Google's TurboQuant slashes AI memory usage by 6x while maintaining quality and speed
14 Sources
[1]
Google's TurboQuant AI-compression algorithm can reduce LLM memory usage by 6x
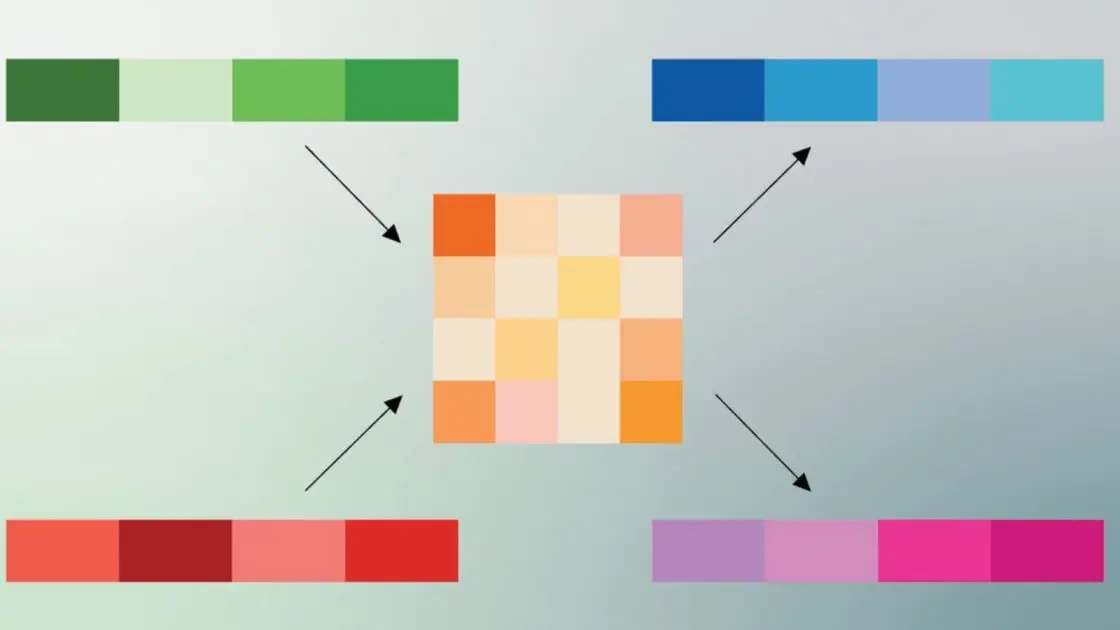
Even if you don't know much about the inner workings of generative AI models, you probably know they need a lot of memory. Hence, it is currently almost impossible to buy a measly stick of RAM without getting fleeced. Google Research recently revealed TurboQuant, a compression algorithm that reduces the memory footprint of large language models (LLMs) while also boosting speed and maintaining accuracy. TurboQuant is aimed at reducing the size of the key-value cache, which Google likens to a "digital cheat sheet" that stores important information so it doesn't have to be recomputed. This cheat sheet is necessary because, as we say all the time, LLMs don't actually know anything; they can do a good impression of knowing things through the use of vectors, which map the semantic meaning of tokenized text. When two vectors are similar, that means they have conceptual similarity. High-dimensional vectors, which can have hundreds or thousands of embeddings, may describe complex information like the pixels in an image or a large data set. They also occupy a lot of memory and inflate the size of the key-value cache, bottlenecking performance. To make models smaller and more efficient, developers employ quantization techniques to run them at lower precision. The drawback is that the outputs get worse -- the quality of token estimation goes down. With TurboQuant, Google's early results show an 8x performance increase and 6x reduction in memory usage in some tests without a loss of quality. Angles and errors Applying TurboQuant to an AI model is a two-step process. To achieve high-quality compression, Google has devised a system called PolarQuant. Usually, vectors in AI models are encoded using standard XYZ coordinates, but PolarQuant converts vectors into polar coordinates in a Cartesian system. On this circular grid, the vectors are reduced to two pieces of information: a radius (core data strength) and a direction (the data's meaning). Google offers an interesting real-world analogy to explain this process. The vector coordinates are like directions, so the traditional encoding might be "Go 3 blocks East, 4 blocks North." But using Cartesian coordinates, it's simply "Go 5 blocks at 37-degrees." This takes up less space and saves the system from performing expensive data normalization steps. PolarQuant is doing most of the compression, but the second step cleans up the rough spots. While PolarQuant is effective, it can create residual errors. Google proposes smoothing that out with a technique called Quantized Johnson-Lindenstrauss (QJL). This applies a 1-bit error-correction layer to the model, reducing each vector to a single bit (+1 or -1) while preserving the essential vector data that describes relationships. The result is a more accurate attention score -- that's the fundamental process by which neural networks decide what data is important. So does all this math work? Google says it tested the new algorithmic compression across a suite of long-context benchmarks using both Gemma and Mistral open models. TurboQuant apparently had perfect downstream results in all tests while reducing memory usage in the key-value cache by 6x. The algorithm can quantize the cache to just 3 bits with no additional training, so it can be applied to existing models. Computing the attention score with 4-bit TurboQuant is also 8x faster compared to 32-bit unquantized keys on Nvidia H100 accelerators. If implemented, TurboQuant could make AI models less expensive to run and less hungry for memory. However, the companies creating this technology could also use the newly freed-up memory to run more complex models. It'll probably be a mix of both, but mobile AI could see more benefit. With the hardware limitations of a smartphone, compression techniques like TurboQuant could improve the quality of outputs without sending your data to the cloud.
[2]
Google unveils TurboQuant, a lossless AI memory compression algorithm -- and yes, the internet is calling it 'Pied Piper' | TechCrunch
The joke is a reference to the fictional startup Pied Piper that was the focus of HBO's "Silicon Valley" TV series that ran from 2014 to 2019. The show followed the startup's founders as they navigated the tech ecosystem, facing challenges like competition from larger companies, fundraising, technology and product issues, and even (much to our delight) wowing the judges at a fictional version of TechCrunch Disrupt. Pied Piper's breakthrough technology on the TV show was a compression algorithm that greatly reduced file sizes with near-lossless compression. Google Research's new TurboQuant, is also about extreme compression without quality loss, but applied to a core bottleneck in AI systems. Hence, the comparisons. Google Research described the technology as a novel way to shrink AI's working memory without impacting performance. The compression method, which uses a form of vector quantization to clear cache bottlenecks in AI processing, would essentially allow AI to remember more information while taking up less space and maintaining accuracy, according to the researchers. They plan to present their findings at the ICLR 2026 conference next month, along with the two methods that are making this compression possible: the quantization method PolarQuant and a training and optimization method called QJL. Understanding the math involved here is something researchers and computer scientists may be able to do, but the results are exciting the wider tech industry as a whole. If successfully implemented in the real world, TurboQuant could make AI cheaper to run by reducing its runtime "working memory" -- known as the KV cache -- by "at least 6x." Some, like Cloudflare CEO Matthew Prince, are even calling this Google's DeepSeek moment -- a reference to the efficiency gains driven by the Chinese AI model, which was trained at a fraction of the cost of its rivals on worse chips, while remaining competitive on its results. Still, it's worth noting that TurboQuant hasn't yet been deployed broadly; it's still a lab breakthrough at this time. That makes comparisons with something like DeepSeek, or even the fictional Pied Piper, more difficult. On TV, Pied Piper's technology was going to radically change the rules of computing. TurboQuant, meanwhile, could lead to efficiency gains and systems that require less memory during inference. But it wouldn't necessarily solve the wider RAM shortages driven by AI, given that it only targets inference memory, not training -- the latter of which continues to require massive amounts of RAM.
