Claude Code's Auto Memory feature transforms workflow automation, but performance crisis exposed flaws
4 Sources
[1]
Claude Code learns from my mistakes between sessions now, and my setup runs itself
Anurag is an experienced journalist and author who's been covering tech for the past 5 years, with a focus on Windows, Android, and Apple. He's written for sites like Android Police, Neowin, Dexerto, and MakeTechEasier. Anurag's always pumped about tech and loves getting his hands on the latest gadgets. When he's not procrastinating, you'll probably find him catching the newest movies in theaters or scrolling through Twitter from his bed. Over the past six months, I've used Claude Code to build several pet projects, a website I actually deployed, and even a fairly complex SaaS tool with a complicated backend and a clean UI. While Claude Code does a very good job of building all of this, there is still a lot of hand-holding involved. I often find myself going back to manually make small edits to the database or markdown files. I'll also ask Claude to edit the HTML, which it does, but it never seems to learn from its mistakes, particularly well. My usual workflow was to tell it, "I made these changes. Can you update your documentation, so these issues don't happen again?" However, things seem to have changed recently, following Anthropic's announcement of Auto Memory. Auto Memory builds on top of CLAUDE.md, allowing Claude to continuously update its own memory. Instead of relying on a long static CLAUDE.md file, Claude can now modify memory files based on your conversations, adding new learning and recalling them when relevant. On top of that, I've added a few third-party plugins that have made the setup even more capable. Combined, they have brought me much closer to a point where Claude Code can operate largely on its own. I tried Anthropic's open-source desk pet on an ESP32, and it fixes the most annoying thing about Claude Anthropic open-sourced a cool desk pet project, so I ported it to the WT32-SC01 Plus. Posts 2 By Adam Conway Claude.MD alone isn't enough The memories go stale Claude Code does a very good job of completing the tasks you give it, but historically, it hasn't been particularly good at maintaining context across sessions. It remembers what you tell it during a session, but it can struggle to consistently apply decisions, preferences, and corrections from days or weeks earlier. Traditionally, much of this context lived in CLAUDE.md. The problem is that, over time, the file can grow into a large collection of instructions, decisions, preferences, and workarounds. Claude might remember a plugin you asked it to use yesterday, but an important architectural decision from a week ago can become harder to surface at the right moment. The challenge isn't necessarily the size of the file itself. It's that instructions accumulate over time, and some may become outdated or even contradict one another. For example, you might tell Claude to follow a particular workflow one day and then change your mind later. If both instructions remain in the documentation, Claude has to determine which one is current and which one should be ignored. As projects become more complex, managing that growing body of context becomes a task in itself. That's one of the problems Anthropic is trying to address with Auto Memory, which allows Claude to continuously update and refine its memory instead of relying entirely on a static CLAUDE.md file. Auto Memory helps Claude code teach itself And fix its previous mistakes Auto Memory is what closes the loop between one session and the next. It allows Claude to save the useful things it learns while working, such as build commands, debugging insights, architecture notes, code style preferences, and workflow habits, and then recall them later when they matter. That means when you correct Claude, those corrections can be turned into a remembered pattern that Claude brings back the next time it sees a similar task. CLAUDE.md is still the place for stable, explicit rules you want enforced every time, but Auto Memory handles the softer, learned layer on top of that. Anthropic says Claude Code's context window includes both CLAUDE.md and auto memory, and that context gets compacted as it grows, so durable project rules still belong in CLAUDE.md while Auto Memory captures the recurring patterns Claude discovers along the way. Since auto memory has been introduced, I've noticed I spend less time reminding Claude how to work. A few months ago, every new session was like onboarding a new teammate. I'd explain the project structure, remind Claude which tools to use, point out patterns it had broken before, and occasionally clean up documentation after making manual fixes. Even with a well-maintained CLAUDE.md, there was always a sense that I needed to keep one eye on the work because I wasn't sure whether Claude would remember the lessons from previous sessions. However, lately, I've noticed Claude making fewer repeat mistakes. It is more likely to use the tools and workflows I've settled on, and it seems better at carrying forward decisions that were