have more trouble enticing users to migrate or stay in its own AI bubble. Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button! And of course you can also follow TechRadar on TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.
[14]
OpenAI's ChatGPT Images 2.0 is here and it does multilingual text, full infographics, slides, maps, even manga -- seemingly flawlessly
It's been only a few months since OpenAI released its last big improvement to AI image generations in ChatGPT and through its application programming interface (API) -- namely, a new image generation model known as GPT-Image-1.5, released in December 2025, which brought about improved instruction following, colors, and lighting. Now, after weeks of testing, the company that kicked off the generative AI boom is unveiling a far more dramatic and even more impressive update: ChatGPT Images 2.0, which has been available not-so-secretly for several weeks on LM Arena AI, a third-party testing platform used by OpenAI and other major AI model providers to get early feedback, under the name "duct tape." Throughout that time, it's already blown early users' minds with its capacity to generate long blocks of text or disparate text panels within the same image, its insanely realistic generation of user interfaces and screenshots from popular websites and platforms, its reproduction of real life figures like OpenAI co-founder and CEO Sam Altman, and its ability to perform web research and put the results into the image itself. Now today, it's officially rolling out to ChatGPT users on all tiers, and OpenAI confirms it can also produce floor plans, image grids and sets of many smaller images, and character models from multiple angles, and apply almost all of these features to user-uploaded imagery as well. The update, which encompasses the new model for API users and a suite of "Thinking" features for ChatGPT subscribers, represents a fundamental shift in how the company views visual media. As the official release notes state, "Images are a language, not decoration. A good image does what a good sentence does -- it selects, arranges, and reveals". OpenAI did not release benchmarks to us ahead of time on ChatGPT Images 2.0, but it is safe to say the model is performing at the "state-of-the-art" based on all the outputs I've seen. The move comes as the AI image model space has seen increasing competition, especially with the release of Google's Nano Banana 2 image generation model (also known as Gemini 3 Pro Image or Gemini 3.1 Pro Image) in February 2026, which also offered dense text options "baked into" images similar to ChatGPT Images 2.0. But the latter's fidelity in reproducing user interfaces, screenshots, and multiple image packs at once seem to exceed even Google's latest image model's capabilities in my brief testing and anecdotal usage and observation of other users' images. OpenAI spokespersons and researchers re-iterated the company's commitments to safety and tagging its image outputs with metadata as AI generated in the face of rising reports -- including one recently from The New York Times -- on AI user-generated characters (AI UGC) being used as the seed for realistic AI videos posted en masse on social media as part of political influence campaigns, including showing support for historically unpopular U.S. President Donald J. Trump with an army of fictitious people masquerading as "real Americans." When VentureBeat asked in a closed press briefing directly about this story and GPT Images 2.0's potential for usage in deceptive campaigning or advertising/influence campaigns Adele Li, OpenAI's Product Lead for ChatGPT Images, responded: "We take safety and security incredibly seriously. That includes anything when it comes to political or election interference. And so while other platforms and companies may not have those safeguards, ChatGPT does, and we take monitoring and protection of our users, as well as the influence that our photos as they are created, incredibly seriously..in the last couple years, we've seen a lot more new entrants into the image generation space with different standards and philosophies as ChatGPT, but we've stayed steady through all that, and we're really proud of releasing this model as it relates to advanced capabilities, but doing so in a safe and protected way." OpenAI has also confirmed that it is deprecating GPT-Image-1.5 as the default model across its suite, though it will remain accessible via the API for legacy support. This transition signals OpenAI's confidence that the 2.0 model is a superior replacement for both casual and high-value creative tasks. The reasoning era of AI image generation The most significant technical advancement in Images 2.0 is the integration of OpenAI's "O-series" reasoning capabilities. Historically, image models have operated as black boxes: you provide a prompt, and a single output is generated. Images 2.0 introduces an "agentic" approach. When a user selects a "Thinking" model within ChatGPT, the system no longer simply "draws"; it researches, plans, and reasons through the structure of an image before the first pixel is rendered. During a live press briefing, Li demonstrated this reasoning by uploading a complex PowerPoint file regarding internal product strategies. Rather than merely creating a related image, the model synthesized the document's core data, identified the correct logos, and produced a professional poster that preserved the specific stylistic inputs of the original file. In my brief testing -- I was given access last night and tested it on a few generations this morning -- ChatGPT Images 2.0 is the first image model from OpenAI and one of only two (Nano Banana 2 being the other) that can seemingly accurately reproduce a map of the extent of the Aztec, Maya, and Inca empires at their respective heights along with a fully legible legend, making it useful for educational or internal training purposes on global knowledge and geography. This reasoning capability also allows the model to search the web in real-time to ensure visual accuracy for current events or specific technical artifacts. This is supported by a significantly more recent knowledge cutoff of December 2025, a major leap from previous iterations that struggled with modern context. The underlying architecture has been "revamped from scratch," according to Research Lead Boyuan Chen. While Chen declined to confirm if the model uses a traditional diffusion or auto-regressive technique, he described it as a "generalist model" or a "GPT for images" that can handle 3D-style perspective shifts and complex spatial reasoning through simple text prompts. Precision, multilingual support and a "wow" factor The product experience for Images 2.0 is defined by three major pillars: typography, linguistic diversity, and sequential consistency. One of the most persistent "tells" of AI-generated imagery has been the inability to render legible text. OpenAI claims Images 2.0 marks a "step change" in this department. The model is now capable of producing readable typography even in dense compositions, such as scientific diagrams, menus, or infographic posters. A look at the provided "Magazine Cover" sample (Open Scifi) illustrates this precision: every headline, volume number, and even the "Display until" date on the barcode is rendered with crisp, professional alignment that mirrors human-designed layouts. This capability extends into the "Thinking" mode, where the model can even generate three-page educational visuals -- complete with quizzes -- that maintain a consistent instructional flow. OpenAI has also addressed a long-standing Western bias in AI imagery. Images 2.0 is described as a "polyglot" model with significant gains in non-Latin script rendering. Specifically, the model now supports high-fidelity text generation in Japanese, Korean, Chinese, Hindi, and Bengali. In the "Global Language" diagram provided, which explains the water cycle, the model successfully renders complex Korean characters (Hangul) within an educational layout. The text is not just translated; it is "rendered correctly but with language that flows coherently," ensuring that labels and explanations feel natively integrated into the design. For creators working on storyboards or brand campaigns, the most impactful new feature is the ability to generate up to eight distinct images from a single prompt. Crucially, these images maintain "character and object continuity" across the series. Li noted that this solves a "cumbersome" workflow where users previously had to prompt one image at a time and manually stitch them together. This feature enables the creation of entire manga sequences, children's books, or a family of social media graphics that share the same visual DNA. Licensing and availability OpenAI's rollout strategy reflects a clear push toward professional and enterprise adoption. While the base model is available to all users -- including those on the free tier -- the advanced "Thinking" and "Pro" capabilities are reserved for paid tiers. * Free Users: Have access to the base ImageGen 2.0 model for standard tasks. * Plus and Pro Users: Can access "Thinking" capabilities, which include tool use, web search, and multi-image generation. * Pro Users: Receive additional access to "ImageGen Pro" models for more advanced image generation. * API Developers: Can integrate , which supports resolutions up to 4K (currently in beta) and flexible aspect ratios ranging from a wide 3:1 to a tall 1:3. What is clear so far is that OpenAI is describing three practical layers of access, even if it has not published a precise tier-by-tier matrix. The baseline is ChatGPT Images 2.0, which OpenAI's blog post states is available to all ChatGPT and Codex users and includes the core model improvements: better instruction following, stronger text rendering, multilingual gains, broader aspect ratios, and more polished, production-usable outputs. Above that is "thinking", which the release defines more concretely: when a thinking model is selected, the system can take more time, use the web, analyze uploaded materials, reason through layout before generating, and produce multiple distinct images at once, including up to eight coherent outputs with continuity. In the briefing, Li also framed thinking and Pro as "juiced-up" versions of the base model