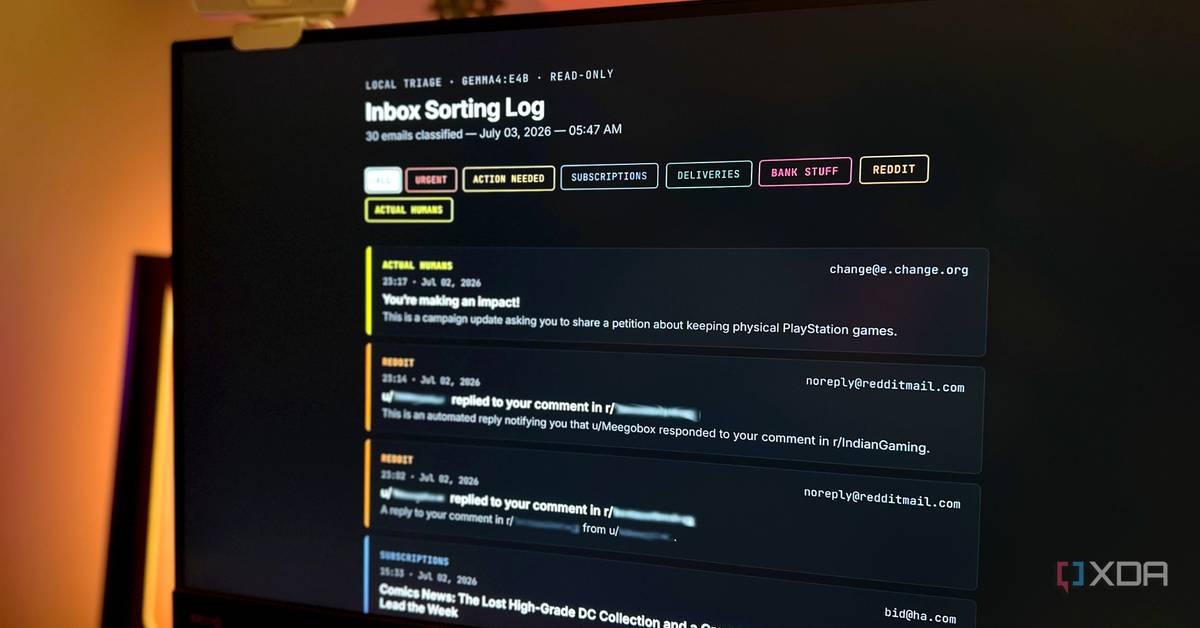
Users ditch bloated AI wrappers for llama.cpp and Ollama as LLMFit solves compatibility issues
4 Sources
[1]
Stop guessing which local AI models fit your hardware -- this free tool does it for you
Gaming has been Samarveer's greatest passion, and the Literature graduate in him takes immense joy in dissecting games for their themes, messages, and impact. Samarveer holds a deep appreciation of gaming, and considers the platform to be the most immersive and impactful across all media. He can be found engaging with gaming communities online, always ready to debate the finer points of ray tracing or itching to write an 8-page collegiate thesis on any game that impacts him emotionally. If you've ever spent any amount of time experimenting with local AI models, you've almost certainly experienced the same cycle I have. You find an exciting new model, fire up Ollama or Hugging Face, wait for the download to finish, only to find out that the new model either crawls along at two tokens per second, or just refuses to fit into memory. Between my laptop, gaming PC, my partner's PC, and the occasional test bench, if I had a dollar for every time that happened, I'd have at least enough to pay for half a month's worth of Claude Pro. This is where LLMFit comes in. Instead of leaving you to guess which models your hardware can handle as you scratch your head looking at different quantizations and parameter counts, LLMFit analyzes your system and recommends the AI models that should run well. Plenty of cloud AI users are slowly moving over to self-hosting their local AI models, and if you're one of them, LLMFit should be the first thing you use to get a proper lay of the land. 5 things I wish someone had told me before I tried self-hosting a local LLM It's more capable than you might realize, but tapering expectations is key Posts 6 By Ty Sherback LLMFit takes the guesswork out of running local AI models It's a hardware-aware recommendation engine for local LLMs LLMFit is essentially a recommendation engine for local AI models that makes your job a lot easier if you're getting into self-hosted AI. Before you commit to a massive download for a 10-, 15-, or 20-GB model, it figures out whether your hardware can realistically handle such a model first. Once you install and run it, LLMFit will evaluate your CPU, GPU, and available RAM and VRAM before ranking over 250 models according to how well they'll perform on your machine. The star of the show here is the "Fit" score, which rolls speed, context length, and quality all into one to score a model out of a hundred points. So, instead of forcing you to decipher pages of benchmarks, it will give you a practical shortlist of models that are actually worth your time. Sure, if you're sitting on a workstation with enough VRAM to make enterprise AI labs blush, you'll have no shortage of options anyway, but for the rest of us working within the confines of consumer hardware, this is exactly the kind of problem LLMFit exists to solve. It doesn't stop at recommendations, either. LLMFit integrates directly with Ollama and llama.cpp, so once you've found a model that fits the bill, you can launch it without bouncing between different applications. Alongside each recommendation, there's something particularly helpful for newcomers, which is a workload label -- the tool tells you whether a model you're eyeing is best suited for coding, chat, image generation, or MoE (mixture of experts) tasks. That directly translates into less time Googling model names, and more time actually using them. I ran local AI models on a six-year-old laptop with no GPU, and they actually worked Your old laptop is powerful enough for local AI... if you temper expectations Posts 1 By Samarveer Singh How to install LLMFit on your Windows device Just three commands to get started To install LLMFit on your device, the first thing you need on a Windows machine is Scoop. Scoop is a well-trusted command-line installer for Windows. To install Scoop, simply paste the following line of code into an elevated PowerShell window: Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser Here, odds are you'll either see no response and the command will work properly, or PowerShell will ask you if you want to change the execution policy. Press Y and hit Enter. Copy the next line into the same window: Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression This will install Scoop on your Windows device. The next