made days earlier. Claude.md and Auto Memory alone were not enough I needed something similar to Claude Dreams While Auto Memory solves a lot of problems, it's still not quite as autonomous as I want it to be. I wanted something closer to Claude Dreams. For those unfamiliar, Claude Dreams is a research preview feature from Anthropic that allows Claude to revisit its memory and previous sessions when it's not actively being used. It reviews past interactions, identifies patterns, cleans up noisy or outdated memories, merges duplicate information, and extracts higher-level insights useful in future sessions. Deals Deals on Software & AI Subscriptions for Devs Find savings on developer-focused software and AI subscriptions -- discounts on cloud credits, APIs, plugins, code editors, and collaboration tools. Compare offers across the category to lower costs and streamline your build workflow. Deals Explore Software, AI & Subscriptions Deals Unfortunately, the feature isn't available to regular users yet, so I have built my own approximation of it. My setup uses Mem0 as the memory layer, Claude Code as the agent, and a separate Python script that acts as the reflection layer. Claude Code handles the actual work and continuously writes information into memory, while Mem0 stores and retrieves that information across sessions. The Python script runs at regular intervals and reviews the accumulated memories and session history. During each run, it looks for recurring preferences, successful workflows, repeated mistakes, contradictions, and stale information that no longer needs to be retained. It then generates a smaller set of higher-level insights and writes those back into memory as a separate layer. Over time, the memory store becomes less of a collection of individual interactions and more of a curated knowledge base built from the agent's own experiences. You can make Claude Code yours Claude Code is perfectly capable out of the box. It comes with a lot of features and everything you need, but what you get out of the box is rarely fit for every use case. It only makes sense to customize Claude Code to suit your workflow. There are a number of mods that let you do that, and there are also a number of settings you can change to customize Claude Code the way you want. If Claude Code is going away for Pro users, I can't recommend Claude anymore This one hurts to write. Posts 42 By Mahnoor Faisal
[2]
I built a Python utility using Claude to automate my image editing workflow, and it saves me hours every week
Abhinav pivoted from a career in banking to pursue his first love in writing. Even while working full-time, he continued contributing as an editor-at-large, a role he has held for more than 7 years. A lifelong tech enthusiast who has built three gaming and productivity powerhouse PCs since 2018, his passion for technology keeps him closely following the semiconductor industry, from NVIDIA and AMD to ARM. His MSc dissertation explored how artificial intelligence will reshape the future of work, reflecting his curiosity about the wider social impact of emerging technologies. Before the rise of generative AI tools, fixing a batch of images would be messy business. It would mean bouncing between three browser tabs, logging into tools you had forgotten you had an account on, and occasionally being asked for your credit card information before you could download the files you'd spent a while working on. It was a tedious affair for what is actually quite a simple task. Things are a little different now. Since the rise of Anthropic's Claude, building a custom utility tailored to a specific workflow has been reduced to a couple of prompts, provided you know what you're doing, and have a little patience for the process. As naturally curious as I am, I decided to check if I could build a Python tool that takes any image and processes it to the exact specifications that I need, regardless of how sloppy of a photographer I was that day. Here's how I put the tool together, and what it took to get there. It began with the vision of a tool Around three specifications, and one very specific frustration It may surprise no one, but my workflow involves processing a significant volume of images for work. It can include screenshots, product images, reference captures, benchmarks... you get the idea. Anything that's fit for publication needs to meet a set of criteria before it's usable anywhere on the internet, which includes a minimum height of 1080p, and a desirable 16:9 aspect ratio. Neither of those requirements are particularly complicated to fulfill, but doing both, consistently, across a batch of files in various formats using tools that weren't built with that specific combination in mind is exactly the kind of trouble that keeps me migrating from Microsoft's awful Photos app to Canva, and from Canva to whatever image upscaling utility that isn't looking to make a quick $2.99 that day. So, naturally, I found myself daydreaming about a drag-and-drop utility that accepts WEBP, JPG, JPEG, and PNG files, takes them and applies automatic upscaling to 1080p whenever the height doesn't