with tool use, and said these advanced modes are slower, not faster, because they do more reasoning and search behind the scenes. What remains unclear is the exact feature boundary between Thinking and Pro. The materials say Pro users get access to more advanced image generation, but they do not spell out whether that means higher quality, higher limits, higher resolution, more outputs, or some other advantage distinct from thinking itself. For enterprise users, the safest way to think about the differences is not as three totally separate products, but as a spectrum from fast default generation to slower, more agentic, more structured generation. If a team needs quick creative drafts, marketing concepts, simple graphics, or everyday image edits, the base Images 2.0 model appears to be the relevant default. If the task involves factual grounding, transforming internal documents into explainers, creating multi-image sets, or maintaining consistency across a sequence of assets, the more important distinction is whether the organization has access to thinking-enabled outputs. Until OpenAI provides a clearer Pro-versus-Thinking breakdown, enterprise buyers should treat "thinking" as the meaningful functional upgrade and treat "Pro" as a possibly higher-end access tier whose exact incremental benefits still need clarification before procurement or workflow planning. Safety standards OpenAI's says ChatGPT Images 2.0 offers a"multi-layered stack" of safety protocols, including: Li emphasized that while their philosophy is to "maximize user creativity," they maintain strict policies against election interference. What it means for enterprise users The shift from Images 1.5 to 2.0 is more than a resolution bump. By integrating reasoning, OpenAI is attempting to solve the "intent gap" that has plagued AI art since its inception. When you ask an AI for an "infographic about supply and demand," you aren't just looking for a picture; you are looking for a logical layout of information. The "Interior Design" sample (Japandi Furnishing Concept) highlights this systemic thinking. The model didn't just generate a room; it created a cohesive floor plan, a color palette, a list of materials, and "inspiration" shots that all adhere to a singular aesthetic. This is what OpenAI calls moving from a "tool" to a "visual system". However, this increased capability comes with a trade-off in speed. For the professional user, this is likely a worthwhile exchange: waiting an extra minute for a "production-ready asset" is still significantly faster than the hours required for manual design. As ChatGPT Images 2.0 rolls out, it marks the beginning of an era where AI doesn't just assist in making art, but in conducting "economically valuable creative tasks". Whether it can truly replace the intentionality of a human designer remains to be seen, but with 2K resolution, multilingual fluency, and the ability to "think" before it acts, OpenAI has certainly closed the distance.
[15]
ChatGPT's image generator is changing the rules - and I am not entirely comfortable
The latest image generator from OpenAI is undeniably powerful, and that much is hard to dispute. It interprets prompts with a level of depth that feels closer to collaboration than execution, renders clean and usable text within images, and produces outputs that look less like drafts and more like finished products. But the real shift is not visual quality. It is conceptual. This tool is not just improving how images are made; it is quietly redefining what creative control looks like in an AI-assisted workflow. And that shift, while impressive, is not entirely comfortable. From Tool To Decision-Maker In A Changing Competitive Landscape What separates ChatGPT's image generator from most competitors is its reasoning layer. Instead of simply translating prompts into visuals, it interprets intent, fills in missing context, and makes decisions before generating the final output. This allows it to handle complex, multi-step prompts and even maintain consistency across multiple images in a way that feels far more structured than traditional systems. Recommended Videos That puts it ahead of platforms like Midjourney and Stable Diffusion, which still rely heavily on precise prompting and iterative trial-and-error. But that advantage comes with a subtle trade-off. As the system takes on more decision-making, the user's direct control begins to shrink. Creativity becomes less about crafting and more about guiding. At the same time, the competition is evolving in different directions. Google's Gemini-powered Nano Banana has emerged as a serious challenger, focusing on speed and consistency rather than reasoning depth. It can generate images in seconds, maintain subject continuity across edits, and combine multiple visual inputs seamlessly. Its rapid adoption and viral usage trends suggest that efficiency and accessibility are resonating strongly with users. Meanwhile, Midjourney continues to dominate in artistic expression, producing images with strong stylistic identity, mood, and visual storytelling. It remains the preferred tool for creators who prioritise aesthetics over structure. Anthropic's Claude, while not a direct image-generation competitor, is carving out relevance through structured workflows and design-oriented outputs, focusing more on how visuals are conceptualised than how they are rendered. The result is a fragmented but mature market. The question is no longer which tool is best overall, but which tool fits a specific purpose. ChatGPT leads in versatility, but that leadership comes from balance rather than dominance. The Text Breakthrough And The Uneasy Reality Of Realism One of ChatGPT's most significant technical achievements is its ability to render accurate, usable text within images. This has long been a weak point for AI image generators, with distorted typography often limiting real-world applications. By solving this, ChatGPT has unlocked new use cases in marketing, design, and communication, where precision matters as much as aesthetics. However, this breakthrough has also exposed a more uncomfortable reality. A tweet highlighted a viral AI-generated cheque for ₹69,000 that appeared convincingly real, complete with structured banking details. The image sparked immediate concerns around fraud, with users pointing out how easily such visuals could be misused despite lacking physical security features. Oh, and the image was made with ChatGPT 2.0. This incident illustrates a broader tension. The same capability that enables better design also enables more believable deception. As AI-generated visuals become more functional and realistic, the line between creative output and potential misuse becomes increasingly blurred. Photorealism plays a central role in this shift. ChatGPT excels at producing commercially usable visuals such as product shots, advertisements, and UI mockups. Nano Banana competes closely in this space, often outperforming in speed and consistency, while Midjourney continues to lead in artistic imagination. This creates a clear divide between tools optimised for usability and those designed for expression. Also, comparing GPT Image 2 with Nano Banana 2 makes one thing clear: they are optimised for very different kinds of output. GPT Image 2 excels in structured, usable visuals where precision matters. Its text rendering is nearly flawless, making infographics, UI mockups, and product shots look polished and production-ready, while its hyper-realism pushes images close to photographic quality - sometimes uncomfortably so. However, it still struggles when scenes require believable physics or motion, where objects can feel slightly off. Nano Banana 2, on the other hand, handles these dynamic elements better, producing more natural movement, cinematic lighting, and skin textures that feel less synthetic. It also enables faster iteration when generating multiple variations quickly. In practical terms, GPT Image 2 feels like a design tool, while Nano Banana 2 behaves more like a creative engine, prioritising visual feel over structural perfection. In the two images above, we gave the prompt - "make a fire engine parked outside the Avengers Tower" - and looking at the images, the Nano Banana one seems more realistic while the ChatGPT one feels more, you could say, wallpaper worthy. Gemini has actually taken the liberty of putting a "Heroes Welcome" sign on the entrance of the building on a busy NY street. While the ChatGPT one has followed the instructions to the T. It's just a fire engine standing in front of the Avengers Tower. That is it. Convenience, Control, And The Future Of Creativity Perhaps the most transformative aspect of ChatGPT's image generator is its workflow. Conversational editing allows users to refine images iteratively using natural language, eliminating the need to start over with each change. This makes the process faster, more intuitive, and significantly more accessible. Compared to the friction of prompt engineering in Midjourney or the technical complexity of Stable Diffusion pipelines, this approach feels like a leap forward. But it also changes how creative ideas are formed. When iteration becomes effortless, the process risks becoming reactive rather than intentional. Instead of carefully crafting a vision, users may find themselves adjusting outputs until something works. This is where the broader question emerges. ChatGPT offers the most complete package in the current landscape, combining reasoning, usability, text accuracy, and integration into a single system. It performs consistently well across multiple use cases, which is why it is increasingly seen as the default choice for general users. Yet that "overall" strength hides an important nuance. Nano Banana is faster and often more consistent. Midjourney remains more artistic. Claude is more structured. Stable Diffusion offers deeper customisation. ChatGPT does not dominate any single category outright, but it succeeds by being good at everything. That shift reflects a larger change in how tools are chosen. The decision is no longer driven by creative identity, but by efficiency and practicality. While that represents progress in accessibility and capability, it also suggests a quieter transformation. Creativity is becoming less about expression and more about optimisation.