[3]
What Google's TurboQuant can and can't do for AI's spiraling cost
A positive outcome is making AI more accessible by lowering inference costs. With the cost of artificial intelligence skyrocketing thanks to soaring prices for computer components such as memory, Google last week responded with a proposed technical innovation called TurboQuant. TurboQuant, which Google researchers discussed in a blog post, is another DeepSeek AI moment, a profound attempt to reduce the cost of AI. It could have a lasting benefit by reducing AI's memory usage, making models much more efficient. Also: What is DeepSeek AI? Is it safe? Here's everything you need to know Even so, just as DeepSeek did not stop massive investment in AI chips, observers say TurboQuant will likely lead to continued growth in AI investment. It's the Jevons paradox: Make something more efficient, and it ends up increasing overall usage of that resource. However, TurboQuant is an approach that may help run AI locally by slimming the hardware demands of a large language model. The big cost factor for AI at the moment -- and probably for the foreseeable future -- is the ever-greater use of memory and storage technologies. AI is data-hungry, introducing a reliance on memory and storage unprecedented in the history of computing. TurboQuant, first described by Google researchers in a paper a year ago, employs "quantization" to reduce the number of bits and bytes required to represent the data. Also: Why you'll pay more for AI in 2026, and 3 money-saving tips to try Quantization is a form of data compression that uses fewer bits to represent the same value. In the case of TurboQuant, the focus is on what's called the "key-value cache," or, for shorthand, "KV cache," one of the biggest memory hogs of AI. When you type into a chatbot such as Google's Gemini, the AI has to compare what you've typed to a repository of measures that serve as a kind of database. The thing that you type is called the query, and it is matched against data held in memory, called a key, to find a numeric match. Basically, it's a similarity score. The key is then used to retrieve from memory exactly which words should be returned to you as the AI's response, known as the value. Normally, every time you type, the AI model must calculate a new key and value, which can slow the whole operation. To speed things up, the machine retains a key-value cache in memory to store recently used keys and values. The cache then becomes its own problem: The more you work with a model, the more memory the key-value cache takes up. "This scaling is a significant bottleneck in terms of memory usage and computational speed, especially for long context models," according to Google lead author Amir Zandieh and colleagues. Also: AI isn't getting smarter, it's getting more power hungry - and expensive Making things worse, AI models are increasingly being built with more complex keys and values, known as the context window. That gives the model more search options, potentially improving accuracy. Gemini 3, the current version, made a big leap in context window to one million tokens. Prior state-of-the-art models such as OpenAI's GPT-4 had a context window of just 32,768 tokens. A larger context window also increases the amount of memory a key-value cache consumes. The solution to that expanding KV cache is to quantize the keys and the values so the whole thing takes up less space. Zandieh and team claim in their blog post that the data compression is "massive" with TurboQuant. "Reducing the KV cache size without compromising accuracy is essential," they write. Quantization has been used by Google and others for years to slim down neural networks. What's novel about TurboQuant is that it's meant to quantize in real time. Previous compression approaches reduced the size of a neural network at compile time, before it is run in production. Also: Nvidia wants to own your AI data center from end to end That's not good enough, observed Zandieh. The KV cache is a living digest of what's learned at "inference time," when people are typing to an AI bot, and the keys and values are changing. So, quantization has to happen fast enough and accurately enough to keep the cache small while also staying up to date. The "turbo" in TurboQuant implies this is a lot faster than traditional compile-time quantization. TurboQuant has two stages. First, the queries and keys are compressed. This can be done geometrically because queries and keys are vectors of data that can be depicted on an X-Y graph as a line, which can be rotated on that graph. They call the rotations "PolarQuant." By randomly trying different rotations with PolarQuant and then retrieving the original line, they find a smaller number of bits that still preserves accuracy. As they put it, "PolarQuant acts as a high-efficiency compression bridge, converting Cartesian inputs into a compact Polar 'shorthand' for storage and processing." The compressed vectors still produce errors when the comparison is performed between the query and the key, which is known as the "inner product" of two vectors. To fix that, they use a second method, QJL, introduced by Zandieh in 2024. That approach keeps one of the two vectors in its original state, so that multiplying a compressed (quantized) vector with an uncompressed vector serves as a test to improve the accuracy of the multiplication. They tested TurboQuant by applying it to Meta Platforms's open-source Llama 3.1-8B AI model, and found that "TurboQuant achieves perfect downstream results across all benchmarks while reducing the key value memory size by a factor of at least 6x" -- a six-fold reduction in the amount of KV cache needed. The approach also differs from other methods for compressing the KV cache, such as the approach taken last year by DeepSeek, which constrained key and value searches to speed up inference. Also: DeepSeek claims its new AI model can cut the cost of predictions by 75% - here's how In another test, using Google's Gemma open-source model and models from French AI startup Mistral, "TurboQuant proved it can quantize the key-value cache to just 3 bits without requiring training or fine-tuning and causing any compromise in model accuracy," they wrote, "all while achieving a faster runtime than the original LLMs (Gemma and Mistral)." "It is exceptionally efficient to implement and incurs negligible runtime overhead," they observed Zandieh and team expect TurboQuant to have a significant impact on the production use of AI inference. "As AI becomes more integrated into all products, from LLMs to semantic search, this work in fundamental vector quantization will be more critical than ever," they wrote. Also: Want to try OpenClaw? NanoClaw is a simpler, potentially safer AI agent But will it really reduce the cost of AI? Yes and no. In an age of agentic AI, programs such as OpenClaw software that operate autonomously, there are a lot of parts to AI besides just the KV cache. Other uses of memory, such as retrieving and storing database records, will ultimately affect an agent's efficiency over the long term. Those who follow the AI chip world last week argued that just as DeepSeek AI's efficiency didn't slow AI investment last year, neither will TurboQuant. Vivek Arya, a Merrill Lynch banker who follows AI chips, wrote to his clients who were worried about DRAM maker Micron Technology that TurboQuant will simply make more efficient use of AI. The "6x improvement in memory efficiency [will] likely [lead] to 6x increase in accuracy (model size) and/or context length (KV cache allocation), rather than 6x decrease in memory," wrote Arya. Also: AI agents of chaos? New research shows how bots talking to bots can go sideways fast What TurboQuant can do, though, is make some individual instances of AI more economical, especially for local deployment. For example, a swelling KV cache and longer context windows may prove less of a burden when running some AI models on limited hardware budgets. That will be a relief for users of OpenClaw who want their MacBook Neo or Mac mini to serve as a budget local AI server.