thing you need to do is to open a Command Prompt window and simply type in the following: scoop install llmfit With that, LLMFit is installed on your device. Just type in llmfit into a CMD or PowerShell window, and it will immediately pop up with all its data on local AI models that you can install and run on your device. Local LLMs weren't enough, so I use a two-tier system that keeps my sensitive stuff offline Private data stays local, smarter AI comes later. Posts 1 By Yash Patel I tested LLMFit on a six-year-old laptop It told me exactly which model worked best Once I installed LLMFit on my six-year-old laptop, it quickly detected the hardware and listed models that it thought would work best on it. This is an old Mi laptop bought in 2019, with all of 8GB RAM, and an Intel i5-10210U CPU running at 1.60 GHz. In the graphics department, it's got nothing to boast other than Intel UHD integrated graphics. Even on this old piece of hardware, LLMFit only took a handful of seconds to be up and running after it detected my device's capabilities. LLMFit is a keyboard-only tool. It operates operates like an old motherboard BIOS interface. LLMFit gave Microsoft's Phi-mini-MoE-instruct model an impressive 90.4 out of 100 on the composite score, listing it at the very top of the list for what would run best. The tool estimated that I would get around 40-42 tokens per second running this 7.6B-parameter model in llama.cpp, so I immediately downloaded the exact quantization LLMFit suggested (Q4_K_M). Subscribe to the newsletter for local AI model guidance Discover curated model picks by subscribing to the newsletter: hardware-aware recommendations, setup tips, and LLMFit-aligned suggestions to help you choose and run local AI models without guesswork. Get Updates By subscribing, you agree to receive newsletter and marketing emails, and accept our Terms of Use and Privacy Policy. You can unsubscribe anytime. Thankfully, there's the option to download a model directly from the tool itself, and with the press of the "d" key, I immediately downloaded the AI model from Hugging Face. When I ran it, I didn't quite get the tokens and speed LLMFit promised, but it was still in the 20-25 token-per-second category. The problem, however, came when I took a closer look at the laundry list of AI models inside the tool. A lot of those models listed are old and obsolete already, which immediately signaled to me that the app requires way more models updated into it and with much more frequency. As a stepping stone, however, I don't see the downside to installing LLMFit and using it with your hardware to get a lay of the land before downloading big AI models to use locally. LLMFit A terminal tool that right-sizes LLM models to your system's RAM, CPU, and GPU. Detects your hardware, scores each model across quality, speed, fit, and context dimensions, and tells you which ones will actually run well on your machine. See at Github Expand Collapse My local LLM can call Claude when it's stuck, and it changed everything about my local-first setup Local LLMs aren't very good on their own Posts 14 By Anurag Singh Should everyone using local AI models use LLMFit? Until you learn how parameter counts and quantizations affect your hardware, LLMFit removes most of the trial and error. For me, LLMFit is best viewed as a stepping stone rather than a tool you'll rely on forever. It only takes a few weeks of experimenting with local AI before you develop a good feel for your own hardware. Once you learn how parameter counts, quantizations, and memory requirements affect performance, you'll also start making educated guesses yourself. Until you reach that point, though, having a tool that removes most of the trial and error is genuinely valuable. It gives you the confidence to download models knowing there's a good chance they'll perform the way you expect. That became especially clear when I helped a friend dip their toes into local AI on an Acer Nitro 5 with an RTX 3050 Laptop GPU. We didn't have to download endless models and go through all of them to see which worked best. LLMFit just immediately surfaced models that made sense for the hardware and paired perfectly with Ollama, llama.cpp, and other self-hosted front ends. More than anything, though, it smooths out those first few self-hosting adventures, replacing frustration with momentum and helping newcomers build a solid foundation without wasting hours on models that were never going to run well in the first place.
