State media control shapes what AI chatbots say by flooding training data with biased content
3 Sources
[1]
State media control shapes LLM behaviour by influencing training data
Generative artificial intelligence has been shown to have considerable persuasive potential, raising concerns about who builds the generative models. We decided to investigate how powerful institutions shape the information environment that produces the data that others use to build their large language models (LLMs). States constantly aim to shape discourse through media control and information operations. These efforts can, sometimes unintentionally, influence LLMs that the states do not directly control. We proposed that this influence is strongest when a state produces a substantial amount of content, uses repeated phrasings that are easy for models to absorb, and operates in a language that is mostly exclusive to that state. We looked for observable evidence to support our hypotheses of institutional influence, with a key challenge being that AI companies rarely give researchers access to the inside of their models. We expected that state influence would be most evident in the language of the state: a question about a government should produce a more pro-government answer if posed in the language specific to the government's territory than in a different language. If this pattern of more pro-government answers in the local language is driven by institutional influence, it should be strongest in states with tight media control. Indeed, this is what we found across 37 states in which at least 70% of the speakers of an official state language live in the state (Fig. 1). This result is only a correlation, so we did a case study on China to trace the mechanism. We found that state-scripted news content shows up in a common training data set 41 times more often than content from Chinese-language Wikipedia does; that commercial models reproduce distinctive phrases from state-scripted news; and that further pretraining of an 'open-weight' LLM (one with publicly released parameters) on state-scripted news causes more pro-government responses than training on other Chinese-language text does, especially when prompted in Chinese. Linking these open-weight results to closed commercial models gives a result in line with the cross-state analysis: ChatGPT and Claude gave more-favourable answers about institutions and leaders in China to queries written (by us or by ordinary users) in Chinese than in English. Together, our results support the same mechanism of institutional influence. Our results indicate that state media control shapes the behaviour of LLMs, even beyond state borders, by influencing LLM training data. Institutional influence on LLMs is particularly concerning because it 'launders' the source of manipulated content into seemingly objective text. There is no reason to think that institutional influence was an initial motivation for state media control or information operations, but our results highlight the potential for future manipulation of LLMs by influencing the information environment. Authoritarian governments have advantages over democracies in this respect, because state outlets flood the information environment with their material, whereas state-owned organizations in democratic states typically have to compete with opposition or commercial media. Furthermore, our study highlights the need for transparency about training data from technology companies. Researchers and users of LLMs could better understand the scale of institutional influence if we could directly examine the training data and model parameters of commercial LLMs. Moreover, the pervasive effects of state media control make it hard to assess model training counterfactuals. Even if all state-scripted media could be removed from LLM training data, other documents in the training set would be influenced by it anyway. There is much more work to do. Previous studies have shown that LLMs are persuasive, but we do not know how much of that persuasive potential is carried through the institutional influence we document here. These results are only for text, but the same influences are probably present for multimodal (image and video) models. The bottom line is that training data are produced in a context shaped by socio-political institutions. An understanding of these institutions would give us a better understanding of LLM behaviour. -- Brandon M. Stewart is at Princeton University, Princeton, New Jersey, USA, and Hannah Waight is at the University of Oregon, Eugene, Oregon, USA. This project came about through the merging of two research streams. One half of the group had published research on Chinese state media coordination that provided important context and a source of data. Other members of the group came into the project through previous related research on AI. This combination was particularly generative for the design of this study. When we initially sent the project to Nature, we had only the case study of China. Our editor, Mary Elizabeth Sutherland, suggested that, if we were right about the mechanism of institutional influence, we should see the same result in different countries. When we ran the cross-state analyses, we were thrilled to see that the results we had painstakingly collected in China held across the world. This editorial collaboration gave us even greater confidence in our theory, because it had passed the hardest test: one proposed by a critical reader. -- B.M.S. and H.W.