[4]
Google's TurboQuant reduces AI LLM cache memory capacity requirements by at least six times -- up to 8x performance boost on Nvidia H100 GPUs, compresses KV caches to 3 bits with no accuracy loss
The algorithm achieves up to an eight-times performance boost over unquantized keys on Nvidia H100 GPUs. Google Research published TurboQuant on Tuesday, a training-free compression algorithm that quantizes LLM KV caches down to 3 bits without any loss in model accuracy. In benchmarks on Nvidia H100 GPUs, 4-bit TurboQuant delivered up to an eight-times performance increase in computing attention logits compared to unquantized 32-bit keys, while reducing KV cache memory by at least six times. KV caches store previously computed attention data so that LLMs don't have to recompute it at each token generation step. These caches are becoming major memory bottlenecks as context windows grow larger, and while traditional vector quantization methods can reduce the size of these caches, they introduce a small memory overhead of a few extra bits per value from the quantization constants that must be stored alongside the compressed data. That sounds small, but they're compounding alongside larger context windows. TurboQuant eliminates that overhead via a two-stage process. The first uses a technique called PolarQuant, which converts data vectors from standard Cartesian coordinates into polar coordinates. This separates each vector into a radius (representing magnitude) and a set of angles (representing direction). Because the angular distributions are predictable and concentrated, PolarQuant skips the expensive per-block normalization step that conventional quantizers require. This leads to high-quality compression with zero overhead from stored quantization constants. The second stage applies a 1-bit error correction layer using an algorithm called Quantized Johnson-Lindenstrauss (QJL). QJL projects the residual quantization error into a lower-dimensional space and reduces each value to a single sign bit, eliminating systematic bias in attention score calculations at negligible additional cost. Google tested all three algorithms across long-context benchmarks, including LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval, using open-source models Gemma and Mistral. TurboQuant achieved perfect downstream scores on needle-in-a-haystack retrieval tasks while compressing KV memory by at least six times. On the LongBench suite, which covers question answering, code generation, and summarization, TurboQuant matched or outperformed the KIVI baseline across all tasks. The algorithm also showed strong results in vector search. Evaluated against Product Quantization and RabbiQ on the GloVe dataset, TurboQuant achieved the highest 1@k recall ratios despite those baselines relying on larger codebooks and dataset-specific tuning. Google noted that TurboQuant requires no training or fine-tuning and incurs negligible runtime overhead, making it suitable for deployment in production inference and large-scale vector search systems. The paper, co-authored by research scientist Amir Zandieh and VP Vahab Mirrokni, will be presented at ICLR 2026 next month. Follow Tom's Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.
[5]
TurboQuant is a big deal, but it won't end the memory crunch
Chocolate Factory's compression tech clears the way to cheaper AI inference, not more affordable memory When Google unveiled TurboQuant, an AI data compression technology that promises to slash the amount of memory required to serve models, many hoped it would help with a memory shortage that has seen prices triple since last year. Not so much. TurboQuant isn't the savior you might be hoping for. Having said that, the underlying technology is still worth a closer look as it has major implications for model devs and inference providers. Detailed by Google researchers in a recent blog post, TurboQuant is essentially a method of compressing data used in generative AI from higher to lower precisions, an approach commonly referred to as quantization. According to researchers, TurboQuant has the potential to cut memory consumption during inference by at least 6x, a bold claim at a time when DRAM and NAND prices are at record highs. However, unlike most quantization methods, TurboQuant doesn't shrink the model. Instead it aims to reduce the amount of memory required to store the key value (KV) caches used to maintain context during LLM inference. In a nutshell, the KV cache is a bit like the model's short-term memory. During a chat session, for example, the KV cache is how the model keeps track of your conversation. Where things get tricky is that these KV caches can pile up quite quickly, often consuming more memory than the model itself. Usually, these KV caches are stored at 16-bit precision, so if you can shrink the number of bits used to store them to eight or even four bits, you can reduce the memory required by a factor of 2x to 4x. While TurboQuant has certainly brought attention to KV cache quantization, the overarching idea isn't new. In fact, it's quite common for inference engines to store KV caches at FP8 for these reasons. However, this kind of quantization isn't free. Lower precision means fewer bits to store key values and therefore less memory. These quantization methods also tend to introduce their own performance overheads. This is really where TurboQuant's innovations lie. Google claims that it can achieve quality similar to BF16 using just 3.5 bits, while also mitigating those pesky overheads. At 4 bits, they claim as much as an 8x speedup on H100s when computing attention logits used to decide what in the context is or isn't important to the request. And the researchers didn't stop there. In testing, they found they could crush the KV caches to 2.5 bits with minimal quality loss, which is where the claimed 6x memory reduction appears to have come from. TurboQuant is able to achieve this feat by combining two mathematical approaches: Quantized Johnson-Lindenstrauss (QJL) and PolarQuant. PolarQuant works by mapping KV-cache vectors, which are just high-dimensional mathematical expressions of magnitude and direction, onto a circular grid that uses polar rather than Cartesian coordinates. "This is comparable to replacing 'Go 3 blocks east, 4 blocks north' with 'go 5 blocks total at a 37-degree angle,'" Google's blog post explains. Using this approach, the vector's magnitude and direction are now represented by its radius and angle, which the search giant explains eliminates the memory overhead associated with data normalization as each vector now shares a common reference point. In addition to PolarQuant, Google also employs QJL to correct any errors introduced during the first phase and preserve the accuracy of the attention score used by the model to determine what information is or isn't important to serving a request. The result is that these vectors can be stored using a fraction of memory. And this tech isn't limited to KV caches either. According to Google, the technology also has implications for vector databases used by search engines. With a claimed compression ratio of 6:1, it's not surprising that many on Wall Street tied memory makers' downward spirals to the introduction of TurboQuant. But while the tech is likely to make AI inference clusters more efficient and therefore less expensive to operate, it's unlikely to curb demand for the NAND flash and DRAM memory used to store those KV-caches. A year ago, open weights models like DeepSeek R1 offered context windows ranging from 64,000 to 256,000 tokens. Today, it's not uncommon to find open models sporting context windows exceeding one million tokens. TurboQuant could allow an inference provider to make do with less memory, or let them serve up models with larger context windows. With code assistants and agentic frameworks like OpenClaw driving demand for larger context windows, the latter strikes us as the more likely of the two. It seems that the industry watchers at TrendForce would agree. In a report published earlier this week, they predicted that TurboQuant will spark demand for long-context applications that drive demand for more memory rather than curb it. ®
[6]
Google introduces TurboQuant, cutting LLM memory usage by 6x with no accuracy loss
