ChatGPT passes strawberry test but AI reasoning flaws remain as cranberry exposes the same problem
2 Sources
[1]
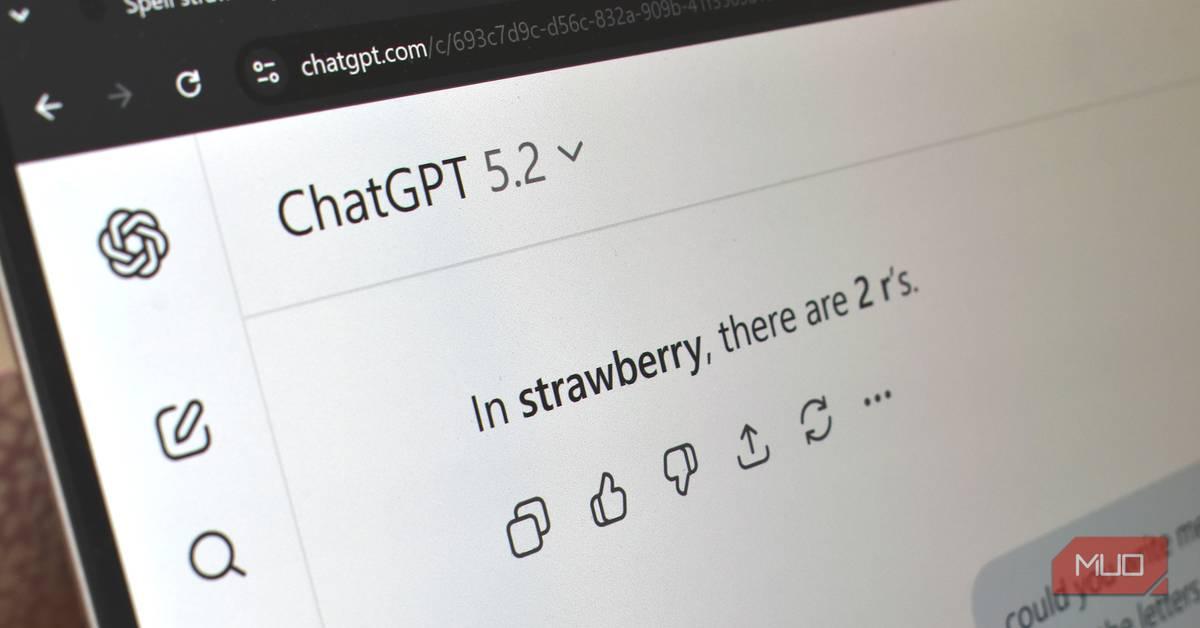
ChatGPT finally knows how many 'R's are in 'strawberry,' but confident mistakes remain
Confident mistakes - or lies, if you will - are a common problem of large language models used in AI chatbots, with one common shortcoming of ChatGPT being that it would frequently miscount the number of times the letter "R" appeared in the word "strawberry." As OpenAI tried to take a victory lap around this, though, plenty of other confident mistakes were pointed out in the replies. For as much as AI chatbots have improved, one of the biggest missteps remains the frequency at which these "tools" will confidently lie to you. If information is wrong, the chatbot won't notice and, if you call it out, the AI might dig in its heels on the response and continue to get it wrong, while telling you that it's right. It's a problem that is often shown as a danger of these tools, on top of being downright annoying given how many resources AI is taking up. One common example of this with OpenAI's ChatGPT is the question of how many times the letter "R" appears in the word "strawberry." For quite some time, asking ChatGPT about this would result in the chatbot coming back with the wrong answer, and it'll often argue that the word "strawberry" does not use the letter "R" three times. Other AI models often ran into the same problem. Today, OpenAI took to Twitter/X to proudly tout that, "at long last," ChatGPT can correctly answer this question. Another common stumbling was the prompt "I want to wash my car today but the car wash is only 50 meters away. Should I walk to drive there," to which ChatGPT would often recommend walking, despite the very obviously logical problem there. Sure enough, both of these are now working if you try them in ChatGPT, but it's suspected they might be hardcoded solutions. Many replies to OpenAI's post show other times where the chatbot fails on the same logic. For example, "How many r's are in cranberry" repeatedly sees the chatbot continue to reply with "The word 'cranberry' has 1 'R.'" Of course, that's incorrect. Hardcoded solutions in AI chatbots aren't new, but it's a bit funny - in a dystopian kind of way - to see OpenAI touting this "fix" when, clearly, the root of the problem remains.
[2]
ChatGPT just announced it can finally pass the simple 'how many "r"s in strawberry' test, but users are still tripping it up by switching to 'cranberry'
From car washes to strawberries, AI can still fumble basic answers * ChatGPT passes "strawberry" test but fails when switched to "cranberry" * AI still struggles with simple letter-counting despite broader improvements * Reasoning tests like "car wash" still expose gaps in AI logic There are a number of viral posts from people astonished that chatbots like ChatGPT and Claude can solve complex equations but struggle with something as simple as counting the number of "r"s in the word "strawberry". Well, those days could finally be over. With the words "At long last", the official ChatGPTapp X account proudly announced today that it can now count the number of "r"s in "strawberry" -- a laughably easy task for humans that has traditionally been difficult for AIs to get right. However, users very quickly found that you could still trip it up by swapping out "strawberry" for "cranberry". "Not so fast," said X user @NathanEspinoza_ in response to ChatGPTapp's boastful post about solving the strawberry problem, as he posted an image showing ChatGPT had responded saying that there was only one "r" in "cranberry". To corroborate the result, I quickly tried the same thing with my version of ChatGPT on GPT-5.5, and I was told there were two "r"s -- a different result, but still wrong. It passed the "strawberry" test perfectly, saying there were three "r"s, but then claimed there were only two in "cranberry". To its credit, ChatGPT did admit its mistake when I questioned it, putting it down to a simple "counting error". Why the strawberry problem exists There are a few very simple questions that chatbots are notoriously bad at answering, one of which is "how many 'r's are in strawberry?" This is a straightforward counting task for humans, but it's surprisingly difficult for AI systems. The reason comes down to how they process language. Large language models (LLMs) are built on transformers, which convert words like "strawberry" into numerical representations. Those representations capture meaning and context, but they don't inherently preserve a clear sense of the individual letters that make up the word. The fact that ChatGPT is still stumbling over "cranberry" suggests the solution may have been hard-coded for specific cases, rather than reflecting a broader improvement in how the LLM handles these kinds of questions. The car wash problem The second boast in ChatGPTapp's post is that ChatGPT can now solve the car wash problem. This exploits a context gap in how LLMs reason, by asking whether it would be quicker to walk to a car wash or drive if it's "only 50 meters away". Most models will tell you it's quicker to walk, missing the obvious issue that you need your car with you to wash it. ChatGPTapp claims that ChatGPT will now catch this error and point it out. But when I tried it using the latest GPT-5.5 model, it still recommended walking -- as did Claude using Sonnet 4.6. When I tested it in Gemini, however, it pointed out that while walking would be quicker, you'd need to bring the car with you if the goal was to wash it. Grok did even better. Not only did it flag the issue of not bringing the car, but it added that "this question has become a popular test for whether someone (or an AI) grasps the actual goal versus giving generic 'walking is healthier/shorter/greener' advice that ignores the context." So, for now at least, that's a win for Gemini and Grok. But if fixing "strawberry" doesn't fix "cranberry", it raises a bigger question -- are these models actually getting smarter, or just getting better at passing the tests we keep throwing at them? Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds.
Share
Copy Link
OpenAI announced ChatGPT can finally count the letter 'r' in strawberry, a task that stumped the AI chatbot for years. But users quickly discovered the same confident mistakes persist when testing with cranberry. The apparent hardcoded solution raises questions about whether AI reasoning has truly improved or if models are just memorizing specific tests.