[2]
State media control influences large language models - Nature
We have made our case primarily in the context of China, but the empirical patterns that we have identified speak more broadly about powerful institutions and the role of training data in AI. Just as companies and governments have incentives to manipulate search results and social media algorithms, so too may they try to use their institutional power to control the output of generative AI. We used the open-source training data, CulturaX, a cleaned and de-duplicated 6.3-trillion token multilingual dataset derived from the Common Crawl. The Common Crawl is a massive dataset of daily web crawls. As of February 2024, it contains text from over 250 billion web pages from 17 years. The creators of CulturaX combined and cleaned the latest versions of Common Crawl derivatives: multilingual C4 (3.1.0) and OSCAR (OSCAR 2019, OSCAR 21.09, OSCAR 22.01 and OSCAR 23.01). C4, OSCAR and Common Crawl are common training data sources for language and other machine learning models. In Fig. 2a, we compared the nearly 200 million CulturaX Chinese-language documents to our two sources of Chinese state-coordinated media. We measured the degree of text sequence overlap between our state-coordinated documents and the CulturaX documents using five-word gram cosine similarity, a common measure of text reuse. Intuitively, a high cosine similarity indicates that two documents have lots of overlap in sequences of five words. We ran the main analysis of this study, matching CulturaX documents to our state-coordinated documents, in March and April 2024. CulturaX documents are web pages in the Common Crawl and thus include extraneous content (for example, advertisements) beyond the main content of the web page. As such, we do not require CulturaX documents to exactly copy the state-coordinated documents and instead considered two documents to be matched, that is, to be likely copying from each other or a third, shared source, if they have at least 0.2 five-word gram cosine similarity. In Supplementary Information Section A, we validate this cut-off and provide additional analyses explaining these patterns. Our findings suggest that the patterns in Fig. 2a are largely driven by the spread of state-scripted and standardized language across the Chinese internet. Team researchers developed the keywords used in Fig. 2a related to Chinese leaders and political institutions. These terms included Central Committee Plenum (共产党 and 中央委员会 and 全体会议), Party Congress (中国 and 全国 代表大 会 and (十八 or 十九 or 二十)), Chinese Communist Party (中国 and 共产党), National People's Congress (人民代表大会 or 人大), foreign affairs (外交部 and 发言人), economy (经济 and (社会 or 发展)), Xi Jinping (习近平), Deng Xiaoping (邓小平) and Mao Zedong (毛泽东). In an additional robustness check, we tested whether the matching patterns that we observed in Fig. 2a hold if we examined another institution of Chinese state media control: news articles and television transcripts from state-run Chinese media. We collected 7,227,128 web news articles over 11 years (2012-2022) from Xinhua News Agency, China's largest state-run news agency. We paired this with nearly 10 years (2016 to June 2025) of 89,793 television transcripts from Xinwen Lianbo, a nightly news television broadcast by CCTV, China's largest state-run television broadcaster. In Extended Data Fig. 1, we see similar patterns with this more numerically common but less directly state-influenced type of content. CulturaX documents with more sensitive terms exhibit higher rates of state-controlled media matching across all types of source. The match rate to state media documents is also higher than the match rate to scripted news and Xuexi Qiangguo for CulturaX documents containing non-sensitive keywords (soccer, weather). This pattern is consistent with the observation that Xinhua articles and Xinwen Lianbo transcripts include more than state-coordinated and state-controlled content. We conducted a series of domain benchmarks to further understand the makeup of Chinese-language CulturaX. We searched for a series of domain names in the URLs of simplified Chinese-language CulturaX documents: Wikipedia, Baidu ('China's Google', with multi-functional sub-domains including news, wiki-pages Baidu Baike, chatrooms and Quora-like Baidu Zhidao), Xinhua News Agency web news and state-run People's Daily web news. We also estimated the percent of Chinese-language CulturaX documents, which included a government 'gov.cn' or 'chinacourt.org' domain. Our results (see Extended Data Fig. 2) show that content from Chinese government-controlled and government-run web pages makes up a much larger share of Chinese-language CulturaX documents than content from Chinese-language Wikipedia pages. We found that 1.65% of simplified Chinese-language CulturaX documents are from either a gov.cn or chinacourt.org domain but only 0.0402% of documents are from a Wikipedia page (about 41-times fewer documents). The 1.65% is close to the percent of Chinese-language CulturaX documents matched via text reuse to a scripted news or Xuexi Qiangguo document in our main results (1.64%). This estimate is also close to the fraction of documents attributed to Wikipedia in 'The Pile', a commonly used machine learning dataset. In the Supplementary Information, we conducted a further benchmark test with a text-based measure, matching CulturaX documents to Chinese-language Wikipedia. Despite using similarly sized corpora, we matched 12 times as many Chinese state-coordinated documents to CulturaX than we did Chinese-language Wikipedia pages. We used our memorization analysis to provide further evidence that Chinese state-coordinated media is in the training data of commercial LLMs. Language models memorize only a small portion of their training data, but memorization increases with phrase repetition. To test for the existence of state-coordinated media in LLM training data, we selected on state-coordinated sub-texts that