[2]
Most people use Ollama or llama.cpp for local LLMs, but these are the tools I switch to when it gets serious
Ollama has become the default answer when someone asks how to run a local LLM, and for good reason. It's easy, it works across platforms, and it hides enough of the ugly parts that you can go from nothing to a working model in minutes. llama.cpp sits underneath a huge amount of the local AI world too, especially if you're using GGUF models, so neither one is going away. The problem is that the easy button stops being enough once a local model becomes part of a workflow. You start caring about serving APIs, batching, structured outputs, cache behavior, Mac-specific acceleration, mobile deployment, or whether you're silently leaving performance on the table. I still think Ollama is the easiest way to start running local LLMs, but it's not where I want to stay when I'm building something more serious. The alternatives are messier, but they give you control over the parts Ollama tries to hide. If you're running agents, pointing several apps at the same model, working on a Mac, or trying to make a consumer GPU behave like a proper inference box, the runtime starts to matter as much as the model. vLLM and SGLang turn local models into infrastructure Serving a model is different from chatting with one vLLM is the first tool I'd look at when you want a local model to act less like a desktop app and more like an inference service. It has an OpenAI-compatible API server, high-throughput inference, continuous batching, prefix caching, chunked prefill, structured outputs, tool calling and reasoning parsers, and support for a lot of quantization formats. Those features matter when the model is being called by coding tools, agents, RAG experiments, or multiple apps at once. A single prompt in a terminal doesn't need much scheduling logic, but a local endpoint being hit repeatedly certainly does. Especially when those requests share context, run long, or need to avoid wasting VRAM on cache management. vLLM's best-known feature is PagedAttention, which manages the model's key-value cache more efficiently. The goal is to keep GPU memory from becoming the bottleneck when multiple requests are active or when context gets large. It's not going to make every local setup faster, but it's the reason why vLLM shows up so often across the internet, especially in higher-throughput deployments. SGLang sits in the same broad category, but its identity is more tied to structured generation, repeated prompt patterns, and agent-style workloads. Its feature list includes RadixAttention for prefix caching, prefill-decode disaggregation, speculative decoding, continuous batching, paged attention, chunked prefill, tensor and expert parallelism, and multi-LoRA batching. Free-form prose is fine in a chat box, but it becomes a problem when your program expects JSON, a schema, or a tool call in a particular format. SGLang is built for repeated prompts, constrained outputs, and cache reuse, which are all much easier to care about once the model is driving tools instead of just answering questions. I wouldn't install either of these before getting acquainted with simpler tools, as they add quite a bit of setup work and assume a certain level of understanding to use. However, they make the most sense once you're using other software that expects a more enterprise-esque endpoint. If your local LLM has become backend infrastructure for your home lab, vLLM and SGLang are closer to the right shape of what you need. vMLX gives Macs a more serious local app Apple Silicon doesn't need to pretend it's CUDA Mac users have always had a slightly different local LLM story. Apple Silicon's unified memory makes large models more practical than you might expect on a laptop, but the software stack isn't the same as it is on a Linux box with an Nvidia GPU. You can run llama.cpp with Metal, and that works well, but there are good reasons to want tools built with Apple's stack in mind from the start. vMLX is interesting because it aims to sit closer to the app experience people want from Ollama or LM Studio, while borrowing ideas from more serious serving stacks. Its own pitch calls out prefix caching, paged KV cache, continuous batching, and MCP tools. It's a very different pitch from "download a model and chat with it," and it's why it deserves to be treated as more than just another Mac wrapper. MLX is Apple's array framework for Apple Silicon, with lazy computation, dynamic graphs, CPU/GPU execution, and