Serving tech enthusiasts for over 25 years. TechSpot means tech analysis and advice you can trust. The big picture: Google has developed three AI compression algorithms - TurboQuant, PolarQuant, and Quantized Johnson-Lindenstrauss - designed to significantly reduce the memory footprint of large language models without degrading performance or output quality. All three use vector quantization, a data optimization technique that could help AI companies reduce hardware costs as memory prices reach record highs. The biggest memory burden for LLMs is the key-value cache, which stores conversational context as users interact with AI chatbots. The cache grows as conversations lengthen, increasing both memory usage and power consumption. TurboQuant addresses this issue by reducing model size with "zero accuracy loss," improving vector search efficiency, and alleviating key-value cache bottlenecks. It achieves this by using PolarQuant, a high-compression method that randomly rotates data vectors to simplify their geometry, making it easier to apply a standard, high-quality quantizer to map large datasets of continuous values. If it performs as advertised, it could significantly boost on-device AI processing on consumer smartphones and laptops by enabling them to retain more context and support longer chatbot conversations. To minimize errors in the output, TurboQuant uses 1 bit of compression to apply the Quantized Johnson-Lindenstrauss algorithm, which acts as a mathematical error-correction mechanism, reducing bias and improving accuracy. The algorithm employs a specialized estimator that balances high-precision queries with low-precision, simplified data to calculate the "attention score," which determines which parts of the input are most relevant and which can be ignored. Google evaluated all three algorithms across a range of standard long-context benchmarks, including LongBench, Needle in a Haystack, ZeroSCROLLS, RULER, and L-Eval, using the open-source Gemma and Mistral LLMs. The results show that TurboQuant achieves strong performance in both dot product distortion and recall while reducing the key-value memory footprint by at least 6×. Google's AI engineers believe the new algorithms can not only reduce the voracious memory demands of multimodal LLMs like Gemini, but also deliver the efficiency and accuracy required for mission-critical applications. However, the benefits of efficient online vector quantization extend beyond addressing the key-value cache bottleneck, enabling improved web search results with minimal memory usage, near-zero latency, and high accuracy. The new AI algorithms offer a ray of hope for the global consumer electronics industry, which has seen input costs rise sharply in recent months due to the AI boom, a trend that has triggered a global memory shortage and pushed DRAM prices to record highs. If TurboQuant delivers on its promise, it could reduce the high-bandwidth memory requirements for AI data centers, potentially helping stabilize consumer electronics prices in the near future.
[7]
Google's TurboQuant compresses AI memory by 6x, rattles chip stocks
Google published a research blog post on Tuesday about a new compression algorithm for AI models. Within hours, memory stocks were falling. Micron dropped 3 per cent, Western Digital lost 4.7 per cent, and SanDisk fell 5.7 per cent, as investors recalculated how much physical memory the AI industry might actually need. The algorithm is called TurboQuant, and it addresses one of the most expensive bottlenecks in running large language models: the key-value cache, a high-speed data store that holds context information so the model does not have to recompute it with every new token it generates. As models process longer inputs, the cache grows rapidly, consuming GPU memory that could otherwise be used to serve more users or run larger models. TurboQuant compresses the cache to just 3 bits per value, down from the standard 16, reducing its memory footprint by at least six times without, according to Google's benchmarks, any measurable loss in accuracy. The paper, which will be presented at ICLR 2026, was authored by Amir Zandieh, a research scientist at Google, and Vahab Mirrokni, a vice president and Google Fellow, along with collaborators at Google DeepMind, KAIST, and New York University. It builds on two earlier papers from the same group: QJL, published at AAAI 2025, and PolarQuant, which will appear at AISTATS 2026. TurboQuant's core innovation is eliminating the overhead that makes most compression techniques less effective than their headline numbers suggest. Traditional quantization methods reduce the size of data vectors but must store additional constants, normalization values that the system needs in order to decompress the data accurately. These constants typically add one or two extra bits per number, partially undoing the compression. TurboQuant avoids this through a two-stage process. The first stage, called PolarQuant, converts data vectors from standard Cartesian coordinates into polar coordinates, separating each vector into a magnitude and a set of angles. Because the angular distributions follow predictable, concentrated patterns, the system can skip the expensive per-block normalization step entirely. The second stage applies QJL, a technique based on the Johnson-Lindenstrauss transform, which reduces the small residual error from the first stage to a single sign bit per dimension. The combined result is a representation that uses most of its compression budget on capturing the original data's meaning and a minimal residual budget on error correction, with no overhead wasted on normalization constants. Google tested TurboQuant across five standard benchmarks for long-context language models, including LongBench, Needle in a Haystack, and ZeroSCROLLS, using open-source models from the Gemma, Mistral, and Llama families. At 3 bits, TurboQuant matched or outperformed KIVI, the current standard baseline for key-value cache quantization, which was published at ICML 2024. On needle-in-a-haystack retrieval tasks, which test whether a model can locate a single piece of information buried in a long passage, TurboQuant achieved perfect scores while compressing the cache by a factor of six. At 4-bit precision, the algorithm delivered up to an eight-times speedup in computing attention on Nvidia H100 GPUs compared to the uncompressed 32-bit baseline. The stock reaction was swift and, in the view of several analysts, disproportionate. Wells Fargo analyst Andrew Rocha noted that TurboQuant directly attacks the cost curve for memory in AI systems. If adopted broadly, he said, it quickly raises the question of how much memory capacity the industry actually needs. But Rocha and others also cautioned that the demand picture for AI memory remains strong, and that compression algorithms have existed for years without fundamentally altering procurement volumes. The concern is not unfounded, however. AI infrastructure spending is growing at extraordinary rates, with Meta alone committing up to $27 billion in a recent deal with Nebius for dedicated compute capacity, and Google, Microsoft, and Amazon collectively planning hundreds of billions in capital expenditure on data centres through 2026. A technology that reduces memory requirements by six times does not reduce spending by six times, because memory is only one component of a data centre's cost. But it changes the ratio, and in an industry spending at this scale, even marginal efficiency gains compound quickly. TurboQuant arrives at a moment when the AI industry is being forced to confront the economics of inference. Training a model is a one-time cost, however enormous. Running it, serving millions of queries per day with acceptable latency and accuracy, is the recurring expense that determines whether AI products are financially viable at scale. The key-value cache is central to this calculation: it is the bottleneck that limits how many concurrent users a single GPU can serve and how long a context window a model can practically support. Compression techniques like TurboQuant are part of a broader push toward making inference cheaper, alongside hardware improvements such as Nvidia's Vera Rubin architecture and Google's own Ironwood TPUs. The question is whether these efficiency gains will reduce the total amount of hardware the industry buys, or whether they will simply enable more ambitious deployments at roughly the same cost. The history of computing suggests the latter: when storage gets cheaper, people store more; when bandwidth increases, applications consume it. For Google, TurboQuant also has a direct commercial application beyond language models. The blog post notes that the algorithm improves vector search, the technology that powers semantic similarity lookups across billions of items. Google tested it against existing methods on the GloVe benchmark dataset and found it achieved superior recall ratios without requiring the large codebooks or dataset-specific tuning that competing approaches demand. This matters because vector search underpins everything from Google Search to YouTube recommendations to advertising targeting, which is to say, it underpins Google's revenue. The paper's contribution is real: a training-free compression method that achieves measurably better results than the existing state of the art, with strong theoretical foundations and practical implementation on production hardware. Whether it reshapes the economics of AI infrastructure or simply becomes one more optimisation absorbed into the industry's insatiable appetite for compute is a question the market will answer over months, not hours.