meet the threshold, and applies intelligent automatic cropping to 16:9. Perhaps the most underrated aspect of being in the era of vibe-coding is that sometimes, a description like that is the first step towards building the solution. The next, and the final step, is to find a model that can deliver it. I finally found a local LLM I actually want to use for coding Qwen3-Coder-Next is a great model, and it's even better with Claude Code as a harness. Posts 26 By Adam Conway I took my "brief" to Claude And it understood exactly what I was looking for... eventually The prompt that I delivered was barely any more structured than the description I mentioned. It included the three key requirements, a note about the file formats I needed supported, and a preference for a drag-and-drop interface over a file picker. Claude mapped out the approach first, which included using Tkinter for the GUI, Pillow for image processing, and the TkinterDnD2 library to handle the drag-and-drop natively on my Windows 11 system. The logic flow checked out, and I asked Opus 4.8 to proceed. The first Python utility arrived much quicker than I had anticipated, and after working through a few (or a dozen) setup issues, it ran exactly as intended. The upscaling was handled by Lanczos resampling, which is a high-quality interpolation method for resizing visual media. For most use-cases, Lanczos resampling is more than adequate. I was, however, still curious to see if it could be improved, and asked Claude whether there was a better upscaler available, perhaps something closer to what modern AI tools use under the hood. Claude came back with a suggestion to use Real-ESRGAN instead, and that's exactly why I didn't stop just here. The first upscaler was fine, but the second one was seriously impressive Lanczos got the job done, but R-ESRGAN made me stop and look twice In the place of Lanczos, Claude proposed using Real-ESRGAN, which is an open-source model that reconstructs image details by using a deep neural network trained on degraded image pairs. In that way, it's slightly different in how it functions from a conventional interpolation model. This is the one detail that piqued my interest. While Lanczos itself is a strong algorithm, providing clean and sharp results for most upscaling tasks, asking it to recover a low-resolution image means essentially relying on educated guesswork about the missing details. R-ESRGAN, on the other hand, recognizes textures, edges, and structures and rebuilds the image from there. Deals Save on AI tools and software deals for creators Unlock discounts on software, AI subscriptions, and image-enhancement utilities -- shop deals on creative apps, cloud model access, automation tools, and productivity plugins to streamline your workflow and save on essential tools. Deals Explore Software, AI & Subscriptions Deals To test both the techniques, I deliberately compressed the test image down to 500x272 pixels. The Lanczos output scaled up as expected but carried the compression noise with it, producing an image that was large but retained all the original's limitations. The Real-ESRGAN output did a far more impressive job by reconstructing the foliage texture, sharpening the panel lines on the car, and recovering road details. The one area it obviously struggled was the finer details, such as the logo on the controller, text on the all-in-one cooling unit, and the license plate on the car that came back as reconstructed noise rather than legible text, which is a known limitation of most upscalers when the source detail is too degraded to recover precisely. In practice, of course, it isn't reasonable to expect ground-breaking upscaling from such a low-resolution source image. Obviously, this wasn't done for the purpose of editorial use, but rather as a stress test for the upscalers. The images did end up making it to at least one publication, however! Vibe coding your everyday annoyances away is severely underrated As someone with several folders full of vibe-coded utilities that each solve a distinct problem in my workflow, I absolutely see the allure and the merit in the approach. Anyone with a clearly defined problem can now arrive at a working solution. Charles Kettering once said that a problem well-stated is a problem half-solved, and I can't think of a philosophy that applies more neatly to vibe coding than that. The other half, as I learned across a dozen setup errors and one stubborn library, of course, is patience. That being said, the barrier to building something useful has never been lower, and for me, that's something worth getting excited about. Claude Claude is an AI assistant and LLM developed by Anthropic. See at Claude Expand Collapse
[3]
Claude's no-code canvas replaces hours of Python debugging in minutes