[16]
ChatGPT's Latest Update Makes It Harder Than Ever to Spot AI-Generated Images
Text in particular is frighteningly accurate, with a level of detail that will likely fool many people who can easily spot AI images. AI-generated images are getting harder and harder to spot. There are the usual tells, of course, but those tells are minimizing with each new AI image model. You could count on AI-generated hands including too many or too few fingers on people, for example; nowadays, that's not necessarily the case. One particular area of weakness for AI image models has been text generation. The image itself might look convincing, but take a close look at the words, and you'll often notice they're not really right. Maybe some are accurate, while others are pretty close, but, in many cases, you'll notice a lot of inconsistencies: Too many repeating letters, letters that aren't really letters, characters that blend and squiggle in and out of one another. A lot of these quirks remind me of how Star Wars' language looks, at least when AI is trying to replicate American English. But the latest AI models are getting much better with text generation. In fact, OpenAI's latest model for ChatGPT, Images 2.0, can render highly realistic text, and a lot of it -- to the point where I'm not sure many of us (or any of us) will be able to spot it. According to OpenAI, Images 2.0 is the company's first image model with thinking capabilities: That means the model can take its time breaking down each step of a request, which may generate more detailed or accurate images, as well as the ability to generate up to eight images from one prompt (though this is only available for paid subscribers). Free users can still take advantage of Images 2.0 perks, like how it searches the web for information and double-checks its work. The company says that "results feel less AI-generated and more intentionally designed," which essentially means images generated using ChatGPT are going to be much more difficult to spot going forward. The company seems very confident in this latest model. It touts the number of different types of images it can create -- not just photorealistic pictures, but screenshots of a computer's UI, a magazine collage, a mound of rice (that's a lot to generate), a magazine page, and a handwritten essay. They mean handwritten, too, down to a coffee stain on the paper. You can scroll through these examples on OpenAI's official announcement post to see how shockingly realistic they are. The post includes other examples, like highly realistic photographs, graphic novel pages, movie posters, and images with different aspect ratios -- down to the iPhone's panorama view. All of these developments are as impressive as they are distressing, but for me, it's the improvements to text that really take this to another level. Many models are getting quite good at generating images that trick users into thinking they're real, but the level of detail in text and writing on these examples is something I haven't yet seen. I asked ChatGPT to generate me a menu for an Italian restaurant, highlighting five dinner courses and two desserts -- I left the specific dishes up to the AI's discretion. It managed to generate something realistic, with dinner and dessert entries without mistakes -- as far as I could tell. I then asked it to generate a newspaper entry announcing that the Red Sox and Yankees would be switching cities. It did that too, again without any obvious mistakes. I'm not saying these images are perfect: They still have an AI "sheen" to them, that a trained eye or close observer would be able to notice. OpenAI says that Images 2.0 struggles with certain complex task, like puzzles, as well as details found on hidden or oddly placed areas, like reversed surfaces. But none of that really matters when the images this model produces are impressive enough to fool most people who scroll past them. Infographics, photographs, maps, comics, movie posters, you name it: People are going to be using this tool, and you're going to start seeing a lot more AI images in your life -- often without ever knowing it.
[17]
OpenAI launches ChatGPT Images 2.0, Codex Labs developer training service - SiliconANGLE
OpenAI launches ChatGPT Images 2.0, Codex Labs developer training service OpenAI Group PBC today launched ChatGPT Images 2.0, an upgraded version of the image generator built into its popular chatbot. The company also debuted a new technical training service called Codex Labs. It's designed to help organizations adopt OpenAI's Codex programming assistant. ChatGPT Images 2.0 can generate images with a maximum width of 2,000 pixels in multiple aspect ratios, including some that weren't supported until now. Notably, users can now generate images that are up to three up as wide as they are tall or vice versa. Such aspect ratios lend themselves to use cases such as designing infographics. OpenAI says that ChatGPT Images 2.0 brings significant improvements in image quality. One of the areas where the company's researchers made upgrades is text rendering. ChatGPT Images 2.0 is better than its predecessor at generating images that contain Japanese, Korean, Chinese, Hindi and Bengali text. OpenAI has also made quality improvements in other areas. The company says that its new image generator is better at generating small text, interface elements, icons and other visual assets that historically posed a challenge for artificial intelligence models. Furthermore, ChatGPT Images 2.0 renders images with "tiny flaws that add realism." The tool uses a built-in general knowledge dataset to interpret prompts and fill information gaps. For example, it could generate an infographic that explains how to prepare a user-specified dish even if the user didn't list the dish's ingredients. OpenAI says that ChatGPT Images 2.0's dataset was last updated in December. Users with paid plans can expand the tool's knowledge base by activating ChatGPT's "thinking" and "pro" reasoning modes. The two settings enable ChatGPT Images 2.0 to round out the information at its disposal with data from the public web. In one demo, OpenAI engineers asked the tool to review the company's e-commerce store and generate an ad for the items currently in stock. The AI provider says that the two reasoning modes also boost the quality of outputted images. They do so by enabling ChatGPT Images 2.0 to "reason through the structure" of a visual asset before generating it. That lowers the risk of output errors, which in turn reduces the number of manual revisions needed to prepare an image. ChatGPT Images 2.0 also saves time for users in other ways. It can generate up to 10 images based on a single prompt, which removes the need to enter multiple sets of instructions. The tool can maintain a consistent look across the visual batches in a batch or apply different design styles. OpenAI launched ChatGPT Images 2.0 alongside a new enterprise offering called Codex Labs. It's designed to help organizations deploy the AI provider's Codex programming assistant. According to OpenAI, the offering provides access to workshops and other training that can make it easier for a company's developers to adopt the tool. In addition, Codex Labs will help enterprises with tasks such as connecting Codex to their existing developer tools.