[8]
This new Google algorithm cuts AI memory use and boosts speed
* Google TurboQuant reduces memory strain while maintaining accuracy across demanding workloads * Vector compression reaches new efficiency levels without additional training requirements * Key-value cache bottlenecks remain central to AI system performance limits Large language models (LLMs) depend heavily on internal memory structures that store intermediate data for rapid reuse during processing. One of the most critical components is the key-value cache, described as a "high-speed digital cheat sheet" that avoids repeated computation. This mechanism improves responsiveness, but it also creates a major bottleneck because high-dimensional vectors consume substantial memory resources. Memory bottlenecks and scaling pressure As models scale, this memory demand becomes increasingly difficult to manage without compromising speed or accessibility in modern LLM deployments. Traditional approaches attempt to reduce this burden through quantization, a method that compresses numerical precision. However, these techniques often introduce trade-offs, particularly reduced output quality or additional memory overhead from stored constants. This tension between efficiency and accuracy remains unresolved in many existing systems that rely on AI tools for large-scale processing. Google's TurboQuant introduces a two-stage process intended to address these long-standing limitations. The first stage relies on PolarQuant, which transforms vectors from standard Cartesian coordinates into polar representations. Instead of storing multiple directional components, the system condenses information into radius and angle values, creating a compact shorthand, reducing the need for repeated normalization steps and limits the overhead that typically accompanies conventional quantization methods. The second stage applies Quantized Johnson-Lindenstrauss, or QJL, which functions as a corrective layer. While PolarQuant handles most of the compression, it can leave small residual errors, as QJL reduces each vector element to a single bit, either positive or negative, while preserving essential relationships between data points. This additional step refines attention scores, which determine how models prioritize information during processing. According to reported testing, TurboQuant achieves efficiency gains across several long-context benchmarks using open models. The system reportedly reduces key-value cache memory usage by a factor of six while maintaining consistent downstream results. It also enables quantization to as little as three bits without requiring retraining, which suggests compatibility with existing model architectures. The reported results also include gains in processing speed, with attention computations running up to eight times faster than standard 32-bit operations on high-end hardware. These results indicate that compression does not necessarily degrade performance under controlled conditions, although such outcomes depend on benchmark design and evaluation scope. This system could also lower operation costs by reducing memory demands, while making it easier to deploy models on constrained devices where processing resources remain limited. At the same time, freed resources may instead be redirected toward running more complex models, rather than reducing infrastructure demands. While the reported results appear consistent across multiple tests, they remain tied to specific experimental conditions. The broader impact will depend on real-world implementation, where variability in workloads and architectures may produce different outcomes. Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button! And of course you can also follow TechRadar on TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.
[9]
Google AI compression technology saves data center energy
We have seen the future of AI via Large Language Models. And it's smaller than you think. That much was clear in 2025, when we first saw China's DeepSeek -- a slimmer, lighter LLM that required way less data center energy to do its job and performed surprisingly well on benchmark tests against heftier American AI models. (Ironically, it was built atop an open source U.S. model, Meta's Llama). DeepSeek may have foundered on privacy concerns, but the trend towards smaller and smarter AI isn't going away. The evolution is on display again in TurboQuant, a compression algorithm that Google quietly unveiled this week via a Google Research paper. The paper itself is pretty impenetrable if you're not an AI nerd who talks tokens and high-dimensional vectors. We'll get into a more detailed explanation below. But here's the TL;DR: The TurboQuant algorithm can make LLMs' memory usage six times smaller. What does that mean? Less energy usage, perhaps to the point where running a powerful AI model on your powerful smartphone becomes possible. Less RAM usage, right on time for the ongoing RAM shortage. Certainly, algorithms like this can help LLMs make more efficient use of the data centers they're hosted in -- either by using the extra space to run more complex models, or, hear me out, by allowing us not to rush into building so many unpopular new data centers in the first place. And that, paradoxically, could be a problem for the AI economy, at least as it's currently structured. For the past three years, tech stocks have been riding ever higher on the back of one company alone: NVIDIA. And NVIDIA has been riding ever higher on the assumption that we're in the middle of what CEO Jensen Huang called this month "the largest infrastructure buildout in history" -- an explosion of data centers, for which NVIDIA will be the chief provider of chips. But that infrastructure build-out, if you look at data centers actually built versus data centers promised, is already stumbling, as a fresh New York Times investigation just made clear. What's the holdup? Not just opposition from concerned citizens across the U.S., now including the NAACP. It's also permits, applications, inspections, and the other unsexy but often necessary parts of the local government machinery. Not least of the problems: A dearth of power generation and transmission, which doesn't sit well with the AI industry's unquantifiable ability to soak up electricity and suck up water. What happens when the desire for more AI runs into a lack of infrastructure? Well, then necessity becomes the mother of invention. We learn to do more with less. And that's exactly what TurboQuant does. Here's that explanation -- although since TurboQuant is a compression algorithm, you'd be forgiven for imagining Google had the same NSFW "middle out" compression algorithm inspiration that drove the plot of the HBO comedy Silicon Valley. So there's a couple of energy "bottlenecks" when AI models reach for something they really want and frequently use. One is called the key-value cache, which is like a really hot library that stores the most-used information. The other is the vector search, which matches things that look the same. TurboQuant effectively lubricates both at once, making memory grabs faster, smoother, and less fraught. TurboQuant "helps unclog key-value cache bottlenecks by reducing the size of key-value pairs," Google's paper says, in part by the "clever" move of "randomly rotating the data vectors." Got that? No? Well, it doesn't really matter. All you need to know is that there's a promising new field of extremely complex computational mathematics, and it works the way compression algorithms have long worked -- making new technology faster, lighter, easier to run. First, it was ZIP file downloads, then the video compression that enabled the streaming revolution, and now it's AI. The result could allow a more powerful LLM to run entirely on your phone, or it could crash the global economy, or both at the same time. Isn't life in 2026 wild?