Aggy is a veteran writer and editor in the technology and gaming space. Having served as a Managing Editor for high-traffic digital publications, alongside being an editor and consultant for over a dozen sites. Aggy's published work spans a wide and respected array of tech and gaming outlets, including WePC, Screen Rant, How-To Geek, Android Police, PC Invasion, and Try Hard Guides. Beyond editorial work, Aggy's direct experience in the tech sphere extends to app development. Aggy has published two games under Tales and is always eager to learn and do more. He also likes working on computers and researching in his spare time. He knows about Windows, Linux, Audio, Video, and much more. Cleaning massive, disorganized spreadsheets or parsing through thousands of lines of raw server logs is annoying. You can do it yourself, make a program to do it, or you can just give it to Claude and ask it to fix your problems. Claude has a built-in execution canvas that handles smaller tasks. It's a sandboxed processing environment that lives right inside your chat window, so you can drop in files and use plain language to make the fixes you need. This is one of the ways Claude works better than usual. Claude is a lot more reliable than you would think Claude has a built-in canvas that builds apps and visuals from text I like Claude's no-code interface because it means anyone can work with it without knowing how to code. Instead of opening a terminal or writing SQL queries, you just describe what you want, and the interface handles the rest. This works because there's a full code execution engine running directly inside the chat window. You describe a goal in plain English, making sure to be specific about what you want, and the system writes and runs the code behind the scenes. You end up seeing the result in the chat, usually exactly as you wanted it. You don't have a Python environment to configure, no matplotlib syntax to remember, and no pandas documentation to dig through. It is great for people who have a simple project to get through and just want to see a final result, or those who want to see a prototype of their idea before they build it. Luckily, this is better than many other AI code builders, because it lets you see what you're asking for. When you send a message, Claude figures out what's needed and runs everything inside a secure sandboxed container. You never see a terminal. You never deal with dependency errors. The background work happens entirely out of sight. I am pretty used to asking for code, copying it into my editor, running it, hitting an error, pasting the stack trace back into the chat, and doing it all over again. The new interface is much better. This isn't a good way to have it teach you how to code, like the regular chatbot interface, but it's a good way to have code written. Claude runs its own code, reads its own error logs, fixes what broke, and keeps going until it has something worth showing you. If a data pipeline fails mid-run or a chart doesn't render correctly, Claude patches it on its own before you ever see the result. Using it is pretty simple Drop your files into the chat to get instant results You can drag your data files straight into Claude's chat window to handle them. It handles messy Excel spreadsheets, CSVs, JSON, plain text server logs, and PDFs. You can do up to twenty files per conversation, thirty megabytes each. Once they're uploaded, just describe what you want done in plain English. You don't need to wrangle boilerplate code, import libraries, or build regex patterns just to parse a log file. Tell it to clean up a disorganized marketing spreadsheet, pull specific error codes from a server log, or merge several data sources into one table. It might feel like cheating, but it's writing the same code you would; you're just not the one typing it. Then, Claude hands your instructions off to a built-in code execution engine running quietly in the background. Depending on the task, it'll use either a JavaScript environment with libraries like PapaParse and Lodash, or a Python container stocked with pandas, numpy, matplotlib, and friends. It writes, runs, and debugs the scripts itself. You never touch a dependency or a config file. I used to lose hours to pandas type errors alone. Having something else handle that execution loop is a huge relief. When it's done, the results come back to you directly in the browser. I've seen many charts and heat maps, but I have had it just make a clean spreadsheet, a formatted one, or just a proper CSV. From there, you can keep modifying it. You can filter by date range, tweak a chart's styling, and reshape the data. The whole thing lets you clean spreadsheets, parse logs, and convert file formats without reading or writing a single line of Python. This isn't the perfect answer You still need to watch out for token limits and logic bugs While Claude's no-code environment is genuinely useful, it would be a lie to say it is perfect. The biggest limitation is the data size. The system seems to have issues with large datasets that are larger than its context window, which means it may only partially process what you've uploaded. So you want to avoid heavy Excel spreadsheets, server logs, or text-heavy PDFs. These eat through the available memory fast. When that memory fills up, the system doesn't stop and tell you; it just quietly starts dropping the oldest information to make room for new inputs. This means it forgets earlier files or parameters. If