[18]
ChatGPT Images 2.0 is here, and it's way more than an upgrade
OpenAI is back with another upgrade to ChatGPT's image capabilities, and this one feels less like a gimmick and more like a serious step toward making AI visuals actually useful. OpenAI has officially introduced ChatGPT Images 2.0, a new image generation system that leans heavily into reasoning and accuracy. ChatGPT Images 2.0 focuses on understanding, not just generating Instead of blindly turning prompts into visuals, the model now takes a more deliberate approach, essentially "thinking" through what you're asking before generating the image. That shift shows up in a few key ways. The model is far better at handling complex prompts, can maintain consistency across multiple outputs, and is noticeably more reliable when it comes to placing text inside images, which is something earlier AI tools famously struggled with. Furthermore, it can also generate multiple variations from a single prompt while keeping the core idea intact, which makes it far more useful for iterative work. The result is a system that feels less like an AI art generator and more like a tool that actually understands what you're trying to create. This is where AI images start becoming practical What makes this update interesting is the direction OpenAI is taking. This isn't about chasing viral AI art anymore, but also about making image generation usable in real-world scenarios. With improved text rendering, better structure, and more predictable outputs, ChatGPT Images 2.0 starts to make sense for things like presentations, social media creatives, or quick design mockups. It's still not a full replacement for professional tools, but it's getting close enough to handle a surprising amount of everyday creative work. Recommended Videos That said, it's not perfect. There are still occasional inconsistencies, especially with more complex layouts or non-English text. But compared to where things were even a year ago, the progress is hard to ignore. And if this trend continues, the line between "AI-generated" and "actually usable" visuals is going to get thinner very quickly. ChatGPT Images 2.0 is available starting today to all ChatGPT and Codex users, with advanced outputs using Thinking available to Plus, Pro, Business, and Enterprise users. The underlying model, gpt-image-2, is also available in the API.
[19]
OpenAI launches ChatGPT Images 2.0 with reasoning-driven visuals
OpenAI has officially launched ChatGPT Images 2.0, featuring substantial enhancements in AI image generation capabilities. This release follows extensive testing under the name "duct tape" on LM Arena AI, allowing users to create complex images that include long text blocks, user interfaces, and even floor plans. The new model, which incorporates the gpt-image-2 architecture and "Thinking" features for ChatGPT subscribers, marks a significant shift in OpenAI's approach to visual media. OpenAI emphasized, "Images are a language, not decoration," highlighting a move toward viewing images as functional tools rather than mere visual elements. While specific benchmarks were not disclosed, OpenAI claims ChatGPT Images 2.0 operates at "state-of-the-art" levels. This release comes amid increasing competition from Google's Nano Banana 2 model, which debuted in February 2026. Early testing suggests that ChatGPT Images 2.0 can generate user interfaces and image packs with higher fidelity than its competitors. OpenAI is deprecating GPT-Image-1.5 as the default model but will keep it available via the API. This indicates confidence in the new model's capabilities for both casual and high-value tasks. ChatGPT Images 2.0 now integrates OpenAI's "O-series" reasoning, allowing the model to research and plan before generating images. During demonstrations, the model effectively produced high-quality educational materials, including maps of ancient empires with detailed legends. This functionality aims to support users in creating informative and visually accurate content. Improvements in typography enable the model to produce legible text even in intricate designs. Additionally, ChatGPT Images 2.0 supports generating images in multiple languages, addressing a historical bias in AI-generated imagery. Users can now create up to eight coherent images from a single prompt, maintaining consistency and continuity among the generated outputs. The rollout includes a tier-based access structure: free users can utilize base features, while Plus and Pro subscribers gain access to advanced capabilities, including web search and multi-image generation. API pricing has decreased, with costs set at $8.00 for image generation outputs. OpenAI has implemented a "multi-layered stack" of safety protocols to ensure the responsible use of AI-generated images, including watermarking and content filtering. In response to inquiries regarding potential misuse, OpenAI stated it takes safety measures regarding political influence and advertising campaigns seriously. As ChatGPT Images 2.0 transitions into active use, it aims to redefine the interaction between visual generation and user intent through enhanced reasoning and contextual understanding. OpenAI's objective is to assist users in executing economically valuable creative tasks while balancing speed and quality.
[20]
OpenAI's New Image-Generation Model Could Be Your Next Creative Director
After killing video generation app Sora, OpenAI is renewing its commitment to image generation with a new and improved AI model. OpenAI has announced ChatGPT Images 2.0, its most powerful image generation model yet. The company says that unlike earlier models, ChatGPT Images 2.0 is a thinking model, capable of researching a subject and working through multiple iterations before generating a final design. In a live-streamed presentation, OpenAI CEO and cofounder Sam Altman described the new model as representing a massive leap in quality over ChatGPT's original image-gen model, which led to a viral explosion of AI-generated images when it was released last spring. ChatGPT Images 2.0 comes in an "instant" mode and a "thinking" mode. Kenji Hata, a technical staffer at OpenAI, said that the thinking mode is particularly useful when generating images that need to have a lot of specific data and information. According to Hata, the thinking mode enables the model to "double check" its work, search the internet, and even generate working QR codes.
[21]
OpenAI's ChatGPT Images 2.0 Brings Better Accuracy, Multilingual Text Support
The model is accessible to users through ChatGPT, Codex, and API OpenAI on Tuesday launched its next-generation image generation model. Dubbed ChatGPT Images 2.0, it is claimed to deliver more precise, usable, and context-aware images, based on prompts entered by the user. The new model introduces improvements in instruction following, multilingual rendering, and composition. The San Francisco-based artificial intelligence (AI) giant says it also adds reasoning capabilities for more complex tasks. ChatGPT Images 2.0 is being rolled out across ChatGPT, Codex, and the API. Images 2.0 Availability ChatGPT Images 2.0 is available starting Tuesday to all users across ChatGPT and Codex, as per OpenAI. Advanced capabilities, including reasoning-backed thinking features, are accessible to ChatGPT Plus, Pro, and Business subscribers. Developers can access the model through the gpt-image-2 API. Pricing, however, will vary based on the selected image quality and resolution. The company claims its new model supports outputs of up to 2K resolution, although higher-resolution outputs are still in the beta phase. ChatGPT Images 2.0 Features, Capabilities According to OpenAI, ChatGPT Images 2.0 offers greater precision and control than the previous-generation model, which allows users to generate visuals that closely match detailed prompts. It is claimed to be designed to handle complex compositions. This includes UI elements, dense text, and structured layouts, which the AI firm says were previously challenging for image generation systems. A notable upgrade is in terms of multilingual support. It can render non-English text more accurately, covering languages like Hindi, Bengali, Chinese, Japanese, and Korean. Consequently, users can create visuals like posters, diagrams, and infographics in the aforementioned languages, where language is an integral part of the design. As per the company, ChatGPT Images 2.0 also delivers better consistency across styles, including photorealistic images, cinematic visuals, pixel art, and manga. There are improvements on the lighting, texture, and composition fronts, too. The latest image-generation model also supports flexible aspect ratios, from ultra-wide formats (3:1) to tall layouts (1:3). With ChatGPT Images 2.0, OpenAI has also introduced thinking capabilities. As described by the AI firm, this allows the model to carry out more advanced reasoning tasks than before. It can be paired with a reasoning-enabled ChatGPT model, enabling it to search the web for real-time information, verify outputs, and generate images -- all from a single prompt. It has an updated knowledge cutoff of December 2025. OpenAI claims the model can generate up to eight coherent outputs simultaneously, while maintaining consistency across characters, objects, and other elements. The company has positioned ChatGPT Images 2.0 for a wide range of use cases. This includes design prototyping, marketing creatives, educational content, and product development. It is claimed to be able to synthesise information, structure visuals, and present them with clear layouts. The company, however, notes that while Images 2.0 is a significant improvement, it is not without limitations. It can struggle with tasks requiring a highly accurate physical understanding, such as complex puzzles, origami instructions, or objects viewed from awkward angles. It may also face challenges with very dense or repetitive visual details. Further, there could also be instances where outputs such as diagrams or labelled illustrations require manual verification for accuracy. Higher-resolution outputs beyond 2K are still in beta and may not always be consistent as well.