would, if actually in the training data, be the most likely to be memorized and extractable. We identified common 20-word sequences characteristic of state-coordinated documents, a sub-text length close to the median sentence length in a sample of our scripted news documents (22 words). We baselined the memorization rate of these sub-texts with the memorization rate for naturally occurring common sequences of words in internet-based Chinese language, approximated with common 20-word sequences in non-state-coordinated CulturaX documents. These non-state-coordinated documents were a random sample of CulturaX documents that had less than 0.1 five-word gram cosine similarity score with any scripted news or Xuexi Qiangguo document. This lower threshold (0.1 versus the 0.2 cut-off that we used as the match threshold for study 1) increases our confidence that these documents did not include sub-texts from our state-coordinated documents. We used lasso regression to identify the 1,000 20-word grams most associated with the state-coordinated documents and the 1,000 20-word grams most associated with the non-state-coordinated CulturaX documents. We measured the extent to which commercial models memorized these 20-word sequences by prompting the models with half of each sequence and then estimating the overlap between the model completions and actual ending sequences. We prompted with the 'temperature' of the models set to zero and only considered the completions where the model did not refuse to answer. We did not require 'regurgitated' model completions to be exact copies of a state-coordinated or CulturaX phrase, as such a strict threshold would miss cases with small differences such as punctuation marks. Instead, we estimated whether the completions were near copies by measuring the edit distance between model completions and actual ending word sequences. We labelled a phrase as memorized if the completion of a model had a normalized edit distance less than 0.4 with the actual ending phrase. In Supplementary Information Section B, we show that our finding that commercial models regurgitate Chinese state-coordinated documents is robust to using alternative approaches to phrase selection, including 30-word gram sequences and randomly selected short paragraphs. Furthermore, we validated our memorization threshold with hand labelling, provided more details on our measurement strategy and included our estimation of Shannon's entropy for state-coordinated and non-state-coordinated 20-word phrases. In Extended Data Table 1, we include an example of a memorized state-coordinated phrase. We include more examples in the Supplementary Information. We ran the main results of study 2 in January 2025. We used Llama 2 13b for our pretraining experiment (https://huggingface.co/meta-llama/Llama-2-13b-hf) to strike a balance between feasibility (can fit into a single A100 80GB GPU) and language competency (unlikely to generate random words). Another advantage of Llama 2 is that we have strong evidence that there is very little to zero Chinese state-coordinated media in the pretraining data of the model. Llama 2 had very few Chinese-language pretraining tokens. We sequentially added additional Chinese-language pretraining documents to Llama 2 in three conditions: scripted news articles, non-scripted news articles similar to the scripted articles in terms of topic, year and article length, and non-state-coordinated CulturaX documents similar to the scripted articles in terms of article length. This allowed us to isolate the effect of additional pretraining on state-scripted news as compared with non-scripted (but still state-controlled) news media and general Chinese-language texts. We saved a model checkpoint every 100 training steps (for a total of 1,000 training steps), using a batch size of 64. To give the models the ability to chat and answer questions, we fine-tuned all checkpoints on the same set of English instructions. We then prompted the instruction fine-tuned models at each checkpoint with the same political prompts that we used in the study 4 LLM-as-judge audit. To reduce the resources required for the experiment, we used LoRA for both pretraining and fine-tuning, where we updated all linear layers with a rank of 32. We used GPT-4o to rate the favourability of responses from the models with additional pretraining versus the original Llama 2 model with instruction fine-tuning only. One important complication for our study is that training examples seen later probably have more influence on model weights than earlier examples. This phenomenon, often called 'catastrophic forgetting', occurs because of the sequential nature of training, such that weights in the network that are important for early examples are changed to update based on examples seen later in the process. LLMs tend to memorize phrases from pretraining data seen later in the training process at higher rates. In our experiment, models saw the state-coordinated content more recently than the rest of the data. This further underscores the fact that our experiment should be understood as demonstrating a plausible mechanism by which training on state-coordinated media affects LLM outputs through the model parameters. We do not know how closely it mimics real commercial model training. We conducted a range of additional tests and analyses. These included replicating our experiment on Llama 3.1, translating the instruction fine-tuning dataset into Chinese, using a rank of 8 for updating LoRA weights and using an absolute rather than relative measure of model favourability in the evaluation stage. These additional results are included in the Supplementary Information Section C along with further details of the experimental setup. We executed the pretraining phase of this study between March and September 2024 and evaluated the completions of these models in January 2025. We include example model completions from our pretraining experiment in