you're trying to analyze hundreds of thousands of rows, the model might only work through a portion of them, producing skewed or incomplete results unless you've pre-segmented the data yourself. Data privacy is another issue you should take seriously. Uploading company files to a public cloud environment can conflict with corporate compliance policies. Things that you upload are processed on external servers and may be retained for 30 days or longer if your settings allow the data to be used for model training. That's a serious problem for organizations subject to GDPR, HIPAA, or SOC 2. It's easy to assume these tools are locked down by default, but they're not. You have to check to be sure. Unless your organization is running through an Enterprise tier with Data Processing Agreements and Zero Data Retention in place, dragging a sensitive spreadsheet into the chat window is a potential data breach. Then there's the subtler issue of hallucinated logic. Claude can generate code that runs without errors but gets the business logic completely wrong. You've got to really be careful with bigger projects. It can miss what you need and ignore it because it didn't trigger an error. All of this means you can't treat the AI as a black box that you just trust. You have to review what it produces and adjust it where you can. Don't use this for every big thing, just little ones Relying entirely on AI for every workflow isn't the right move. Token limits can cause context issues with heavy datasets, and uploading proprietary company data to a public cloud carries real security risks. If your organization deals with highly sensitive financial records or massive data volumes, a local dev environment is still the better call. That said, if you need to quickly prototype dashboards or clean up messy spreadsheets without wrestling with dependencies, Claude is one of the fastest ways to get it done Claude Price $20 Claude is an AI assistant made by Anthropic. It can assist with a wide range of tasks -- writing, coding, analysis, research, and more. Unlike a search engine, Claude reasons through problems conversationally, making it useful as a thinking partner rather than just an information retrieval tool. See at Claude Expand Collapse
[4]
Anthropic made Claude worse for a month -- this is how they got caught
I love using Claude, to the point where I cancelled ChatGPT, Perplexity, and Gemini because Claude did everything I needed. But if you're like me and have been using Claude for a while, you would've noticed the responses feeling sloppier. The model seemed to forget what it was doing mid-task, and code quality dropped massively. When I went looking for answers, none came from Anthropic. Frustrated users kept complaining across platform, and the company behind Claude remained silent -- unitl one AMD executive made that silence impossible to maintain. Someone left Claude Code running overnight, and it cost $6,000 Claude Code worked overtime and billed like a senior consultant. Posts By Oluwademilade Afolabi Users noticed the change before Anthropic did Benchmark drops, strange behavior, and mounting complaints The complaints about Claude's degrading quality started trickling in around early March 2026. Developers on Reddit, GitHub, and Hacker News reported that Claude Code -- Anthropic's AI-powered coding tool -- had gotten noticeably worse. The model was reading through code less carefully before making changes, leaving tasks halfway, and producing fixes that were technically correct but an architectural nightmare. Among these frustrated users was Stella Laurenzo, senior director of AMD's AI group and the engineer who previously built Google's OpenXLA infrastructure. On April 2, she filed a detailed GitHub issue that ended up becoming the starting point for the entire controversy. Her complaint wasn't based on gut feeling either. She and her team had analyzed 6,852 Claude Code sessions covering 17,871 thinking blocks and 234,760 tool calls. What they found was that Claude's median thinking depth had collapsed by roughly 73% since early February. The read-to-edit ratio, a measure of how much Claude studies code before touching it also fell from 6.6 reads per edit to just 2. Edits made without reading any code first jumped from 6.2% to 33.7%. The conclusion: Claude cannot be trusted to perform complex engineering tasks. Period Thinking Visible Thinking Redacted Jan 30 - Mar 4 100% 0% Mar 5 98.5% 1.5% Mar 7 75.3% 24.7% Mar 8 41.6% 58.4% Mar 10-11 >99% Mar 12+ 0% 100% Every senior engineer on her team had independently noticed the same pattern, which made it especially hard to dismiss. She also noticed a clear behavioral shift from Claude being research-first and cautious to being edit-first and hasty. The GitHub issue explains this by saying that when thinking is shallow, the model defaults to the cheapest action available: edit without reading, stop without thinking, dodge responsibility for failure. Claude Developer Anthropic PBC Price model Free, subscription available See at App Store See at Google Play Store See at Claude Expand Collapse The silence became part of the story