a unified memory model where arrays live in shared memory. MLX-LM then gives you text generation, Hugging Face integration, quantization, and fine-tuning on top of that, while MLX-VLM covers vision-language models on the same general stack. vMLX is the app-level tool, while MLX-LM and MLX-VLM are the lower-level options when you want to work closer to the model. Granted, I wouldn't describe any of this as a universal replacement for vLLM or SGLang, because it isn't, but it's still a great tool to have if you're a Mac user. vMLX is best understood as the Mac-native path through the local LLM world, rather than a CUDA tool awkwardly mapped onto Apple Silicon. The memory model, GPU stack, and app expectations are different enough that native tools like these can genuinely provide benefits. MLC-LLM and ExLlamaV3 target specific hardware problems Phones, browsers, and consumer GPUs don't all want the same runtime MLC-LLM is built around machine-learning compilation and deployment across a variety of different platforms. Its support includes web browsers through WebGPU and WASM, iOS and iPadOS through Metal on Apple A-series GPUs, and Android through OpenCL on Adreno and Mali GPUs. MLC fills a different role from a normal server runtime, even though it can expose OpenAI-compatible APIs. It's built for more niche use-cases, and WebLLM runs inference directly in the browser with WebGPU acceleration and no server. It also supports streaming, JSON mode, and structured JSON generation. MLC isn't what I'd pick for serving a big model to a home lab full of apps. Its appeal is deployment into places that don't look like normal LLM hosts: places like browsers, phones, tablets, and embedded apps. It's aimed at a totally different class of local AI projects than what vLLM and SGLang are aimed at. Deals Save on Computers & Work Setup Deals for Local AI Explore deep savings on desktops, laptops, GPUs, RAM, storage, and networking gear to build a faster local LLM workstation. Score bundle discounts on peripherals and accessories that streamline development, inference, and multi-app deployments - shop deals now. Deals Explore Computers & Work Setup Deals ExLlamaV3 is specialized in the other direction. It's the current version of the ExLlama line now that ExLlamaV2 is archived, and it's esssentially an inference library built specifically for running local LLMs on modern consumer GPUs. The priorities are fitting the model, keeping context usable, avoiding wasted VRAM, and getting acceptable speed without enterprise hardware. Its EXL3 quantization format, tensor-parallel and expert-parallel inference for consumer hardware, continuous dynamic batching, speculative decoding, cache quantization, multimodal support, and LoRA support are all built for that goal. TabbyAPI gives it an OpenAI-compatible server too, so it can still slot into apps that expect a normal local endpoint. There's more than just Ollama and llama.cpp out there Try something more specialized If you deploy your own local LLMs, Ollama and llama.cpp are both fine to start with and even continue with. However, if you find yourself wanting more, there's a whole world out there of software you can try out that might be better suited to your needs. For example, MLC and ExLlamaV3 don't solve the same problem, but both are more specialized than Ollama. MLC is for deployment across awkward targets. ExLlamaV3 is for getting more out of a consumer GPU. They're not the first tools I'd recommend to someone starting out, but they make sense once your hardware or deployment target starts dictating the runtime. Then there's llama-swap, part of the llama.cpp package of model serving tools, and it's useful if you run multiple OpenAI or Anthropic-compatible local servers and want a routing layer between them. Then there's TensorRT-LLM, which is the optimized path made by Nvidia for Nvidia cards, LMDeploy is a real serving and deployment toolkit, Lemonade is a model serving platform built with AMD in mind, KTransformers handles heterogeneous CPU/GPU inference, and LocalAI covers more modalities and hardware targets. Ollama is still the tool I'd point someone to if they just want to get started. llama.cpp is still foundational, and dismissing it as basic would be unfair given how much it can do on its own. But once local models become part of a real workflow, the runtime is no longer merely a stepping stone. The server, cache, batching model, quantization path, and platform backend start deciding what you can actually build.