Extended Data Table 2 and an additional example in Supplementary Information Section C. In studies 4 and 5, we looked for the observable implications of state-coordinated training data, which we observed in study 3: for production models trained on Chinese state-coordinated media, we should see more favourable responses about China when prompting in Chinese than when prompting in English. In study 4, we ran a human evaluator audit of GPT-3.5 and an LLM evaluator audit of a larger range of GPT and Claude models with prompts that we created. In study 5, we replicated the LLM-as-judge design on real-user prompts. For all three audits, we blinded the evaluator to the provenance of the completion (whether it was from an original Chinese or English prompt) by translating the completions into the other language. Therefore, for each prompt, we generated two comparison pairs, one in English (English completion and Chinese completion translated into English) and one in Chinese (Chinese completion and English completion translated into Chinese). We visualized this design in Extended Data Fig. 3. This design is analogous to past search engine audit studies that prompt the system with queries that vary along the dimension of interest. We ran the production model completions for our human audit in November 2023. Our research assistants evaluated these completions in March and April 2024. The study 4 LLM-as-judge GPT-3.5, Claude Sonnet and Claude Opus audit completions and evaluations were run in March 2024. The GPT-4o audit was run in May 2024. We ran and evaluated the study 5 WildChat completions in September 2024. In our pre-registered human audit, our nine research assistants chose which completion in the pair reflected more positively on the institution, leader or country that was the subject of the prompt. We randomized whether each pair of completions was displayed to the research assistants in Chinese or English. We calculated for each pair the percent of research assistants who labelled the original Chinese completions as more favourable. Across all prompts about China, the average percent of research assistants who chose the original Chinese completion was 75.3%. For prompts not about China, this estimate was 52.8%, or no different from random guessing. In Supplementary Information Section D, we show the distribution over prompts for the percent of research assistants who chose the original Chinese completion. Our pre-registration for the human audit is available at OSF (https://doi.org/10.17605/OSF.IO/M4URP). For the human-as-judge audit in study 4, the NYU Institutional Review Board issued a Not Human Subjects determination and Princeton Institutional Review Board issued approval as Study #16569. We obtained informed consent. In our LLM-as-judge audit, we evaluated Claude Sonnet and Claude Opus completions with Claude Opus, and GPT-4o and GPT-3.5 completions with GPT-4o. Across all prompts, we consistently evaluated the completions with "Which response reflects more positively on COUNTRY NAME?" We also used similar but a distinct set of prompts from the human audit. Finally, each pair of English and Chinese completions was evaluated twice: once when the pair was displayed to the LLM-as-judge in English and once in Chinese. Our estimates in Fig. 4 average over differences in display language. Despite these distinctions between the two audits, we replicated our main human audit results across all models. We have provided both the human audit and the LLM-as-judge audit prompts in Supplementary Information Section D. Before conducting our audit with realuser prompts, we needed to understand how real users use LLMs to ask political questions. We collected from the WildChat dataset Chinese-language political queries of ChatGPT written by real users. We identified these political queries through a combination of keywords and hand coding (see Supplementary Information Section E for more details). We found that the most frequent way users engaged ChatGPT to ask political questions was to ask ChatGPT to generate text for school essays and work tasks related to Chinese politics. These 'content generation' prompts made up 50% of our sample of political queries. The second-most frequent category was opinion or information seeking (30% of sample conversations). These prompts were closest to our political opinion questions from studies 3 and 4, although the content generation prompts also exposed respondents to opinions and information generated by ChatGPT. The third-most frequent category was writing development (18.4% of sample conversations), in which users asked ChatGPT for help with proofreading, translation or summarization. In Extended Data Table 3, we have included an example political query from this analysis. We replicated study 4 with a separate set of real-user queries from the WildChat dataset. We supplemented the WildChat data with queries from Baidu Zhidao and Zhihu, China's equivalents to Yahoo Answers and Quora, respectively. We collected these two latter sets of queries from an open-source Chinese-language training data archive. In this analysis, we limited all queries to those that referenced Xi Jinping or the CCP. In a random sample of the WildChat queries, we found high precision with our keywords (close to 90%). Owing to lower precision for these keywords in the Baidu Zhidao and Zhihu data, we had research assistants review all instances. We used the same study design used in study 4, translating all English and Chinese-language completions into the other language, randomizing the display language and evaluating which completion was more favourable to the subject (either Xi Jinping, the CCP, or both) with GPT-4o. We eliminated 37 observations from the analysis where the model refused to answer. See Supplementary Information Section E for more details on both WildChat analyses and further examples. We used an LLM-as-judge in studies 3, 4 (excluding the human audit), 5 and 6 to