Why the lack of communication frustrated users even more The degraded output is one thing, but Anthropic's response, or rather the lack of it, made things worse. For weeks, the company offered no blog post, no status page update, no email to subscribers, and no formal acknowledgment of the problem. Individual engineers made informal comments on social media, but the company as a whole said nothing meaningful while charging customers $20 to $200 per month for a tool that had suddenly become significantly worse. In the meantime, third-party benchmark data kept piling on. BridgeMind reported that Claude Opus 4.6's accuracy on their hallucination benchmark had dropped from 88.3% to 68.3%, sending it from second place all the way down to tenth on the leaderboard. The exact methodology behind the test is contested, but it was consistent with the broader narrative that Claude had suddenly become worse, and no one knew why. One month, multiple problems The bugs, regressions, and odd behavior that piled up fast Anthropic finally released a detailed report on what was going on on April 23. Long story short, the problems were being caused by three separate product-layer changes that had stacked on top of each other between March and April, each affecting a different part of the user base on a different schedule. The weights themselves never changed, but the infrastructure around them was affected. The first change happened on March 4, when Anthropic changed Claude Code's default reasoning effort from high to medium. Anthropic claims it was done because high-effort mode was causing the UI to appear forzen during long thinking periods. What actually ended up happening is that a lot of users suddenly started noticing the intelligence drop but didn't know why, and Anthropic had shipped no formal warning in advance. It took until April 7, over a month later, for the company to revert the change. Second issue was a caching bug that came March 26. Anthropic built an optimization to clear Claude's older reasoning history from sessions that were idle for over an hour. However, a bug in this routine caused the cache clearning to fire every single turn for the rest of the session, not just once. This meant that every follow-up question you asked, reduced Claude's reasoning history and over time, longer chats started showing the forgetfulness and bizzare tool choices user had been reporting. It also cause a separate wave of complaints about usage limits draining faster than usual. Last but not least, the third change shipped on April 16 alongside Opus 4.7. Anthropic added a verbisoty instruction to Claude Code's system prompt that kept tool calls to less than 25 words and final responses to less than 100 words. It seemed safe during weeks of internal testing, but later investigation showed a 3% quality drop across both Opus 4.6 and Opus 4.7. It was reverted four days later on April 20. Because each change hit different users at different times, the overall effect looked more like a subtle, inconsistent degradation. The internet did the investigation How users, benchmarks, and community testing exposed the issues Stella Laurenzo's GitHub post might the be most significant factor behind Anthropic not only being caught, but also forced to investigate and fix the issue. She didn't just complaint -- she built an analysis pipeline, intrumented her sessions, and produced a data-backed report that Anthropic's internal teams couldn't ignore. It was also detailed and repoducable enough that other engineers could look at their own session logs and recognize the same patterns. Subscribe to our newsletter on AI tool reliability Track AI model reliability -- subscribe to our newsletter for rigorous coverage of regressions, incident analysis, vendor responses, and community investigations that clarify how and why AI tools change. Get Updates By subscribing, you agree to receive newsletter and marketing emails, and accept our Terms of Use and Privacy Policy. You can unsubscribe anytime. The Hacker News thread debated whether Anthropic's stated rational for the changes was real or just a cover for cost-cutting. Anthropic's internal staff had also been using a different build of Claude Code than what shipped to paying customers, meaning the dogfooding that's supposed to catch these issues never caught them. I love Claude, but these mistakes were painful. Why Claude feels more human to talk to than ChatGPT, and what that actually means It's not magic. Here's what's actually going on. Posts 1 By Tashreef Shareef In its response, Anthropic has committed to fixing both problems. A larger share of internal staff will now use teh exact public build. The company will run broader per-model evaluation suites for every system prompt change. And as a gesture of goodwill, Anthropic reset usage limtis for all subscribers on April 23. Regardless, it took a senior AMD director building a custom analysis pipeline to force the conversation. The lesson for anyone depending on a black-box AI service for professional work is clear: if you don't measure your sessions, you may never find out if the tool got quitely worse.