[10]
Google's new TurboQuant algorithm speeds up AI memory 8x, cutting costs by 50% or more
As Large Language Models (LLMs) expand their context windows to process massive documents and intricate conversations, they encounter a brutal hardware reality known as the "Key-Value (KV) cache bottleneck." Every word a model processes must be stored as a high-dimensional vector in high-speed memory. For long-form tasks, this "digital cheat sheet" swells rapidly, devouring the graphics processing unit (GPU) video random access memory (VRAM) system used during inference, and slowing the model performance down rapidly over time. But have no fear, Google Research is here: yesterday, the unit within the search giant released its TurboQuant algorithm suite -- a software-only breakthrough that provides the mathematical blueprint for extreme KV cache compression, enabling a 6x reduction on average in the amount of KV memory a given model uses, and 8x performance increase in computing attention logits, which could reduce costs for enterprises that implement it on their models by more than 50%. The theoretically grounded algorithms and associated research papers are available now publicly for free, including for enterprise usage, offering a training-free solution to reduce model size without sacrificing intelligence. The arrival of TurboQuant is the culmination of a multi-year research arc that began in 2024. While the underlying mathematical frameworks -- including PolarQuant and Quantized Johnson-Lindenstrauss (QJL) -- were documented in early 2025, their formal unveiling today marks a transition from academic theory to large-scale production reality. The timing is strategic, coinciding with the upcoming presentations of these findings at the upcoming conferences International Conference on Learning Representations (ICLR 2026) in Rio de Janeiro, Brazil, and Annual Conference on Artificial Intelligence and Statistics (AISTATS 2026) in Tangier, Morocco. By releasing these methodologies under an open research framework, Google is providing the essential "plumbing" for the burgeoning "Agentic AI" era: the need for massive, efficient, and searchable vectorized memory that can finally run on the hardware users already own. Already, it is believed to have an effect on the stock market, lowering the price of memory providers as traders look to the release as a sign that less memory will be needed (perhaps incorrect, given Jevons' Paradox). To understand why TurboQuant matters, one must first understand the "memory tax" of modern AI. Traditional vector quantization has historically been a "leaky" process. When high-precision decimals are compressed into simple integers, the resulting "quantization error" accumulates, eventually causing models to hallucinate or lose semantic coherence. Furthermore, most existing methods require "quantization constants" -- meta-data stored alongside the compressed bits to tell the model how to decompress them. In many cases, these constants add so much overhead -- sometimes 1 to 2 bits per number -- that they negate the gains of compression entirely. TurboQuant resolves this paradox through a two-stage mathematical shield. The first stage utilizes PolarQuant, which reimagines how we map high-dimensional space. Rather than using standard Cartesian coordinates (X, Y, Z), PolarQuant converts vectors into polar coordinates consisting of a radius and a set of angles. The breakthrough lies in the geometry: after a random rotation, the distribution of these angles becomes highly predictable and concentrated. Because the "shape" of the data is now known, the system no longer needs to store expensive normalization constants for every data block. It simply maps the data onto a fixed, circular grid, eliminating the overhead that traditional methods must carry. The second stage acts as a mathematical error-checker. Even with the efficiency of PolarQuant, a residual amount of error remains. TurboQuant applies a 1-bit Quantized Johnson-Lindenstrauss (QJL) transform to this leftover data. By reducing each error number to a simple sign bit (+1 or -1), QJL serves as a zero-bias estimator. This ensures that when the model calculates an "attention score" -- the vital process of deciding which words in a prompt are most relevant -- the compressed version remains statistically identical to the high-precision original. The true test of any compression algorithm is the "Needle-in-a-Haystack" benchmark, which evaluates whether an AI can find a single specific sentence hidden within 100,000 words. In testing across open-source models like Llama-3.1-8B and Mistral-7B, TurboQuant achieved perfect recall scores, mirroring the performance of uncompressed models while reducing the KV cache memory footprint by a factor of at least 6x. This "quality neutrality" is rare in the world of extreme quantization, where 3-bit systems usually suffer from significant logic degradation. Beyond chatbots, TurboQuant is transformative for high-dimensional search. Modern search engines increasingly rely on "semantic search," comparing the meanings of billions of vectors rather than just matching keywords. TurboQuant consistently achieves superior recall ratios compared to existing state-of-the-art methods like RabbiQ and Product Quantization (PQ), all while requiring virtually zero indexing time. This makes it an ideal candidate for real-time applications where data is constantly being added to a database and must be searchable immediately. Furthermore, on hardware like NVIDIA H100 accelerators, TurboQuant's 4-bit implementation achieved an 8x performance boost in computing attention logs, a critical speedup for real-world deployments. The reaction on X, obtained via a Grok search, included a mixture of technical awe and immediate practical experimentation. The original announcement from @GoogleResearch generated massive engagement, with over 7.7 million views, signaling that the industry was hungry for a solution to the memory crisis. Within 24 hours of the release, community members began porting the algorithm to popular local AI libraries like MLX for Apple Silicon and llama.cpp. Technical analyst @Prince_Canuma shared one of the most compelling early benchmarks, implementing TurboQuant in MLX to test the Qwen3.5-35B model. Across context lengths ranging from 8.5K to 64K tokens, he reported a 100% exact match at every quantization level, noting that 2.5-bit TurboQuant reduced the KV cache by nearly 5x with zero accuracy loss. This real-world validation echoed Google's internal research, proving that the algorithm's benefits translate seamlessly to third-party models. Other users focused on the democratization of high-performance AI. @NoahEpstein_ provided a plain-English breakdown, arguing that TurboQuant significantly narrows the gap between free local AI and expensive cloud subscriptions. He noted that models running locally on consumer hardware like a Mac Mini "just got dramatically better," enabling 100,000-token conversations without the typical quality degradation. Similarly, @PrajwalTomar_ highlighted the security and speed benefits of running "insane AI models locally for free," expressing "huge respect" for Google's decision to share the research rather than keeping it proprietary. The release of TurboQuant has already begun to ripple through the broader tech economy. Following the announcement on Tuesday, analysts observed a downward trend in the stock prices of major memory suppliers, including Micron and Western Digital. The market's reaction reflects a realization that if AI giants can compress their memory requirements by a factor of six through software alone, the insatiable demand for High Bandwidth Memory (HBM) may be tempered by algorithmic efficiency. As we move deeper into 2026, the arrival of TurboQuant suggests that the next era of AI progress will be defined as much by mathematical elegance as by brute force. By redefining efficiency through extreme compression, Google is enabling "smarter memory movement" for multi-step agents and dense retrieval pipelines. The industry is shifting from a focus on "bigger models" to "better memory," a change that could lower AI serving costs globally. For enterprises currently using or fine-tuning their own AI models, the release of TurboQuant offers a rare opportunity for immediate operational improvement. Unlike many AI breakthroughs that require costly retraining or specialized datasets, TurboQuant is training-free and data-oblivious. This means organizations can apply these quantization techniques to their existing fine-tuned models -- whether they are based on Llama, Mistral, or Google's own Gemma -- to realize immediate memory savings and speedups without risking the specialized performance they have worked to build. From a practical standpoint, enterprise IT and DevOps teams should consider the following steps to integrate this research into their operations: Optimize Inference Pipelines: Integrating TurboQuant into production inference servers can reduce the number of GPUs required to serve long-context applications, potentially slashing cloud compute costs by 50% or more. Expand Context Capabilities: Enterprises working with massive internal documentation can now offer much longer context windows for retrieval-augmented generation (RAG) tasks without the massive VRAM overhead that previously made such features cost-prohibitive. Enhance Local Deployments: For organizations with strict data privacy requirements, TurboQuant makes it feasible to run highly capable, large-scale models on on-premise hardware or edge devices that were previously insufficient for 32-bit or even 8-bit model weights. Re-evaluate Hardware Procurement: Before investing in massive HBM-heavy GPU clusters, operations leaders should assess how much of their bottleneck can be resolved through these software-driven efficiency gains. Ultimately, TurboQuant proves that the limit of AI isn't just how many transistors we can cram onto a chip, but how elegantly we can translate the infinite complexity of information into the finite space of a digital bit. For the enterprise, this is more than just a research paper; it is a tactical unlock that turns existing hardware into a significantly more powerful asset.