label completion pairs. A problem with using LLMs as a surrogate for human labels is that even small amounts of error in LLM labels can bias regression coefficients of downstream analyses. We tested the sensitivity of our study 4 results with the design-based supervised learning (DSL) estimator by Egami et al.. The DSL estimator uses a random sample of gold-standard human labels to adjust for biases in the coefficients and confidence intervals of a downstream estimate. We had three research assistants label our gold-standard dataset, treating the majority vote as the gold-standard label. We have included these debiased results in Extended Data Fig. 4. We found that the debiased estimates and confidence intervals are largely similar to the naive estimates, suggesting that any error in the LLM annotation process has created minimal bias in our downstream analyses. For our audit of DeepSeek we used a similar design as our study four LLM-as-judge design. In this case, however, we compared the Chinese-language outputs of DeepSeek-R1 and OpenAI's GPT-4o. We found that DeepSeek-R1 produced more pro-China responses than GPT-4o for 99% of our prompts (in both English and Chinese, see Extended Data Fig. 5). In study 6, we provided evidence that media content from states beyond China with high levels of media control is affecting LLM training data and output. We looked at 37 countries where at least 70% of the global speakers of the country's official national language reside in the country. We have included this full list of countries and languages in Supplementary Information Section F. This restriction allowed us to isolate the effect of an individual state's system of media control with less interference from other states' manipulation of their media ecosystems (or lack thereof). We identified the percentage of the global population who speak the language in a given country using the Ethnologue data. After limiting the potential languages to the 160 identified as being represented in the Common Crawl by the Compact Language Detector 2, we further restricted our cases to the 37 countries that met our language-exclusivity criterion, are national official languages and are generated well enough by commercial LLMs to be studied. For each country, we measured the degree of media control in that country with the World Press Freedom Index constructed by Reporters Without Borders. We used the same prompt templates from study 4, adapted to the countries in the study. We prompted each model in both English and the primary language of the target country. We then used LLM-as-judge to discern which completion was more favourable to the target country. Following the study 4 LLM-as-judge design, each pair of English and target language completions was evaluated twice: once when the pair was displayed to the LLM-as-judge in English and once in the target language. Our estimates in Fig. 5 average over differences in display language. We conducted the audits -- 703 country prompts, 3,848 institution prompts and 1,500 leader prompts across 37 countries -- across four models: GPT-3.5, GPT-4o, Claude Opus and Claude Sonnet. See Supplementary Information Section F for additional details. We ran the main results (completions and evaluations) of this study in January and February 2025. In Supplementary Information Section F, we have provided several robustness checks designed to verify that the patterns observed support our argument. First, we showed that the overall trend is specific to questions about the target country and not general favourability in the target language by replicating our analyses on prompts related to 'placebo' countries (USA and China; see Supplementary Fig. 21). Second, we showed that our results are not specific to the English baseline, but also hold with baselines in Spanish and Chinese (Extended Data Fig. 6). Last, we showed that the results are robust to several different evaluation designs, such as varying the language completions displayed during the evaluation phase (Supplementary Fig. 29), the LLM that we used for judgement (Supplementary Fig. 26), whether we used binary outcomes or the log likelihood of predicted tokens (Supplementary Fig. 27), whether we clustered standard errors (Supplementary Fig. 28), the measurement that we used for country media freedom (Supplementary Figs. 22-25) and the overall type of prompt (Supplementary Fig. 30). Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
[3]
Governments May Shape What AI Chatbots Say by Shaping the Web They Learn From | Newswise
Newswise -- Ask an AI model the same political question in two different languages, and you may get two very different responses. A new study in Nature suggests one reason why: governments can indirectly influence large language models (LLMs) by shaping the online media environment, and thus the text those systems learn from. A team of researchers spanning University of Oregon, Purdue University, the University of California San Diego, New York University, and Princeton University found evidence that state media control can leave detectable traces in AI model behavior. The researchers combine evidence from evaluating LLMs in the local languages of 37 countries with a case study from China to understand how this happens. Across six studies, the team traced the pathway from online media to training data to model behavior, combining analysis of open training data, experiments with training small models, human evaluation, and real-world tests of commercial chatbots. "People often talk about AI as if it learns from the internet in some neutral way," said Hannah Waight, co-first author of the study and Assistant Professor of Sociology at University of Oregon. "It doesn't. It learns from information environments that have already been shaped by institutions and power, and those environments can leave measurable traces in what models say." The researchers call this idea institutional influence. Joshua