Share
Copy Link
Anthropic Claude introduced Auto Memory to help the AI model learn from mistakes across sessions, dramatically improving workflow automation for developers. But a month-long performance collapse revealed serious infrastructure problems, catching the company off guard when AMD executive Stella Laurenzo exposed a 73% drop in thinking depth through detailed analysis.
Auto Memory Changes How Claude Code Learns
Anthropic Claude has introduced Auto Memory, a feature that fundamentally changes how the AI model retains information between coding sessions
1
. Unlike the static CLAUDE.md file that developers traditionally used to maintain project context, Auto Memory allows Claude Code to continuously update its own memory based on conversations, adding new learning and recalling them when relevant1
.
Source: MakeUseOf
The feature addresses a persistent challenge in the AI coding experience: maintaining context across sessions. Developers previously found themselves repeatedly explaining project structures, reminding the AI model which tools to use, and pointing out patterns it had broken before
1
. Auto Memory captures build commands, debugging insights, architecture notes, code style preferences, and workflow habits, then recalls them later when they matter1
.The context window now includes both CLAUDE.md and Auto Memory, with CLAUDE.md handling stable, explicit rules while Auto Memory manages the softer, learned layer of recurring patterns
1
. This combination has brought developers closer to a point where generative AI tools can operate largely independently.Real-World Applications Show Workflow Automation Potential
Developers are using Anthropic Claude to build sophisticated tools that save hours of manual work. One developer created a Python utility that automates image editing workflows, processing batches of images to exact specifications regardless of input quality
2
. The tool handles automatic upscaling to 1080p and intelligent cropping to 16:9 aspect ratios across WEBP, JPG, JPEG, and PNG formats2
.
Source: XDA-Developers
Claude Code suggested using Real-ESRGAN, an open-source model that reconstructs image details using a deep neural network trained on degraded image pairs, instead of conventional Lanczos resampling
2
. The implementation used Tkinter for the GUI, Pillow for image processing, and TkinterDnD2 for drag-and-drop functionality2
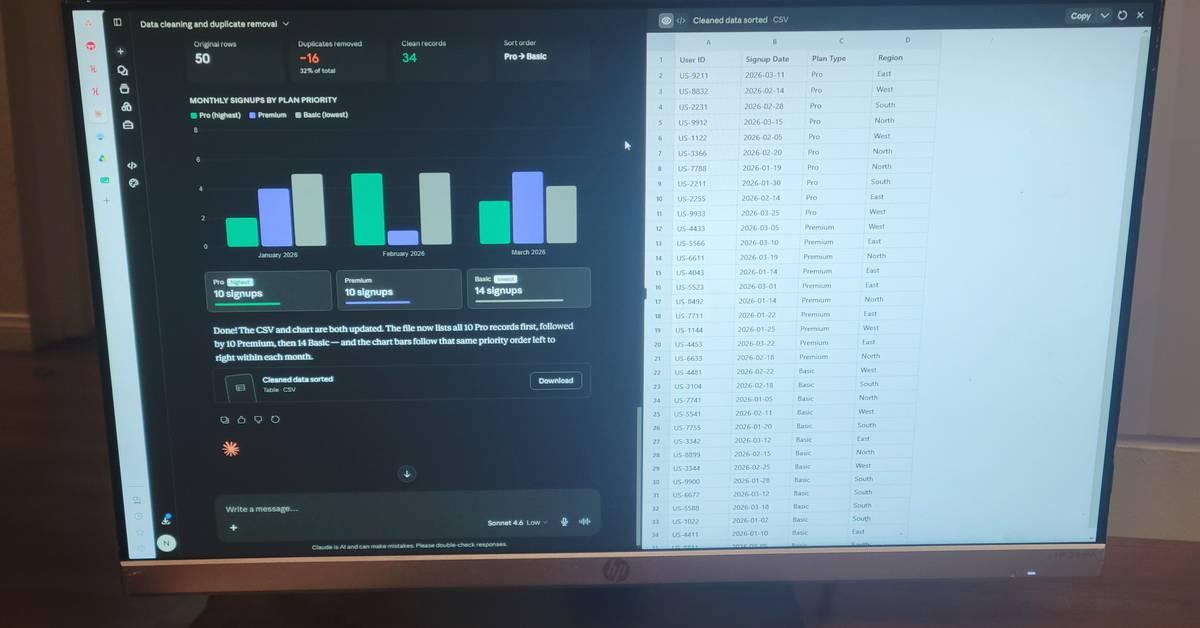
.The no-code canvas feature enables data manipulation without writing code. Users can drag up to twenty files per conversation, thirty megabytes each, directly into the chat window
3
. Claude Code handles data cleaning and parsing by writing and running code behind the scenes using either JavaScript with PapaParse and Lodash, or Python with pandas, numpy, and matplotlib3