[11]
Google Shrinks AI Memory With No Accuracy Loss -- But There's a Catch - Decrypt
The method compresses inference memory, not model weights, and has only been tested in research benchmarks. Google Research published TurboQuant on Wednesday, a compression algorithm that shrinks a major inference-memory bottleneck by at least 6x while maintaining zero loss in accuracy. The paper is slated for presentation at ICLR 2026, and the reaction online was immediate. Cloudflare CEO Matthew Prince called it Google's DeepSeek moment. Memory stock prices, including Micron, Western Digital, and Seagate, fell on the same day. Quantization efficiency is a big achievement by itself. But "zero accuracy loss" needs context. TurboQuant targets the KV cache -- the chunk of GPU memory that stores everything a language model needs to remember during a conversation. As context windows grow toward millions of tokens, those caches balloon into hundreds of gigabytes per session. That's the actual bottleneck. Not compute power but raw memory. Traditional compression methods try to shrink those caches by rounding numbers down -- from 32-bit floats to 16, to 8 to 4-bit integers, for example. To better understand it, think of shrinking an image from 4K, to full HD, to 720p and so. It's easy to tell it's the same image overall, but there's more detail in 4K resolution. The catch: they have to store extra "quantization constants" alongside the compressed data to keep the model from going stupid. Those constants add 1 to 2 bits per value, partially eroding the gains. TurboQuant claims it eliminates that overhead entirely. It does this via two sub-algorithms. PolarQuant separates magnitude from direction in vectors, and QJL (Quantized Johnson-Lindenstrauss) takes the tiny residual error left over and reduces it to a single sign bit, positive or negative, with zero stored constants. The result, Google says, is a mathematically unbiased estimator for the attention calculations that drive transformer models. In benchmarks using Gemma and Mistral, TurboQuant matched full-precision performance under 4x compression, including perfect retrieval accuracy on needle-in-haystack tasks up to 104,000 tokens. For context on why those benchmarks matter, expanding a model's usable context without quality loss has been one of the hardest problems in LLM deployment. Now, the fine print. "Zero accuracy loss" applies to KV cache compression during inference -- not to the model's weights. Compressing weights is a completely different, harder problem. TurboQuant doesn't touch those. What it compresses is the temporary memory storing mid-session attention computations, which is more forgiving because that data can theoretically be reconstructed. There's also the gap between a clean benchmark and a production system serving billions of requests. TurboQuant was tested on open-source models -- Gemma, Mistral, Llama -- not Google's own Gemini stack at scale. Unlike DeepSeek's efficiency gains, which required deep architectural decisions baked in from the start, TurboQuant requires no retraining or fine-tuning and claims negligible runtime overhead. In theory, it drops straight into existing inference pipelines. That's the part that spooked the memory hardware sector -- because if it works in production, every major AI lab runs leaner on the same GPUs they already own. The paper goes to ICLR 2026. Until it ships in production, the "zero loss" headline stays in the lab.
[12]
Google develops TurboQuant compression technology for AI models - SiliconANGLE
Google develops TurboQuant compression technology for AI models Google LLC has unveiled a technology called TurboQuant that can speed up artificial intelligence models and lower their memory requirements. Amir Zandieh and Vahab Mirrokni, two of the researchers who worked on the project, explained how it works in a Tuesday blog post. One way to speed up AI models is to reduce the amount of data they must process to make decisions. That can be achieved by compressing the input data that a model ingests. There are many algorithms that can compress AI models' input data, but they often provide only limited efficiency improvements. Additionally, they can introduce errors into the data they compress, which lowers AI models' output quality. According to Google, TurboQuant can not only compress AI models' data more efficiently than existing algorithms but also do so with fewer errors. It does so by changing the data's mathematical properties. AI models represent the data they process in the form of vectors. A vector is a geometric object that is often visualized as a simple two-dimensional line. The line has two main properties: length and direction. An arrow indicates the direction of the line. In practice, advanced AI models store data using not simple two-dimensional lines but so-called high-dimensional vectors. What sets such vectors apart from a simple line is that they point in up to thousands of different directions rather than just one. A high-dimensional vector can store a piece of data such as a sentence or an equation. The fact that vectors have a direction means that they can be rotated in an abstract sense of the word. TurboQuant harnesses that property to optimize AI models' data. According to Google, it uses an approach called random preconditioning to rotate an AI model's vectors in a way that makes them easier to compress. It then compresses them with an algorithm called a quantizer. The primary benefit of rotating vectors is that it shields them from data errors during the compression process. However, a small number of errors still find their way into the vectors. TurboQuant fixes those inaccuracies using an algorithm called QJL. "QJL uses a mathematical technique called the Johnson-Lindenstrauss Transform to shrink complex, high-dimensional data while preserving the essential distances and relationships between data points," Zandieh and Mirrokni explained. "This algorithm essentially creates a high-speed shorthand that requires zero memory overhead."