[3]
I switched from LM Studio to llama.cpp, and I'm never going back to a bloated wrapper
Aggy is a veteran writer and editor in the technology and gaming space. Having served as a Managing Editor for high-traffic digital publications, alongside being an editor and consultant for over a dozen sites. Aggy's published work spans a wide and respected array of tech and gaming outlets, including WePC, Screen Rant, How-To Geek, Android Police, PC Invasion, and Try Hard Guides. Beyond editorial work, Aggy's direct experience in the tech sphere extends to app development. Aggy has published two games under Tales and is always eager to learn and do more. He also likes working on computers and researching in his spare time. He knows about Windows, Linux, Audio, Video, and much more. Running AI locally sounds like it should be straightforward until you realize that the app making it feel easy is quietly eating the resources you actually need. I spent time with LM Studio before I started noticing that my hardware was working harder to keep the interface alive than to run the model itself. However, Llamma.cpp is much better and can even run on Raspberry Pi. LM Studio has too much bloat I ditched the heavy wrappers for raw llama.cpp When I started running AI locally, I gravitated toward tools like LM Studio. It is pretty easy to see why, since it is very popular thanks to its model search, downloading, and chat interface. It doesn't feel much different than using any other app on your computer, and you don't even need a NAS. All that convenience comes at a price, though, because the packaging just hides what is actually doing the work. LM Studio, Ollama, and GPT4All are all local AI running the same core engine underneath, which is llama.cpp. What is different is everything that is built around that engine. Heavy GUI managers force your OS to burn memory and CPU cycles just to keep the interface alive. My hardware was spending its budget rendering visual elements and maintaining API translation layers instead of doing the actual AI work. I didn't spend long on LM Studio because it was clearly going overboard. The main culprit is that most of these managers are built on Electron, which ships a full Chromium browser engine bundled with a Node.js runtime. That's expensive even when the AI isn't doing anything. In practice, LM Studio alone can sit at 1.40 GB of RAM and pull up to 1.2 GB of GPU VRAM just as background overhead. On an 8 GB card, that's not a minor inconvenience; it directly determines which models you can even load. Every megabyte the wrapper takes is a megabyte the model doesn't get. Running llama.cpp as a native binary cuts all of that out. While other AI may force your PC to waste memory just from the empty UI, llama.cpp keeps its background footprint down low. When it is running, it doesn't have to be more than a regular browser. Wrappers also add latency. You get prompt ingestion, which is just the wait time before you see the first token. There was a noticeable difference between running llama.cpp and using LM Studio. Bypassing the wrapper fixed that. There's another upside, too, because llama.cpp moves fast, and GUI tools always lag behind its release cycle by weeks. Running it directly means new features like multi-modal audio inputs are available the moment they ship. Command-line tools are simpler than they seem You get real control for a smaller learning curve The learning curve of a command-line interface can feel intimidating coming from a GUI. I remember that I had thought that any time I was using a command line, I was likely going to break something on the PC. However, if you switch to raw llama.cpp it's worth learning. To get llama.cpp running on your PC, you need files from two places, pull them both into the same local folder, and you're basically done. Start at the llama.cpp GitHub repository. Go to the latest release and download the pre-compiled zip that matches your hardware. Create a folder somewhere convenient and unzip everything into it. Then head to Hugging Face, grab whichever model you want in GGUF format, but a lighter one is smarter for testing, and drop that file into the same folder. To run it, type cd then the path from the folder. Then name the AI in a script with the first prompt, and you can start talking. Make sure to use the launch string with the model filename before your first prompt. Here is what I used llama-cli -m meta-llama-3-8b-instruct.Q4_K_M.gguf -ngl 99 -p "Why is running AI via raw llama.cpp better than a heavy GUI wrapper?" The performance difference is hard to ignore once you see it. Idle VRAM usage drops from several gigabytes to a fraction of one. Prompt processing speeds jump significantly enough that I noticed it on the first request. Stripping out the GUI and tuning things yourself sounds complicated, but you will definitely see the difference. The trade-off is worth it The performance gains make it hard to go background It's easy to see why someone would argue that a GUI is better for beginners. Apps like LM Studio offer a comfortable, pick-up-and-play experience that hides the messy side of deployment. If you're really that into a GUI, I'd recommend GPT4All over LM Studio because it's not as