ChatGPT Finally Solves the Strawberry Problem
OpenAI proudly announced that ChatGPT can now correctly answer one of its most embarrassing failures: counting how many "r"s in strawberry
1
. For years, the AI chatbot would confidently provide incorrect answers to this simple ChatGPT letter counting task, often claiming the word contained fewer than three instances of the letter. The official ChatGPTapp account on X declared "at long last" the problem was solved, alongside another notorious stumbling block called the car wash problem2
.The Cranberry Test Exposes Deeper Issues
Within hours of OpenAI's victory lap, users discovered the fix wasn't as comprehensive as claimed. When asked the same question about cranberry, ChatGPT repeatedly responded with "The word 'cranberry' has 1 'R'"—an obviously incorrect answer for a word containing three instances of the letter
1
. X user @NathanEspinoza_ quickly posted evidence of this failure, demonstrating that the AI reasoning improvements appeared superficial. When tested on GPT-5.5, ChatGPT provided yet another wrong answer, claiming cranberry contained two "r"s before admitting its counting error when challenged2
. The inconsistency suggests OpenAI deployed a hardcoded solution for the specific strawberry query rather than addressing the underlying AI logic gaps.Why Language Models Struggle With Simple Tasks
The persistent failures reveal fundamental limitations in how large language models process information. LLMs like ChatGPT are built on transformers that convert words into numerical representations capturing meaning and context, but they don't inherently preserve a clear sense of individual letters that make up words
2
. This architectural design makes letter-counting tasks surprisingly difficult despite the models' ability to handle complex equations and sophisticated reasoning. The confident mistakes that emerge from this limitation represent one of the most frustrating aspects of AI chatbots—they deliver wrong information with unwavering certainty, and when challenged, may continue defending incorrect responses1
.Related Stories