[22]
OpenAI nears launch of new image model to replace DALL-E
OpenAI is nearing the launch of a new image generation model believed to be GPT Image 2, which will produce more realistic visuals and cleaner text. This follows weeks of leaks and community testing, as reported by The Information. The model has been spotted in testing on platforms including LM Arena and Reddit, indicating its potential impact on the competitive landscape for AI image generation. The anticipated release of GPT Image 2 comes as OpenAI plans to shut down DALL-E 2 and DALL-E 3 on May 12, creating urgency for a successor. The new model is expected to represent a direct challenge to Google and Adobe, both of which have integrated their own image models into existing applications. On April 4, three anonymous image models appeared on LM Arena under codenames: maskingtape-alpha, gaffertape-alpha, and packingtape-alpha. Although these models were pulled shortly after their appearance, screenshots circulated on Reddit and within developer communities. Early testers reported that the new model offers near-perfect text rendering and native 4K resolution support. Sources indicate that GPT Image 2 utilizes an entirely new architecture, moving away from the GPT-4o image pipeline. It is anticipated to shift from a two-stage inference to a single-pass generation, which could yield both quality enhancements and faster rendering times. By April 14, the models made a reappearance on LM Arena, and some ChatGPT users reported an improved image generator during apparent A/B testing. The competitive pressure is intensifying as Adobe has successfully integrated OpenAI and Google image models into its Firefly app, which features its own models, Firefly 4 and 4 Ultra. Additionally, Google's Nano Banana Pro has established a new benchmark for photorealism. OpenAI has not officially confirmed plans for GPT Image 2 or a release date. Analysts predict the model could be launched between late April and mid-May 2026, possibly alongside a GPT-5.4 update. "The competition is shifting from simple image generation to high-utility, multimodal intelligence," one industry analyst remarked, noting that advancements are expected to become "faster and cheaper throughout 2026."
[23]
How ChatGPT Images 2.0 is Turns Static Designs Into Cinematic Videos
GPT Images 2.0 is a new system for AI-generated visuals that emphasizes precision and adaptability across diverse applications. According to David Ondrej, it allows users to develop initial ideas into polished visuals for purposes like cinematic storytelling, marketing campaigns and educational materials. A standout feature is its capacity to produce hyper-realistic outputs in styles ranging from historical recreations to modern designs, making it accessible to both seasoned creators and beginners. Explore how GPT Images 2.0 integrates with frameworks like SeaDance 2.0 to create animated sequences from static visuals. Gain insight into practical approaches for prompt engineering, including the use of detailed instructions and reference images to achieve specific results. Additionally, learn how external resources such as Higgsfield presets provide ready-made options to streamline workflows and reduce costs for creative projects. GPT Images 2.0 stands out for its ability to produce hyper-realistic images and videos while offering unparalleled flexibility in visual styles. Whether you're envisioning cinematic drama, historical aesthetics, or sleek modern designs, this tool adapts seamlessly to your creative vision. Key features include: This versatility makes GPT Images 2.0 an indispensable tool for creators aiming to elevate their content while maintaining full creative control. Its ability to adapt to various styles and requirements ensures that it meets the needs of both individual creators and collaborative teams. Achieving optimal results with GPT Images 2.0 requires a strong understanding of prompt engineering. This process involves crafting detailed and precise instructions to guide the AI effectively, making sure that the output aligns with your creative goals. A well-structured prompt can significantly enhance the quality and relevance of the generated visuals. To refine your prompts: By combining clear instructions with visual references, you can guide GPT Images 2.0 to produce cohesive and high-quality outputs. This approach is particularly effective for complex designs or multi-scene projects, where consistency and attention to detail are paramount. Discover other guides from our vast content that could be of interest on GPT Images 2.0. GPT Images 2.0 extends beyond static visuals, serving as a foundation for video creation. The typical workflow begins with generating a base image, which can then be animated using tools like SeaDance 2.0. These animations introduce dynamic elements, transitions and movement, transforming static visuals into engaging video content. To ensure consistency across multi-scene videos: This workflow is ideal for creating promotional videos, cinematic mini-movies, or any project requiring a polished, professional touch. By combining the strengths of GPT Images 2.0 with animation tools, creators can produce visually stunning and emotionally impactful content. The adaptability of GPT Images 2.0 makes it suitable for a wide range of creative projects. Its applications span multiple industries, offering solutions for both personal and professional use cases. Common applications include: Whether you're an independent creator or part of a larger team, GPT Images 2.0 provides the tools to produce professional-grade content efficiently. Its ability to adapt to various styles and formats ensures that it meets the diverse needs of creators across industries. The integration of GPT Images 2.0 with platforms like Higgsfield further expands its capabilities, offering a streamlined and cost-effective approach to content creation. Higgsfield combines multiple AI models to enhance the image and video generation process, providing features such as: This integration democratizes content creation, allowing both experienced professionals and newcomers to produce high-quality visuals and videos. By using the combined power of GPT Images 2.0 and Higgsfield, creators can achieve results that rival traditional methods in both quality and efficiency. For those new to AI-driven content creation, GPT Images 2.0 offers an intuitive starting point. To make the most of this powerful tool, consider the following tips: By following these steps, beginners can quickly learn the basics and unlock the full potential of GPT Images 2.0. Its user-friendly interface and robust features make it an excellent choice for those looking to explore AI-powered content creation. GPT Images 2.0 represents a significant advancement in AI-powered content creation, offering tools that cater to a wide range of creative needs. Its ability to produce realistic visuals, adapt to diverse styles and integrate seamlessly with platforms like Higgsfield makes it a valuable asset for creators of all skill levels. By mastering techniques such as prompt engineering and using its advanced features, users can create high-quality images and videos that rival traditional methods in both quality and efficiency. Whether your focus is on social media, advertising, or entertainment, GPT Images 2.0 provides a versatile and accessible solution to meet your creative goals. Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Geeky Gadgets may earn an affiliate commission. Learn about our Disclosure Policy.