[13]
Google Launches TurboQuant to Make AI Models More Efficient Without Losing Accuracy
TurboQuant focuses on compressing the key-value (KV) cache, a critical component in modern AI systems that stores previously processed information. Google has introduced a new compression framework this week that could dramatically reshape how artificial intelligence systems consume memory during inference. The system, called TurboQuant, is designed to shrink the memory footprint of large language models by more than six times while maintaining full output accuracy. The development signals a shift in how AI performance is optimized, moving beyond raw compute scaling toward smarter data representation.
[14]
Google's TurboQuant explained: The JPEG approach to AI compression
How do you try to make sense of Google's TurboQuant tech, especially if you're not a cutting-edge tech pro? The tech behind what Google's trying to do seems so impactful, but what good is it if it doesn't make sense, right? Connecting it to tech powering images and pictures we see on a daily basis seems like a good place to start. Also read: OpenAI discontinuing Sora AI video: What went wrong for ChatGPT maker? Think about what happens when you save a photo as a JPEG. The file trims away details that your eyes won't notice anyway. Tiny variations in color, subtle textures, things that don't really change how the image looks to you. The result still looks the same to you, but the file size drops massively. The real trick isn't what it keeps, it's knowing what it can safely throw away. That's what TurboQuant also does on a very different scale. When an AI model processes a long conversation or a large document, it stores everything in its working memory as a huge grid of numbers. These numbers are extremely precise, and that precision comes at a cost. More memory means more computing power, more energy, and ultimately higher costs. Also read: Best smartwatches with WhatsApp calling and messaging in 2026 What TurboQuant does is surprisingly simple in concept. It asks the same question as JPEGs, how much of this detail actually matters? Instead of keeping everything at high precision, it compresses those numbers. We're talking about shrinking them from 32-bit precision down to just 3 or 4 bits. Which, when you say it out loud, sounds like a huge loss that could break everything. However, there is nuance to it. It adds a tiny correction layer, just one extra bit, to fix any important errors that might creep in. The result is kind of wild. Memory usage drops by up to six times. Processing becomes significantly faster. And somehow, the model still performs almost exactly the same. What I find most interesting isn't just the efficiency gains. It's how familiar the idea feels. This isn't some completely alien breakthrough. It's a principle we've been using for decades. JPEG did it for images back in the early 90s. TurboQuant is doing it for AI today. Progress in tech doesn't always come from adding more. Oftentimes, it comes from knowing what you can afford to lose.
Share
Copy Link
Google Research introduced TurboQuant, a compression algorithm that reduces large language model memory requirements by at least 6x without sacrificing accuracy. The breakthrough targets the key-value cache bottleneck, delivering up to 8x faster performance on Nvidia H100 GPUs while compressing data to just 3 bits. But experts warn it won't solve the broader memory shortage.
Google Research Tackles AI's Memory Problem with TurboQuant
Google Research has unveiled TurboQuant, an AI memory compression algorithm designed to address one of the most pressing challenges in artificial intelligence: escalating memory demands
1
. The breakthrough technology can reduce memory usage by at least 6x while maintaining model accuracy, a development that some industry observers are calling Google's DeepSeek moment2
. The algorithm specifically targets the KV cache, a memory-intensive component that stores previously computed attention data in large language models (LLMs) to avoid redundant calculations during token generation4
.
Source: Digit
The KV cache functions like a "digital cheat sheet" that grows larger as context windows expand, creating a significant memory bottleneck
1
. As AI models increasingly adopt context windows exceeding one million tokens—compared to earlier models like GPT-4 with just 32,768 tokens—this cache can consume more memory than the models themselves3
. TurboQuant compresses KV caches down to 3 bits with no accuracy loss, a dramatic reduction from the standard 16-bit precision typically used4
.
Source: TechSpot
How PolarQuant and QJL Enable Massive Compression
TurboQuant achieves its compression through a two-stage process combining PolarQuant and Quantized Johnson-Lindenstrauss (QJL) techniques
2
. PolarQuant converts vectors from standard Cartesian coordinates into polar coordinates, separating each vector into a radius representing magnitude and angles representing direction4
. Google Research uses an analogy to explain this: instead of saying "Go 3 blocks East, 4 blocks North," the system simply says "Go 5 blocks at 37-degrees"1
.This transformation eliminates the expensive data normalization steps required by conventional quantization methods, as each vector now shares a common reference point
5
. The second stage applies QJL, a 1-bit error-correction layer that projects residual quantization errors into a lower-dimensional space, reducing each value to a single sign bit4
. This eliminates systematic bias in attention score calculations—the fundamental process by which neural networks decide what data is important—at negligible additional cost1
.Impressive Performance Boost on Nvidia H100 GPUs
Beyond compression, TurboQuant delivers a substantial performance boost. Computing attention scores with 4-bit TurboQuant is up to 8x faster compared to 32-bit unquantized keys on Nvidia H100 accelerators
1
. The algorithm requires no additional training and can be applied to existing AI models, making deployment straightforward1
. Google tested the compression across long-context benchmarks including LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval using open-source models Gemma and Mistral4
.TurboQuant achieved perfect downstream scores on needle-in-a-haystack retrieval tasks while reducing memory by at least 6x
4
. The research team, led by Amir Zandieh and VP Vahab Mirrokni, will present their findings at ICLR 2026 next month4
. The technology also shows promise for vector search applications, achieving the highest 1@k recall ratios against baselines like Product Quantization and RabbiQ on the GloVe dataset4
.Related Stories

Reality Check: Won't Solve the Memory Shortage
While TurboQuant represents a significant technical achievement, experts caution it won't resolve the broader memory crisis that has seen DRAM and NAND prices triple since last year
5
. The algorithm only targets AI inference memory, not the massive amounts of RAM required for training models2
. Moreover, the technology faces the Jevons paradox: making something more efficient often increases overall usage of that resource rather than reducing it3
.
Source: The Register
TrendForce predicts that TurboQuant will actually spark demand for long-context applications that drive demand for more memory rather than curb it
5
. Inference providers could use the freed-up capacity to serve models with larger context windows instead of reducing hardware requirements5
. Still, the technology could make AI inference cheaper to run and particularly benefit mobile AI, where hardware limitations of smartphones currently restrict on-device model quality . The compression could enable more sophisticated AI capabilities without sending user data to the cloud, addressing both performance and privacy concerns1
.References
Summarized by
Navi
[5]
Related Stories
Google's TurboQuant sparked memory market panic, but analysts say AI demand will surge higher
12 Apr 2026•Business and Economy

Google's TurboQuant slashes AI memory needs by 6x, sending memory chip stocks tumbling
26 Mar 2026•Technology
DeepSeek's Engram tackles AI compute waste with conditional memory breakthrough
13 Jan 2026•Technology

Recent Highlights


Recent Highlights
Today's Top Stories




Don’t drown in AI news. We cut through the noise - filtering, ranking and summarizing the most important AI news, breakthroughs and research daily. Follow topics that matter to you and stay ahead.