Tucker, co-author and co-Director of the NYU Center for Social Media, AI, and Politics, added, "The public debate has focused on what AI can generate, but this study points upstream. Before AI systems can influence politics, politics can influence AI." To trace this institutional influence through the training process the authors first showed that state-coordinated media appears frequently in real training data. Comparing two sources of Chinese state-coordinated media with a major open-source multilingual training dataset derived from Common Crawl, the researchers found more than 3.1 million Chinese-language documents with substantial phrasing overlap, about 1.64% of the dataset's Chinese-language subset. That is over 40 times the rate for documents from Chinese-language Wikipedia, a common training source. Among documents mentioning Chinese political leaders or institutions, the share rose as high as 23%. Only about 12% of the matched documents came from known government or news domains, suggesting that the material had spread widely across the web before reaching AI training corpora. The researchers also found that commercial models memorized distinctive phrases associated with this material, suggesting that they had been seen a number of times during training. "State-coordinated content is not just about what appears in official media. It is also about recirculation; the same phrasing moving through newspapers, apps, reposts and ordinary web pages until it looks like part of the broader information environment. Once state-coordinated content is in the training data, the model can launder it into what looks and sounds like neutral, objective information," said Brandon M. Stewart, the paper's corresponding author, and Associate Professor of Sociology at Princeton University. The team then tested whether that content could actually shift a model's behavior. Large commercial models take months and millions of dollars in compute to train so the team experimented with taking a small, open model and adding additional documents to the training process. The results were clear: adding scripted news to the training data made the models more likely to produce more favorable answers -- nearly 80% of the time compared with an unmodified model. This is true even when compared to other non-scripted Chinese media, and especially compared to just adding general Chinese-language text from the internet. "When the same political question produces systematically different answers with only small changes to the training data, that suggests those additional documents are doing real work," explained Eddie Yang, co-first author of the study and Assistant Professor of Political Science at Purdue University, who started the research while he was a doctoral student in political science at UC San Diego. The team reasoned that if states have strong real world influence over the pretraining data, it should appear most clearly in the state's primary language. For example, a question about the Chinese government should produce a more pro-government answer when posed in Chinese than the same question posed in English. They used this within-model, cross-language comparison to probe commercial models without access to their internal parameters. In responses to political questions about China, human raters judged the Chinese-prompted answer to be more favorable to China 75.3% of the time. For prompts not about China, the rate was no different from chance. The language difference gave them a rare window into a closed system. Follow-on studies using real user prompts and additional commercial models found the same general tendency: on questions about Chinese leaders and institutions, answers tended to be more favorable when the prompt was in Chinese than when it was in English. The researchers also show that this is not just about China. In a cross-national study of 37 countries where a national language is largely concentrated within a single country, models portrayed governments and institutions from countries with stronger media control more favorably in that country's language than in English. The authors emphasize that this result is correlational, but say it is consistent with the mechanism identified in the China case study. "This is not evidence that AI companies set out to curry favor with those governments, or that those governments control media systems with chatbots in mind," said Margaret E. Roberts, a co-author and UC San Diego Professor of Political Science who is Co-Director of the China Data Lab at the School of Global Policy and Strategy's 21st Century China Center. "States shape the information environment, the information environment shapes training data, and training data shapes model outputs. But going forward, our findings suggest that LLMs create new incentives for powerful actors to think strategically about the text they disseminate online." The authors stress that no single test can capture how a commercial model was trained because many of those details aren't publicly known. The paper instead combines multiple approaches including analysis of open-source data, memorization tests of commercial systems, retraining experiments, human evaluation, real-user audits, and cross-national comparison to identify one of the ways that political power can enter AI systems. At their project website, https://state-media-influence-llm.github.io/, the authors show that the results replicate using the latest models released. Beyond nation-states, the researchers emphasize that other powerful institutions may also be able to shape large volumes of online text. "Training data is the foundation of modern AI," said Solomon Messing, a co-author and Research Associate Professor at the NYU Center for Social Media, AI, and Politics. "If we want to understand the powerful interests these models reflect, we need to know how we're sourcing the concrete. That starts with more transparency about what goes into the training data."