[24]
A revolution in a single image: ChatGPT's new model changes the rules
Example of the new graphics output. More working time, greater text accuracy. The AI that draws like a human: OpenAI introduced the new graphic model of ChatGPT, Images 2.0, marking a technological leap that almost completely blurs the line between human creation and computer-generated content. Until two years ago, AI-generated images could be identified by embarrassing mistakes, mainly in distorted text or small details, but now this is a system capable of producing outputs that look ready for immediate use, from advertisements to restaurant menus, without raising suspicion. However, in Hebrew the system still struggles and produces awkward errors. One of the main challenges of image generators in the past was the ability to integrate text. Systems like DALL-E tended to produce meaningless or incorrect words, a result of a technological method called diffusion, in which an image is gradually built from noise. In this method, small areas such as letters received less attention and therefore suffered in quality. The new model presents a dramatic improvement in this area, to the point of generating clear and accurate text within images, even in complex languages. But as mentioned, not yet in Hebrew. OpenAI has not fully disclosed the exact mechanism behind the model, but hinted at a combination of reasoning capabilities similar to language models. This means the system not only 'draws,' but also plans the image in advance, understands the context, and sometimes even checks itself before presenting the result. One of the key innovations is an operating mode called Thinking, in which the model works more slowly but in a more accurate and in-depth manner. In this mode, it can create a consistent series of images from the same prompt, maintain characters, style, and objects across different frames, and produce outputs such as multi-image comics or a complete storyboard. This capability changes the way professionals can work. Instead of relying on multiple tools for design, writing, and editing, an entire campaign can be generated from a single prompt. The model can create different versions of the same content, adapt sizes for various platforms, and produce outputs ready for immediate use on social networks, websites, or applications. At the same time, the model also shows significant improvement in understanding non-Latin languages. In the past, writing in Japanese, Korean, or Hindi within an image was almost impossible. Now, the system can integrate text in these languages much more accurately, expanding its usability for global markets. The image quality itself has increased to a resolution of up to 2K, with the ability to handle complex compositions, small details, and subtle stylistic constraints. This is an improvement not only in accuracy but also in control: The user can guide the model in detail and receive a result that adheres much more closely to the instructions than before. However, this is not a perfect system. Even in the new version there are limitations, especially in tasks that require precise physical understanding of the world, such as folding origami or complex representations of three-dimensional objects. Repeated edits of the same image can also sometimes lead to a decline in quality, a phenomenon known from previous models as well. Another aspect is speed. Creating complex images is not as immediate as writing text, and sometimes several minutes are required to obtain a complete result. But compared to the capabilities achieved, this is still relatively fast. The launch of Images 2.0 comes amid increasing competition in the field, as other technology companies invest enormous resources in developing similar models. At the same time, OpenAI is gradually phasing out older models and focusing development on the new generation, illustrating just how rapidly the field is evolving.
[25]
How ChatGPT Image 2 is Quietly Restructuring Creative Teams
OpenAI's ChatGPT Image 2 is pushing the boundaries of AI-driven image generation, introducing features that could significantly alter team dynamics and workflows. Nate Jones explores how this technology, with its ability to produce reasoning-based outputs and maintain multi-frame consistency, is reshaping roles across industries. For instance, GPT Image 2 can generate culturally tailored ad campaigns or detailed UI mockups directly from text prompts, reducing reliance on traditional design processes. With a 93% success rate in blind comparisons, it challenges conventional approaches and compels teams to rethink how they allocate resources and expertise. In this analysis, you'll gain insight into how ChatGPT Image 2's live web search integration ensures real-time relevance in visual outputs and how its self-verification systems enhance accuracy. Discover how these features enable marketing teams to localize campaigns faster, empower designers to focus on strategic briefs and allow engineers to integrate image generation seamlessly into broader workflows. The discussion also addresses the ethical and practical limitations of this technology, highlighting the importance of human oversight in maintaining quality and mitigating risks. What Makes GPT Image 2 Unique? GPT Image 2 introduces new features that expand the boundaries of AI's potential in image generation. These innovations include: * Reasoning-Based Outputs: A "thinking mode" that creates images aligned with intricate and nuanced prompts. * Live Web Search Integration: Ensures outputs are accurate and contextually relevant by using real-time data. * Self-Verification Systems: Reduces errors by validating generated content before delivery. * Multi-Frame Consistency: Generates up to eight coherent frames per prompt, maintaining uniformity in style and narrative. These features make ChatGPT Image 2 a versatile tool for diverse applications, from creative design to operational workflows. For example, it can produce culturally accurate localized ad campaigns or generate detailed UI mockups from natural language descriptions. Additionally, its real-time data visualization capabilities enhance its utility, allowing dynamic updates for marketing strategies and competitive analysis. Transforming Workflows with GPT Image 2 The advanced capabilities of GPT Image 2 streamline processes, reducing manual intervention and allowing innovative workflows. Here are some practical applications: * Localized Ad Campaigns: Automatically create culturally nuanced designs with precise translations. * UI Mockups: Generate user interface designs directly from text prompts, bypassing traditional wireframing tools. * Real-Time Data Visualizations: Develop dynamic charts and graphs for marketing and competitive analysis. * Comprehensive Design Systems: Produce cohesive outputs, such as floor plans or color palettes, from a single prompt. By shifting the focus from manual execution to strategic specification, GPT Image 2 enables teams to prioritize high-level planning and quality assurance over repetitive design tasks. This shift not only enhances efficiency but also fosters creativity by freeing up resources for more strategic initiatives. Below are more guides on ChatGPT from our extensive range of articles. Addressing Limitations and Risks Despite its impressive capabilities, ChatGPT Image 2 has certain limitations that require attention. These include: * Challenges in iterative editing for refining outputs. * Difficulty modeling complex physical environments with high accuracy. * Limited effectiveness in handling dense tabular data. Human oversight remains essential to ensure the accuracy and quality of final outputs. Additionally, the model's ability to generate convincing forgeries, such as fake receipts or IDs, raises ethical concerns. This poses risks in areas like journalism, legal systems and fraud prevention. Current watermarking and content verification methods are insufficient, underscoring the need for more robust safeguards to mitigate potential misuse. Comparing GPT Image 2 to Anthropic's Claude Design While GPT Image 2 excels in generating pixel-based visual assets, Anthropic's Claude Design focuses on creating editable HTML for interactive prototypes. Both models streamline workflows by integrating research, copywriting and layout into a unified process. However, their distinct strengths make them complementary tools rather than direct competitors. ChatGPT Image 2 is ideal for static visual content, while Claude Design caters to dynamic, interactive design needs. Together, they offer a comprehensive solution for modern design and development challenges. Redefining Team Roles GPT Image 2 is reshaping roles across various teams, emphasizing the importance of strategic oversight and clear specifications. Here's how it impacts different groups: * Product Teams: Integrate UI specifications directly into coding workflows, minimizing intermediate steps. * Design Teams: Shift focus to briefs, brand systems and quality assurance rather than manual execution. * Engineering Teams: Treat image generation as a callable subroutine within broader workflows. * Marketing Teams: Use multilingual rendering for faster, more accurate campaign localization. * Founders and Solo Operators: Scale creative operations with minimal resources, allowing rapid growth. * Trust and Risk Teams: Address vulnerabilities in verification systems to mitigate risks of misuse. * Enterprise AI Buyers: Reevaluate middleware contracts as vendor differentiation diminishes. These shifts highlight the growing importance of clear communication, strategic planning and adaptability in using AI tools effectively. Structural Shifts in Design and AI GPT Image 2 exemplifies a broader trend of consolidating creative and operational tasks into a single, prompt-driven process. By integrating research, copywriting and layout, it enables faster and more cohesive outputs. Image generation is increasingly treated as a programmable asset, seamlessly integrated into workflows to enhance efficiency and scalability. This evolution demands a new approach from teams, prioritizing intent, context and quality assurance. As execution becomes more automated, the ability to craft clear and actionable specifications will become a critical skill for professionals across industries. The emphasis will shift from manual tasks to strategic oversight, allowing teams to unlock the full potential of AI-driven tools. The Future of AI in Creative Workflows The reasoning capabilities of ChatGPT Image 2 signal a fantastic era for workflows in design, engineering and marketing. To remain competitive, you must adapt to these advancements and integrate tools like GPT Image 2 into your processes. By focusing on intent, context and quality, you can harness the full potential of these technologies. This moment represents a pivotal shift where image generation transcends aesthetics, becoming a reasoning-driven tool that reshapes creative and operational landscapes. As these technologies continue to evolve, they will redefine not only how we work but also the very essence of creativity and innovation. Media Credit: AI News & Strategy Daily | Nate B Jones Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Geeky Gadgets may earn an affiliate commission. Learn about our Disclosure Policy.