Car Wash Problem Shows Mixed Results Across AI Platforms
OpenAI also claimed ChatGPT now solves another AI reasoning test: the car wash problem, which asks whether you should walk or drive to a car wash 50 meters away. Most AI models recommend walking, missing the obvious contextual understanding issue that you need the car with you to wash it
1
. Testing revealed inconsistent performance across platforms. ChatGPT on GPT-5.5 and Claude using Sonnet 4.6 still recommended walking, while Gemini correctly identified that although walking would be quicker, you'd need to bring the car. Grok performed best, not only flagging the issue but noting the question has become a popular test for whether AI grasps actual goals versus providing generic advice that ignores context2
.What This Means for AI Development
The strawberry and cranberry debacle raises critical questions about whether AI systems are genuinely improving or simply memorizing answers to specific tests. Hardcoded solutions in AI chatbots aren't new, but OpenAI touting this "fix" while the root problem clearly remains highlights a concerning pattern in how progress gets measured and communicated
1
. For users relying on these tools for accurate information, the frequency of confident mistakes remains a significant danger, especially given the substantial resources AI development consumes. The challenge for developers is whether they can address fundamental architectural limitations in language models or if they'll continue patching individual test cases while deeper reasoning flaws persist. As these models become more integrated into daily workflows, the gap between performance on complex tasks and failure on simple logical questions demands attention from both OpenAI and the broader AI industry.References
Summarized by
Navi
[1]
Related Stories
GPT-5.2 still can't solve the infamous strawberry question despite billions in AI investment
15 Dec 2025•Technology
OpenAI's Strawberry Model: A New Era in AI Reasoning and Capabilities
13 Sept 2024

OpenAI's GPT-5 Launch Marred by Embarrassing Errors, Raising Questions About AI Progress
09 Aug 2025•Technology

Recent Highlights
1
OpenAI releases GPT-5.6 models after government review, unveils ChatGPT Work to compete in AI agent race
Technology

2
Apple sues OpenAI over alleged trade secrets theft as 400+ former employees caught in scandal
Policy and Regulation

3
SK Hynix raises $26.5B in largest foreign US IPO as AI boom fuels memory chip demand
Business and Economy

Recent Highlights
Today's Top Stories




Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