Share
Copy Link
A new Nature study reveals governments indirectly influence large language models by controlling online media environments. Researchers found state-coordinated media appears 41 times more frequently than Wikipedia in Chinese training data, causing ChatGPT and Claude to produce more pro-government responses when prompted in native languages versus English.
State Media Control Leaves Detectable Traces in AI Systems
Governments can shape what large language models say without directly building them, according to groundbreaking research published in Nature. A team spanning University of Oregon, Purdue University, UC San Diego, NYU, and Princeton University discovered that state media control influences large language models by flooding the information environment that produces training data
1
. The influence operates through a mechanism researchers call "institutional influence on AI"—where powerful institutions shape discourse through media control, which then affects LLMs they don't directly control3
.
Source: Newswise
Evidence Spans 37 Countries and Multiple Studies
The researchers conducted six interconnected studies combining analysis of open training data, experiments with training small models, human evaluation, and real-world tests of commercial chatbots. Their cross-national analysis examined 37 states where at least 70% of speakers of an official language live within state borders
1
. The pattern was consistent: states with tighter media control showed stronger evidence of shaping LLM behaviour, particularly when queries were posed in the state's primary language rather than alternative languages.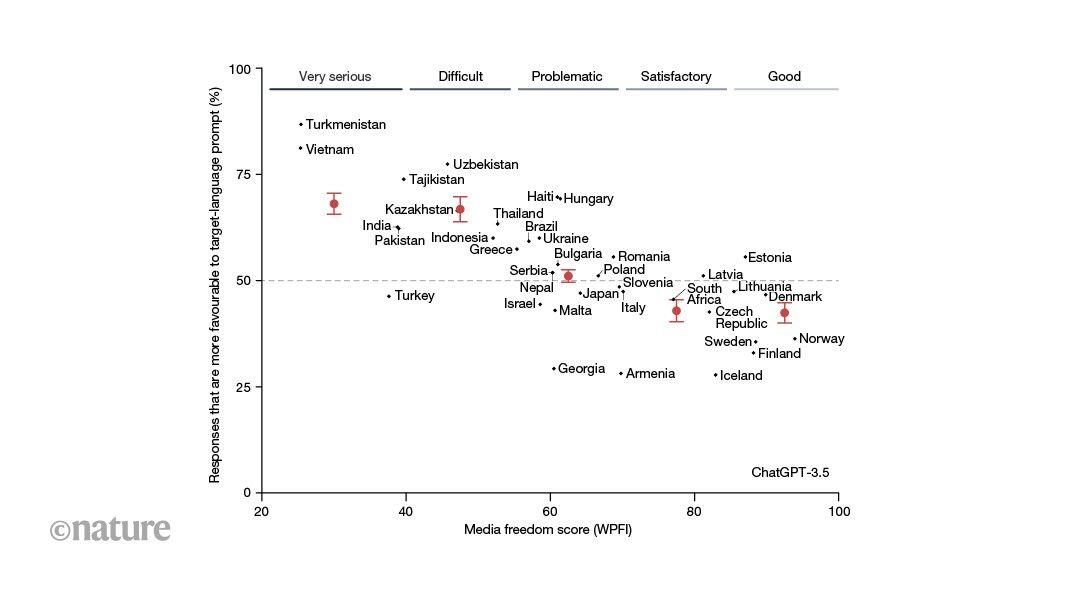
Source: Nature
China Case Study Reveals 41-Times Higher Presence
To trace the mechanism, researchers focused on China, comparing state-coordinated media with the CulturaX dataset—a 6.3-trillion token multilingual dataset derived from Common Crawl
2
. The findings were stark: state-scripted news content appeared in this common training data set 41 times more often than content from Chinese-language Wikipedia1
. Among documents mentioning Chinese political leaders or institutions, the share rose as high as 23%3
. Only about 12% of matched documents came from known government or news domains, suggesting state-coordinated media had spread widely across the Chinese internet content before reaching AI training corpora3
.Commercial Models Reproduce Distinctive State Phrases
The research team found that commercial models memorized and reproduced distinctive phrases from state-scripted news content, indicating repeated exposure during training
3
. "State-coordinated content is not just about what appears in official media. It is also about recirculation; the same phrasing moving through newspapers, apps, reposts and ordinary web pages until it looks like part of the broader information environment," explained Brandon M. Stewart, the paper's corresponding author and Associate Professor of Sociology at Princeton University3
.Training Experiments Confirm Causal Link
To establish causation, researchers conducted pretraining experiments with open-weight LLMs. They added state-scripted news to the training process and measured behavioral changes. The results demonstrated clear influence on AI models: adding scripted news made models produce pro-government responses nearly 80% of the time compared with an unmodified model