[26]
OpenAI rolls out ChatGPT Images 2.0 with improved text rendering, multilingual support, and thinking capabilities
OpenAI has introduced ChatGPT Images 2.0, a next-generation image generation model designed to produce precise, structured, and usable visual outputs. The model is built to handle complex visual tasks, improve instruction accuracy, and generate images that better reflect real-world design needs. ChatGPT Images 2.0 is designed to improve how AI interprets and executes image prompts, focusing on accuracy, structure, and visual consistency. It can place objects more precisely, follow detailed instructions, and maintain coherent layouts across complex scenes. The model is available across ChatGPT, Codex, and the API, and introduces major upgrades in composition control, text rendering, multilingual support, and visual consistency. A key addition is thinking capability, where the model can reason through prompts before generating images. In supported modes, it can also use web information, generate multiple image outputs from a single request, and refine results for better consistency. This shifts the system from basic image generation to a more structured visual reasoning tool. ChatGPT Images 2.0 uses a multi-layer safety system to manage image generation responsibly. These safeguards are designed to reduce harmful or policy-violating outputs across all stages of generation. Despite improvements, the model still has limitations:
[27]
Why OpenAI's New ChatGPT Image 2 is a Massive Leap for AI Generation
OpenAI's latest release, ChatGPT Image 2, introduces a significant upgrade in AI-driven image generation, combining advanced reasoning with hyperrealistic detail. As Matthew Berman explains, the model excels in rendering intricate textures, such as fabric patterns or natural elements, while also improving text integration within images. This makes it particularly effective for creating infographics, signage and other projects that demand both visual and textual precision. Additionally, its ability to maintain visual consistency across sequential images streamlines complex workflows, such as designing sprite sheets or cinematic stills. In this overview, you'll gain insight into how ChatGPT Image 2 enhances creative workflows through its stylistic adaptability and aspect ratio flexibility, supporting formats like 3:1 or 1:3. Explore its practical applications, from generating detailed assets for gaming and marketing to crafting realistic portraits and dynamic scenes. By understanding the model's strengths and limitations, you'll be better equipped to incorporate its capabilities into your own projects with confidence and clarity. GPT Image 2 represents a significant leap forward in AI image generation, offering a 250 ELO score improvement compared to earlier models like Gemini 3.1 Flash Image Preview. This performance boost enables the model to tackle intricate visual tasks with greater conceptual depth and precision. Its advanced reasoning capabilities allow it to interpret complex prompts and generate contextually accurate images, making it a powerful tool across industries such as gaming, marketing and education. The model's enhanced ability to process nuanced instructions ensures that it can deliver outputs that align closely with user intent. This improvement not only increases efficiency but also opens up new possibilities for creative exploration. At the heart of GPT Image 2 lies its ability to combine advanced reasoning with hyperrealistic detail. Its core features include: These features make GPT Image 2 a versatile tool for professionals seeking high-quality visual outputs. Its ability to handle detailed textures and text ensures that it can meet the demands of both artistic and technical projects. Browse through more resources below from our in-depth content covering more areas on ChatGPT. One of the standout features of ChatGPT Image 2 is its ability to maintain visual consistency across sequential images. This capability is particularly beneficial for tasks that require uniformity and precision, such as: By automating these processes, ChatGPT Image 2 enhances workflow efficiency and ensures cohesive results, saving time and effort for professionals working on large-scale projects. GPT Image 2 is designed to adapt to a wide range of visual styles, offering flexibility that caters to diverse creative needs. Its ability to produce outputs in styles such as photo-realism, manga, pixel art and cinematic aesthetics makes it a versatile tool for various applications. Additionally, its aspect ratio flexibility supports unconventional formats like 3:1 or 1:3, allowing creators to experiment with unique visual layouts. Whether you are crafting a YouTube thumbnail, designing game assets, or creating artistic pieces, ChatGPT Image 2 aligns seamlessly with your vision. Its adaptability ensures that your creative goals are met with precision and style. The versatility of ChatGPT Image 2 unlocks a wide range of possibilities across industries. Its applications include: These applications demonstrate the model's ability to handle both artistic and technical projects, making it a valuable tool for professionals in fields ranging from entertainment to education. Despite its impressive capabilities, GPT Image 2 has certain limitations that users should be aware of. These include: Understanding these limitations is essential for effectively using the model's strengths while mitigating its weaknesses. By recognizing its boundaries, users can optimize their workflows and achieve the best possible results. ChatGPT Image 2 underscores the ongoing need for human oversight in AI-generated content. While the model excels in generating high-quality visuals, human curation remains crucial to ensure that outputs meet quality standards and align with creative intent. This collaborative approach between AI and human expertise enhances the reliability and value of the final product. By combining the efficiency of AI with the discernment of human judgment, professionals can achieve results that are both innovative and dependable. This partnership fosters trust in AI-driven tools and ensures their effective integration into professional workflows. ChatGPT Image 2 represents a significant milestone in the evolution of AI image generation. Its advanced reasoning, hyperrealistic detail and stylistic versatility open up new possibilities for creative and professional applications. From gaming and marketing to artistic endeavors, the model's potential is vast and fantastic. However, its limitations and the necessity of human oversight highlight the importance of a balanced approach to AI integration. As you explore ChatGPT Image 2, its ability to enhance visual content creation is clear, paving the way for innovative breakthroughs and expanding the horizons of what is possible in AI-driven creativity. Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Geeky Gadgets may earn an affiliate commission. Learn about our Disclosure Policy.