restrictive or hard on your PC. You can make this look like a regular chatbot if you run the code with your model and then -ngl 99 and the URL is http://localhost:8080. It just won't run as well. To most people, running a language model through a terminal looks like developer territory. Learning to go through directories and set execution parameters takes time, and that can put people off. Convenience would be why you'd head to heavy wrappers. However, treating local AI like a casual desktop app means paying a real performance price for all that graphical overhead. I'm not willing to give up over a GB of VRAM just to keep an interface running. It is a huge waste. Learning the llama.cpp interface removes all of that, and you only have to learn it once. After that, your machine can focus on the actual work. Now that I am used to the speed and control, going back to a heavy interface feels like a genuine step backward. It feels like giving up performance just for a pretty interface. Since llama.cpp includes a built-in web server, it's not like you're stuck staring at a terminal either. A little work learning a few commands gets you a much faster, cleaner setup. The terminal is the difference maker Switching to raw llama.cpp isn't for everyone. If you're not comfortable working from a terminal yet, the learning curve is real, even if it's shorter than it looks. GPT4All is a more reasonable starting point than LM Studio if you want a GUI that doesn't punish your hardware for existing. That said, once you've run a model without the wrapper overhead even once, it's hard to unsee the difference. For a lot of setups, it's the difference between loading the model you actually want and settling for something smaller. Surface Laptop 4 If you want a laptop with a touch screen that's not a 2-in-1, the Surface Laptop 4 is your best option. With all models having a touch screen and a long battery life, this is a solid choice. See at Amazon See at Microsoft Expand Collapse
[4]
I stopped fighting LM Studio's model UI and switched to Ollama -- setup took minutes instead of hours
I've been running local LLMs for quite some time now, and LM Studio is one of the best apps to enjoy the benefits of a local LLM on your machine. It's polished, has a nice model browser, and it makes downloading models from Hugging Face feel almost effortless -- until it doesn't. Model downloads can sometimes get stuck, and the frustrating ritual of manually unloading one model, reconfiguring the GPU layers, and reloading another is not an enjoyable process to go through. But LM Studio isn't the only local LLM app that's easy to use, and setting up Ollama might just save you precious hours. I stopped using LM Studio once I found this open-source alternative LM Studio had competition. I found it. Posts 6 By Yadullah Abidi The simplest way to run local AI What Ollama is and why it exploded in popularity Ollama is a lightweight, open-source runtime for running LLLMs locally. While LM Studio gives you a full desktop GUI with model browsing, chat tabs, and server controls, Ollama strips everything down to a clean command-line workflow and a local HTTP API. It runs a background server the moment you install it, and everything else, from downloading models, switching between them, and querying them, happens via the terminal or through that API. There's also a minimalistic UI if that's what you prefer. If you've used Docker before, the model is almost identical. You pull an image -- or in this case a model -- and run it. Ollama pull [model name] fetches the model, ollama run [model name] runs it, and drops you right into an interactive chat. It might seem restrictive, but the entire process from a fresh install to chatting with a 7B model takes under five minutes on a decent connection. Ollama OS Windows, macOS, Linux Developer Ollama Price model Free, Open-source A lightweight local runtime that lets you download and run large language models on your own machine with a single command. See at Ollama Expand Collapse I was up and running in minutes A setup process that skips most of the usual friction Installing Ollama is a single curl command on Linux. On Windows, you can use the standard installer from Ollama's website. Once the install is complete, Ollama starts a background service automatically, and you're ready to pull models. The model library on Ollama's website covers everything you'd expect. Llama 3, Mistral, Gemma 3, Phi-4, DeepSeek, Qwen, and a growing list of others. You can copy the run command right from a model's page, paste it in your terminal, and Ollama handles the download and launch in one step. No navigating a model browser, no separate download queue, no waiting for an app to register the file in its internal catalog. Switching models is equally frictionless. There's no manual unloading that you have to do, and no memory management sliders to fiddle with. You just run a different model name, Ollama handles the rest in the background. The API is the real killer feature Why developers build entire workflows around Ollama To me, the most important part is the API. Ollama exposes an OpenAI-compatible Chat Completions endpoint at http://localhost:11434/v1. That means any tool or script