. The system runs, debugs, and fixes scripts autonomously, eliminating hours of Python debugging3
.
Source: How-To Geek
Related Stories

Performance Crisis Reveals Infrastructure Weaknesses
While Auto Memory improved retention, AI model performance collapsed dramatically between March and April. Stella Laurenzo, senior director of AMD's AI group, filed a detailed GitHub issue on April 2 after analyzing 6,852 Claude Code sessions covering 17,871 thinking blocks and 234,760 tool calls
4
. Her team discovered that median thinking depth had collapsed by roughly 73% since early February4
.The read-to-edit ratio fell from 6.6 reads per edit to just 2, while edits made without reading any code first jumped from 6.2% to 33.7%
4
. BridgeMind reported that Claude Opus 4.6's accuracy on their hallucination benchmark dropped from 88.3% to 68.3%, sending it from second place to tenth on the leaderboard4
.Anthropic released a detailed report on April 23 revealing three separate product-layer changes had stacked between March and April
4
. On March 4, the company changed Claude Code's default reasoning effort from high to medium without formal warning, causing a noticeable intelligence drop4
. A caching bug introduced on March 26 cleared older reasoning history from sessions idle for over an hour, further degrading performance4
. Anthropic reverted the reasoning effort change on April 7, over a month after implementation4
.The company's silence during the crisis frustrated users paying $20 to $200 per month for the service
4
. Developers should watch for transparency in future updates and monitor AI model performance metrics independently, as this incident demonstrates how infrastructure changes can silently degrade capabilities even when model weights remain unchanged.References
Summarized by
Navi
[1]
[2]
Related Stories
Claude AI's workflow automation features are helping users cut their work hours in half
10 Apr 2026•Technology
Claude AI users find ways to tame usage limits as token costs pile up across workflows
23 Jun 2026•Technology
Claude Code's future in Pro plan uncertain as free alternatives emerge using DeepSeek and Ollama
04 May 2026•Technology
Recent Highlights
1
Over 200 Economists Warn AI Economic Impact Could Eclipse Industrial Revolution in Just Years
Policy and Regulation

2
Xi Jinping positions China as global AI partner while challenging US tech dominance
Policy and Regulation

3
EU Orders Google to Open Android to AI Rivals and Share Search Data Under Digital Markets Act
Policy and Regulation

Recent Highlights
Today's Top Stories




Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