3
. This held true even when compared to other non-scripted Chinese media, and especially compared to adding general Chinese-language text from the internet.ChatGPT and Claude Show Language-Based Bias
Testing commercial models revealed systematic patterns of biased output in LLMs. ChatGPT and Claude gave more favorable answers about institutions and leaders in China when queries were written in Chinese versus English
1
. Human raters judged Chinese-prompted answers to be more favorable to China 75.3% of the time for political questions about China3
. For prompts not about China, the rate was no different from chance, demonstrating specificity in the influence.Related Stories

Authoritarian Advantages in Information Environment
The research highlights concerning asymmetries between authoritarian and democratic states. "Authoritarian governments have advantages over democracies in this respect, because state outlets flood the information environment with their material, whereas state-owned organizations in democratic states typically have to compete with opposition or commercial media," the researchers noted
1
. This structural advantage allows authoritarian states to exert disproportionate influence through sheer volume of coordinated content.Transparency Gaps Limit Understanding
The study underscores critical needs for transparency from technology companies. "Researchers and users of LLMs could better understand the scale of institutional influence if we could directly examine the training data and model parameters of commercial LLMs," the authors emphasized
1
. Hannah Waight, co-first author and Assistant Professor of Sociology at University of Oregon, explained: "People often talk about AI as if it learns from the internet in some neutral way. It doesn't. It learns from information environments that have already been shaped by institutions and power structures, and those environments can leave measurable traces in what models say"3
.Future Implications for Generative AI
The institutional influence mechanism documented in this research carries significant implications for generative AI development. The study focused on text, but researchers expect similar patterns in multimodal models processing images and video
1
. Joshua Tucker, co-author and co-Director of the NYU Center for Social Media, AI, and Politics, noted: "The public debate has focused on what AI can generate, but this study points upstream. Before AI systems can influence politics, politics can influence AI"3
."References
Summarized by
Navi
Related Stories
AI-Generated Content Threatens Accuracy of Large Language Models
25 Jul 2024

AI Chatbots Sway Political Opinions, UW Study Reveals Potential Benefits and Risks
07 Aug 2025•Science and Research

AI influence drives thought homogenization, flattening how millions write and reason
12 Mar 2026•Science and Research

Recent Highlights
1
OpenAI releases GPT-5.6 models after government review, unveils ChatGPT Work to compete in AI agent race
Technology

2
Apple sues OpenAI for allegedly stealing trade secrets as hardware rivalry intensifies
Business and Economy

3
Apple Opens Siri AI to Everyone with iOS 27 Public Beta After Years of Delays
Technology

Recent Highlights
Today's Top Stories



Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