already built for the OpenAI API works out of the box with your local models. You point the URL to localhost, set the API key to a dummy string (since it's not validated locally), and you're done. This is huge if you're building anything. I have a handful of Python scripts that call the OpenAI API for testing. Switching them to Ollama took about 30 seconds of the editing mentioned above. Change the base URL and model name, and no need to touch anything else in the code at all. By comparison, LM Studio does have a local server mode with similar compatibility, but getting it properly configured adds multiple steps and quite a bit of GUI navigation that Ollama simply doesn't require. You do lose a few conveniences The features and UI polish that LM Studio still does better Honestly, Ollama isn't for everyone. If you genuinely prefer browsing models visually, reading their metadata, and playing with parameters via a UI, LM Studio's Discover tab is a much better option for you. Ollama also doesn't give you real-time token throughput stats or a built-in chat interface as detailed as LM Studio's. Subscribe to the newsletter for practical Ollama tips Want hands-on Ollama workflows and local LLM how-tos? Subscribe to the newsletter for clear commands, API integration examples, and practical model-switching tips to improve your local model workflows. Get Updates By subscribing, you agree to receive newsletter and marketing emails, and accept our Terms of Use and Privacy Policy. You can unsubscribe anytime. LM Studio's catalog is also broader if you're looking at pure model management. It also handles pulling from Hugging Face directly and supports GPTQ formats that Ollama doesn't natively handle. Local LLMs are for using, not configuring If you're spending more time configuring AI than using it, try Ollama So that's where I landed: a terminal window, a tiny background service, and models that just work when I call them. No spinning program wheels, no half-loaded models, no mystery settings buried three menus deep. I still think LM Studio is great for beginners and for people wanting a rich GUI. But if you're looking for speed and the least amount of hassle for running your LLMs locally, Ollama is the way to go. The fix for local LLMs was never a bigger model; it was efficiency with the smaller ones. I'll never pay for AI again AI doesn't have to cost you a dime -- local models are fast, private, and finally worth switching to. Posts 7 By Yadullah Abidi The switch costs nothing and gives you back hours you could easily spend wrestling with LM Studio's loading behavior. For anyone primarily running local models to power scripts, tools, or integrations -- rather than chatting through a built-in GUI -- Ollama is the faster, leaner, and less frustrating path. The terminal isn't intimidating at all once you realize the entire workflow essentially boils down to two commands. Everything else follows naturally from there.
Share
Copy Link
The local AI landscape is shifting as users abandon resource-heavy GUI tools like LM Studio in favor of lightweight alternatives. A new open-source tool called LLMFit now analyzes hardware to recommend compatible models, while llama.cpp and Ollama deliver faster performance with minimal overhead. These command-line tools are proving that simplicity beats polish when running local large language models.
LLMFit Eliminates Hardware Guesswork for Local AI Models
Anyone experimenting with local AI models has likely faced the same frustration: downloading a 10-GB or 20-GB model only to discover it crawls at two tokens per second or fails to fit into memory entirely. This trial-and-error approach wastes time and system resources, but a new open-source tool called LLMFit aims to solve that problem before the first download begins
1
.
Source: XDA-Developers
LLMFit functions as a hardware-aware recommendation engine for running local large language models. After installation via the Scoop command-line installer on Windows, the tool evaluates CPU, GPU, available RAM, and VRAM before ranking over 250 models according to predicted performance on your specific machine
1
. The core feature is a "Fit" score that combines speed, context length, and quality into a single metric out of 100 points, providing a practical shortlist instead of forcing users to decipher benchmark pages.The tool integrates directly with Ollama and llama.cpp, allowing users to launch recommended models without switching between applications. Each recommendation includes workload labels indicating whether a model suits coding, chat, image generation, or mixture of experts tasks
1
. For those moving from cloud AI to self-hosted AI setups, LLMFit addresses a critical pain point in model management and hardware compatibility.GUI Wrappers Consume Resources Needed for Inference
While tools like LM Studio offer polished interfaces with model browsers and chat tabs, they come with substantial overhead that directly impacts performance. LM Studio and similar GUI wrappers are built on Electron, which bundles a full Chromium browser engine with a Node.js runtime
3
. This architecture can consume 1.40 GB of RAM and up to 1.2 GB of GPU VRAM as background overhead before any model even loads.