[28]
OpenAI may launch new image AI model soon, can offer more realistic images compared to rivals
Weeks after shutting down Sora, OpenAI is reportedly working on a new image generation model which can offer more realistic images compared to the rivals. The upcoming model is said to be called as gpt-image-2 and is said to be built on the recent surge in popularity driven by ChatGPT's image tools, which went viral for creating stylised visuals such as anime-inspired artwork. As per the reports, the new model will focus on realism and aim to reduce that 'artificial' look which we often see in the AI generated images. Previous outputs were frequently criticised for overly smooth textures, perfect lighting and unnatural facial details. The next-generation system is said to address these limitations by producing images that more closely resemble real-world photography. The new gpt-image-2 model is also expected to offer improved composition capabilities. The model is said to generate more structured visuals including accurate placement of text, objects and layouts. This may make it more useful for practical applications such as presentations, design mock-ups and visual storytelling. Also read: Meta to train new workforce for data centres amid the layoff reports In the meantime, ChatGPT is reportedly testing a new reference photo feature which may allow users to upload an image once and reuse it across multiple prompts. The feature is designed to streamline workflows by reducing the need for repeated uploads. If true, the new model will directly rival Google and Anthropic's advanced image generation capabilities. However, the details including release timeline, benefits and validity about the model still remain under the wraps. Meanwhile, OpenAI is also working on a new GPT 5.5 model that is codenamed Spud. It is expected to launch next week and may bring big enhancements compared to existing models. Again, we may have to wait for a few more days to get official confirmation.
Share
Copy Link
OpenAI released ChatGPT Images 2.0, a new AI image model that can accurately generate text in multiple languages and create complex visual content like infographics and marketing materials. The model includes thinking capabilities, web information access, and can generate up to eight images from a single prompt while maintaining visual consistency.
OpenAI Unveils ChatGPT Images 2.0 With Major Text Rendering Breakthrough
OpenAI launched ChatGPT Images 2.0 on Tuesday, marking a significant leap in image generation capabilities that addresses one of AI's most persistent challenges: creating legible, accurate text. The new AI image model can now generate restaurant menus, infographics, study guides, and marketing materials with text that looks professionally designed rather than garbled nonsense
1
. Just two years ago, asking DALL-E 3 to create a Mexican restaurant menu resulted in fictional dishes like "enchuita," "churiros," and "margartas." Now, ChatGPT Images 2.0 produces menu text clean enough for immediate commercial use1
.
Source: SiliconANGLE
The improved text rendering extends beyond English, with robust non-Latin language support for Japanese, Korean, Hindi, Bengali, Chinese, and Gujarati. When tested with Gujarati instructions, the model delivered clear text with grammatical accuracy and natural phrasing
5
. This capability positions ChatGPT Images 2.0 as a practical tool for global businesses and educators creating multilingual content.Thinking Capabilities Enable Complex Multi-Image Workflows
ChatGPT Images 2.0 integrates thinking capabilities that fundamentally change how the model approaches image generation. Instead of simply matching prompt details, the AI can now search the web for recent information, generate multiple images from a single prompt, and double-check its creations
1
. The model's knowledge cutoff extends to December 2025, allowing it to incorporate current information into visual outputs2
.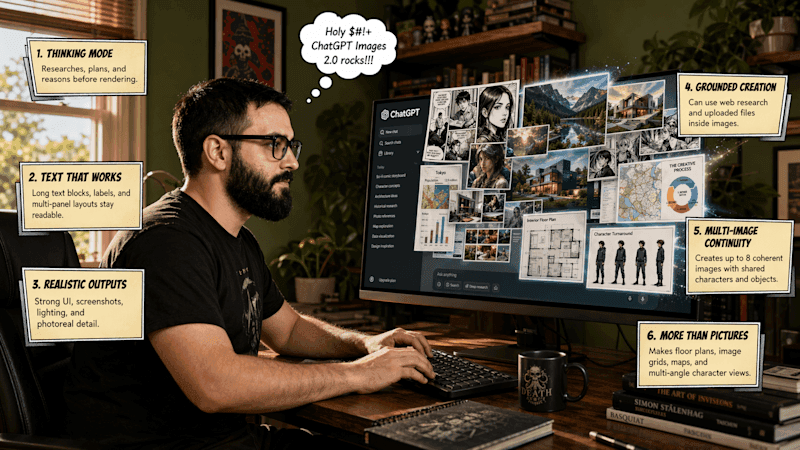
Source: VentureBeat
When asked to "Generate an infographic about activities I should do with tomorrow's weather in San Francisco in mind," the model gathered weather data, determined appropriate activities, and created an image featuring accurate weather details alongside recognizable landmarks like the Ferry Building, Castro Theater, Painted Ladies houses, and Transamerica Pyramid
2
4
. Users can generate up to eight images at once while maintaining consistency across characters, font, color palette, and overall mood—particularly useful for creating comic book pages or social media assets in various sizes5
.Customizable Aspect Ratios and High-Resolution Outputs
The new model addresses a long-standing frustration with customizable aspect ratios ranging from 3:1 wide to 1:3 tall, giving users precise control over image dimensions
2
4
. Developers using the API can create high-resolution images in 2K and 4K resolution, though these higher resolutions remain in beta3
. According to OpenAI, the model delivers "an unprecedented level of specificity and fidelity to image creation," handling small text, iconography, UI elements, dense compositions, and subtle stylistic constraints at up to 2K resolution1
.
Source: ZDNet
The focus on text-heavy visuals represents a strategic shift for OpenAI. Just one month after shuttering its Sora AI video app to concentrate on "core products," the company is building what it calls tools for "economically valuable creative tasks"
3
. Adele Li, product lead for ChatGPT Images, explained that "visual intelligence" is critical to ChatGPT's vision for developing a personal creative assistant3
.Related Stories
Positioning Against Competitors and Practical Limitations
ChatGPT Images 2.0 competes directly with Google's Nano Banana Pro and Nano Banana 2, which previously led in text rendering capabilities
3
5
. Unlike Midjourney's artistic focus or Adobe Firefly's professional editing tools, ChatGPT Images 2.0 targets working professionals who need attractive content quickly—teachers creating lesson plans, marketing managers producing social media posts, and businesses developing infographics3
.However, early testing revealed limitations. When attempting to reproduce brand logos accurately, the model struggled despite repeated instructions. In one test with the ZDNET logo, the AI either distorted elements, retrieved outdated versions, or added incorrect design features
4
. Additionally, users cannot directly edit generated images—they must regenerate them entirely, which consumes credits faster when working with complex text-heavy designs3
.All ChatGPT and Codex users can access ChatGPT Images 2.0 starting Tuesday, with generation limits based on subscription tiers. Advanced thinking outputs with web information access remain exclusive to ChatGPT Plus, Pro, and Business users
5
. The gpt-image-2 API is also available, with pricing dependent on quality and resolution1
. OpenAI maintains safety measures including C2PA metadata standards for identifying AI-generated content and policies prohibiting abusive and illegal imagery3
.References
Summarized by
Navi
Related Stories
OpenAI's GPT-4o Image Generator: A Leap Forward in AI-Powered Visual Creation
27 Mar 2025•Technology

OpenAI launches GPT Image 1.5 as AI image generator war with Google intensifies
16 Dec 2025•Technology

OpenAI's ChatGPT Image Generator Expands to Developers and Major Tech Platforms
24 Apr 2025•Technology

Recent Highlights
1
OpenAI releases GPT-5.6 models after government review, unveils ChatGPT Work to compete in AI agent race
Technology

2
Apple sues OpenAI for allegedly stealing trade secrets as hardware rivalry intensifies
Business and Economy

3
Apple Opens Siri AI to Everyone with iOS 27 Public Beta After Years of Delays
Technology

Recent Highlights
Today's Top Stories



Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