Source: MakeUseOf
On an 8-GB graphics card, that VRAM allocation isn't trivial—it directly determines which models can run at all
3
. Every megabyte the wrapper takes is a megabyte unavailable for the actual AI work. Users report that their hardware worked harder maintaining the interface than processing model inference, with noticeable latency added during prompt ingestion—the wait time before the first token appears.Running llama.cpp as a native binary eliminates this bloat entirely. The background footprint drops dramatically, and idle VRAM usage falls from several gigabytes to a fraction of one
3
. Prompt processing speeds increase noticeably on first use. Another advantage: llama.cpp updates quickly, while GUI tools lag behind its release cycle by weeks, delaying access to features like multi-modal audio inputs.Ollama Delivers Setup Speed and API Flexibility
Ollama has emerged as a lightweight alternative that strips away visual complexity in favor of speed and automation. This open-source runtime for local LLMs operates through a clean command-line workflow and local HTTP API, starting a background server automatically upon installation
4
. The entire process from fresh install to chatting with a 7B model takes under five minutes on a decent connection.The workflow mirrors Docker's simplicity: ollama pull [model name] fetches the model, ollama run [model name] launches it and drops users into an interactive chat
4
. Switching between models requires no manual unloading or memory management sliders—users simply run a different model name and Ollama handles background processes automatically.The standout feature is Ollama's OpenAI-compatible API exposed at http://localhost:11434/v1. Any tool or script built for the OpenAI API works immediately with local LLMs by pointing the URL to localhost and setting a dummy API key. Developers report switching existing Python scripts to Ollama in 30 seconds by changing only the base URL and model name, with no other code modifications required.
Related Stories
Advanced Tools Turn Local AI Models Into Infrastructure
For users moving beyond desktop experimentation toward production workflows, command-line tools like vLLM and SGLang offer capabilities that GUI wrappers cannot match. vLLM transforms local AI models into proper AI infrastructure with an OpenAI-compatible API server, high-throughput inference, continuous batching, prefix caching, and structured outputs
2
. Its PagedAttention feature manages the model's key-value cache more efficiently to prevent GPU memory from bottlenecking when multiple requests are active or context grows large.
Source: XDA-Developers
SGLang targets structured generation, repeated prompt patterns, and agent-style workloads with features including RadixAttention for prefix caching, prefill-decode disaggregation, speculative decoding, and multi-LoRA batching
2
. These capabilities matter when models drive coding tools, agents, or RAG experiments rather than simple chat interactions. Both tools assume a higher level of technical understanding but become essential once a local LLM functions as backend infrastructure.For Mac users, vMLX leverages Apple Silicon's unified memory architecture through Apple's MLX array framework rather than forcing CUDA-style workflows
2
. It incorporates prefix caching, paged KV cache, continuous batching, and MCP tools while working natively with the hardware's shared memory model. This approach makes large models more practical on laptops than typical consumer hardware might suggest.Why This Shift Matters for Self-Hosted AI Adoption
The move away from GUI wrappers toward command-line tools reflects a maturation in how people deploy local LLMs. What starts as curiosity-driven experimentation often evolves into workflow integration where system resources, latency, and API compatibility become critical factors. LLMFit lowers the barrier to entry by solving the hardware compatibility puzzle upfront, while llama.cpp and Ollama remove the performance penalties that GUI layers impose.
Users no longer need to choose between ease of use and efficiency. Ollama's installation takes minutes instead of hours of configuration, yet delivers the performance gains and API access that developers need for serious projects. The command-line interface that once seemed intimidating now appears simpler than navigating nested GUI menus and troubleshooting download queues.
As cloud AI users increasingly explore self-hosting options, these tools establish a practical path forward. LLMFit ensures hardware investments align with model requirements, while lightweight runtimes like Ollama and llama.cpp prove that local AI doesn't require enterprise-grade infrastructure—just smarter software that prioritizes model performance over interface polish.
References
Summarized by
Navi
[1]
[2]
[3]
Related Stories
Tech enthusiasts build local LLM servers on Raspberry Pi and phones, proving on-device AI works
17 Apr 2026•Technology
Developers ditch cloud AI for local LLM setups running on low-power hardware
30 May 2026•Technology

Developers ditch ChatGPT for local AI coding agents, saving $20+ monthly with powerful local LLM
02 May 2026•Technology

Recent Highlights
1
Xi Jinping positions China as global AI partner while challenging US tech dominance
Policy and Regulation

2
Chinese AI Models Have Trump Administration at War Over Control and National Security
Policy and Regulation

3
Apple releases Siri AI to everyone through iOS 27 public beta, marking biggest assistant overhaul
Technology

Recent Highlights
Today's Top Stories




Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


